

1.5.1. Lake Victoria’s 2020 Flood Event Analysis#
Production date: 29-08-2025
Produced by: Amaya Camila Trigoso Barrientos (VUB)
🌍 Use case: Detection and quantification of the 2020 Lake Victoria flood event through statistical analysis#
❓ Quality assessment question#
Can the C3S Lake Water Levels dataset be used to conduct extreme value analyses to detect and quantify flood events?
In 2020, Lake Victoria experienced an extreme flood event with significant regional impacts. Accurate definition and characterization of such events are essential for understanding their causes and informing adaptation strategies. This notebook explores whether the Lake water levels from 1992 to present derived from satellite observations (C3S-LWL v5.0) dataset, a freely available and harmonized satellite-derived product, is suitable for defining high-impact flood events through statistical analysis.
Inspired by methodologies such as those applied by Pietroiusti et al. (2024) [1] using the DAHITI dataset, this analysis applies extreme value analysis (EVA) to assess the 2020 flood event. The goal is to evaluate whether C3S-LWL v5.0 can serve as a reliable resource for event definition in impact attribution workflows, particularly in data-scarce regions like the Lake Victoria basin.
📢 Quality assessment statement#
These are the key outcomes of this assessment
The assessment indicates the C3S Lake Water Levels dataset is suitable to detect and characterise flood events, identifying the 2020 Lake Victoria flood event and ranking it as the third-highest 180-day lake level rise in the historical record (1948–2023), with only 1962 and 1998 recording greater increase.
Differences between DAHITI and C3S-LWL v5.0 are more pronounced in the early record (1992–2002), due to limited satellite coverage and distinct processing approaches, but these differences shrink substantially after 2002. In recent years, the two datasets show very close agreement.
📋 Methodology#
First, the C3S LWL and the DAHITI datasets of Lake Victoria’s water levels were compared. Both datasets are based on satellite altimetry but differ in their processing algorithms. We evaluated the two datasets in terms of temporal completeness and analysed the causes of their discrepancies. This comparison was motivated by the fact that DAHITI was used in Pietroiusti et al. (2024) [1] for extreme event attribution (EEA) of the 2020 Lake Victoria flood. Our goal was to assess whether the C3S LWL dataset could serve as a suitable alternative to DAHITI for this type of application. To extend the record, a reconstructed lake level dataset was also built using HYDROMET data, which covers a period prior to satellite-based products. Finally, since lake level data is primarily required during the event definition step of the EEA process, we focused on this first step and tested its implementation using the C3S LWL dataset. The same procedure as on Pietroiusti et al. (2024) [1] was followed for the event definition, which involved the calculation and ranking of the annual block maximum of the chosen variable, which was the rate of change in water levels over a time window.
The analysis and results are organised in the following steps, which are detailed in the sections below:
Download C3S–LWL v5.0 satellite-lake-water-level data for Lake Victoria.
2. Comparison of C3S LWL with the DAHITI dataset
Load and preprocess DAHITI data.
Plot monthly count of data recorded for both the DAHITI and C3S data.
Plot C3S and DAHITI’s Water Level and show the maximum difference.
Load and preprocess HYDROMET data.
Calculate the average difference between HYDROMET and C3S-LWL overlapping data and correct the HYDROMET dataset based on this.
Interpolate to fill missing gaps in HYDROMET.
Plot reconstructed time series.
4. Probabilistic extreme event analysis
Apply the annual block maxima to the reconstructed time series.
Compare with the results from Pietroiusti et al. (2024) [1].
📈 Analysis and results#
1. Data request and download#
Import packages#
Import the packages to download the data using the c3s_eqc_automatic_quality_control library.
Set the data request#
Set the request for the specific lake (Victoria in our case) analyzed and the collection id (satellite lake water level).
Download data#
2. Comparison of C3S LWL with the DAHITI dataset#
Load and preprocess DAHITI data#
This assessment applies the methods developed by Pietroiusti et al. (2024) [1], whose data are openly available via Zenodo. In that study, the DAHITI dataset [2] was employed. Accordingly, a comparison of Lake Victoria’s water level time series from C3S-LWL v5.0 and DAHITI will be carried out. The DAHITI time series for Lake Victoria can be accessed and downloaded from the DAHITI portal.
For reproducibility, the specific DAHITI dataset used in this assessment is located in the Zenodo repository at: lakevic-eea-data-zenodo\lakevic-eea-data-zenodo\lakevic-eea-analysis\lakelevels\DAHITI_lakelevels_070322.csv.
| water_level | error | water_level_m | |
|---|---|---|---|
| datetime | |||
| 1992-09-27 | 1135000 | 0 | 1135.000 |
| 1992-10-07 | 1135023 | 0 | 1135.023 |
| 1992-10-17 | 1135032 | 0 | 1135.032 |
| 1992-10-27 | 1134958 | 0 | 1134.958 |
| 1992-11-06 | 1135035 | 0 | 1135.035 |
| ... | ... | ... | ... |
| 2022-01-22 | 1136143 | 0 | 1136.143 |
| 2022-02-01 | 1136145 | 0 | 1136.145 |
| 2022-02-11 | 1136199 | 0 | 1136.199 |
| 2022-02-21 | 1136227 | 0 | 1136.227 |
| 2022-03-03 | 1136229 | 0 | 1136.229 |
1058 rows × 3 columns
Monthly temporal completeness#
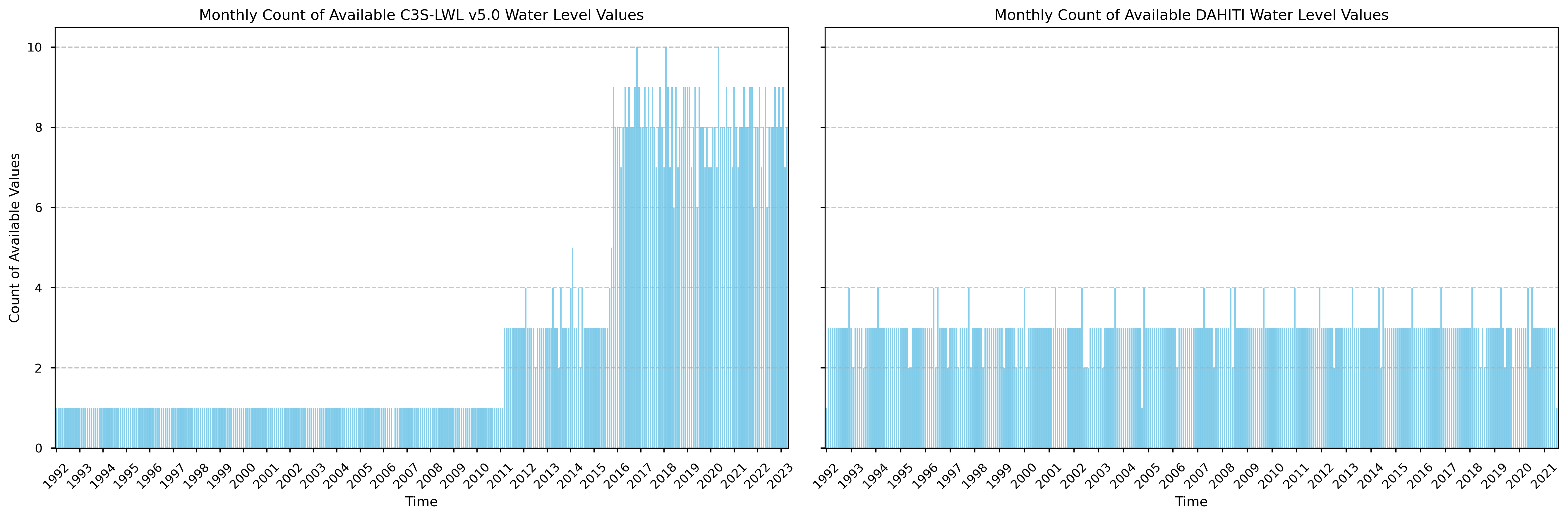
Figure 1. Comparison of count of monthly values over time available in the C3S-LWL v5.0 dataset (on the left) and in DAHITI (on the right).
The DAHITI dataset exhibits a relatively consistent number of monthly observations, typically ranging from 1 to 4 throughout its entire temporal span. In contrast, the C3S-LWL v5.0 dataset shows variability in the number of monthly values, depending on the availability of satellite missions over time. Up until the end of 2010, only one value per month was recorded. From 2011 to 2015, this number increased to mostly three observations per month, likely reflecting additional unfiltered data from the Jason-2 mission. A significant increase in observation frequency is evident from 2016 onward, corresponding to the introduction of Jason-3 and Sentinel-3A satellites. The C3S-LWL v5.0 dataset contains only one gap, in 2006, indicating strong overall temporal completeness.
The differing number of monthly observations between the datasets can be explained by the fact that DAHITI applies interpolation using a Kalman filter, a statistical technique that predicts the water level at the next time step based on previous observations and associated uncertainties [1]. This allows DAHITI to maintain a nearly uniform temporal resolution, achieving approximately three observations per month even during periods with limited satellite overpasses. On the other hand, the C3S-LWL v5.0 dataset does not interpolate. The observations from the different satellite missions are processed in three sequential steps, each applying thresholds and filtering criteria to remove bad-quality data. As a result, only high-quality data are retained in the final dataset. Because older satellite sensors generally had lower accuracy, a larger fraction of early observations is filtered out, whereas later missions contribute more usable data. More in depth information on the processing steps to make the C3S-LWL v5.0 dataset can be found in the Algorithm Theoretical Basis Document (ATBD).
Plot C3S and DAHITI’s Water Level#
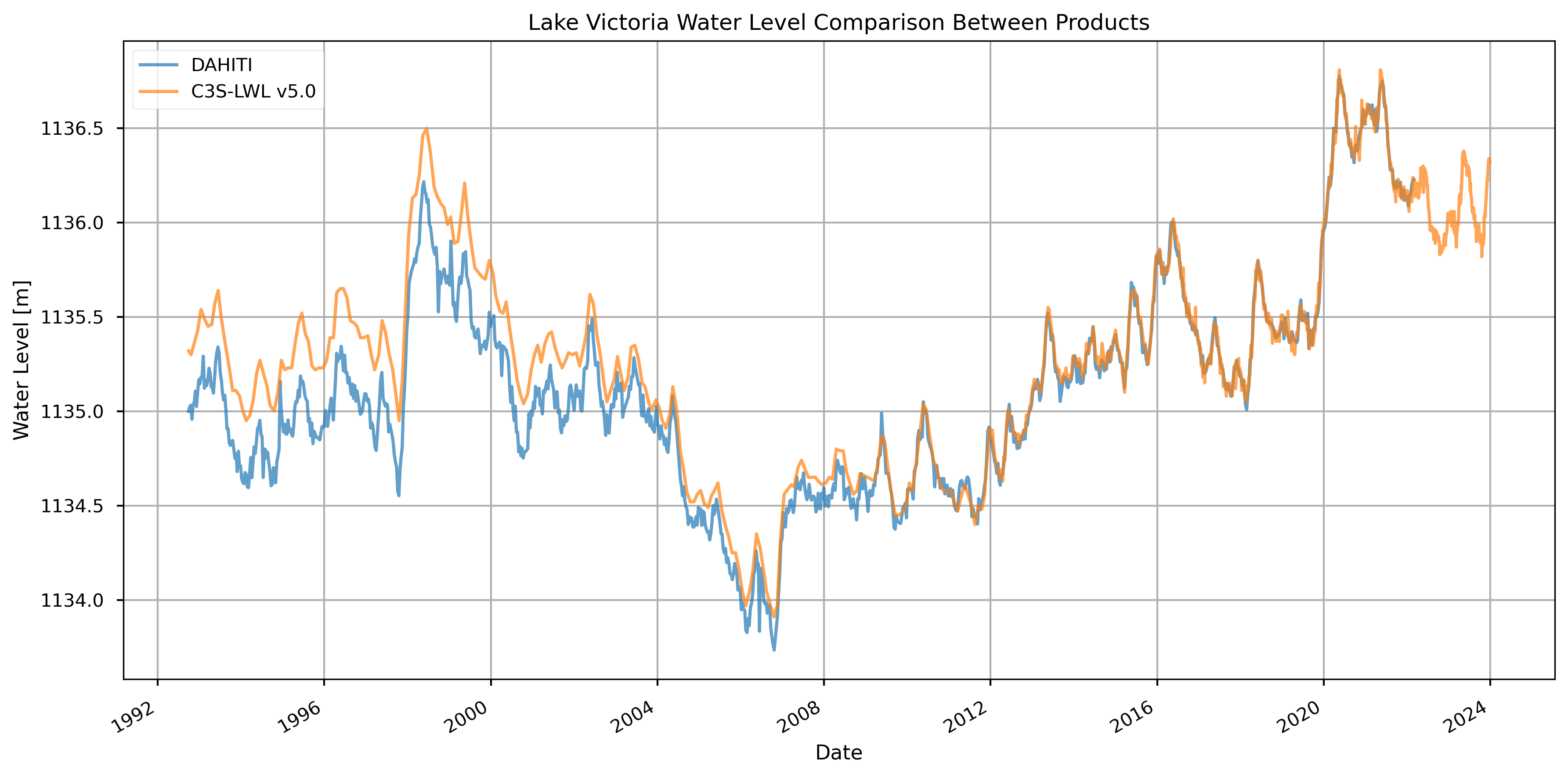
Figure 2. Lake Victoria’s water level from 1992 to present from C3S-LWL v5.0 and DAHITI.
Average difference for 1992-2002 (TOPEX/Poseidon): 0.334 m
Average difference for 2002-2016: 0.043 m
Average difference for 2016-2023: 0.002 m
The difference in water level estimates for Lake Victoria between the DAHITI and C3S-LWL v5.0 datasets varies noticeably over time (see Figure 2). A larger discrepancy is observed during the first decade of the time series (1992-2002), when the only satellite data available originated from the TOPEX/Poseidon mission. During this period, the average difference between the two datasets is 33.2 cm in average, with C3S values consistently higher than those from DAHITI.
This early discrepancy appears to stem from differences in the algorithms and retracking methods used by the two datasets. DAHITI, in some cases, applies an improved 10% threshold retracker for better perfomance on inland water bodies, depending on the specific case. However, specific information on whether the 10% retracker was applied to Lake Victoria could not be confirmed, since available documentation only details its application for lakes in the Americas. Additionally, DAHITI employs a Kalman filter to interpolate and smooth its time series, further influencing the results [2]. In contrast, according to the ATBD, the C3S-LWL v5.0 dataset uses a ocean model retracking for large lakes such as Lake Victoria.
However, this difference diminishes noticeably after 2002 (less than 10 cm in average), as newer satellite missions introduced more frequent and accurate measurements. The influence of processing seems to be much smaller in later years, likely because the improvements in sensor technology and data availability reduce the impact of such methodological differences.
These findings are supported by the PQAR, which includes Lake Victoria under the Southern Africa region. According to the PQAR, the Pearson correlation coefficient between DAHITI and C3S in this region is very close to 1, and the Unbiased Root Mean Square Error (URMSE) remains below 25%, indicating strong overall agreement in this region.
3. Time series reconstruction#
The temporal coverage of the C3S-LWL dataset varies by lake, with a target record length of more than 25 years and a minimum threshold of 10 years. To increase statistical confidence and improve robustness, other available datasets can be merged with C3S-LWL to form a single continuous record.
The code on this section is based on the work of Pietroiusti et al. (2024) [1].
Load and preprocess HYDROMET data#
From January 1, 1948 to August 1, 1996, daily in situ water level measurements at the Jinja station were obtained from the WMO Hydrometeorological Survey (hereafter referred to as HYDROMET) [3]. These measurements, originally recorded as water depth at the lake’s outflow, were later converted to meters above sea level by adding a geoid correction of 1122.887 m, following the approach of Vanderkelen et al. (2018) [4].
The HYDROMET dataset is located in the Zenodo repository at: lakevic-eea-data-zenodo\lakevic-eea-data-zenodo\lakevic-eea-analysis\lakelevels\Jinja_lakelevels_Van.txt.
| water_level | meas | |
|---|---|---|
| date | ||
| 1948-01-01 | 1134.097 | 11.210 |
| 1948-01-02 | 1134.102 | 11.215 |
| 1948-01-03 | 1134.062 | 11.175 |
| 1948-01-04 | 1134.052 | 11.165 |
| 1948-01-05 | 1134.077 | 11.190 |
| ... | ... | ... |
| 1996-07-28 | 1134.777 | 11.890 |
| 1996-07-29 | 1134.757 | 11.870 |
| 1996-07-30 | 1134.752 | 11.865 |
| 1996-07-31 | 1134.717 | 11.830 |
| 1996-08-01 | 1134.747 | 11.860 |
17746 rows × 2 columns
Merging the datasets together#
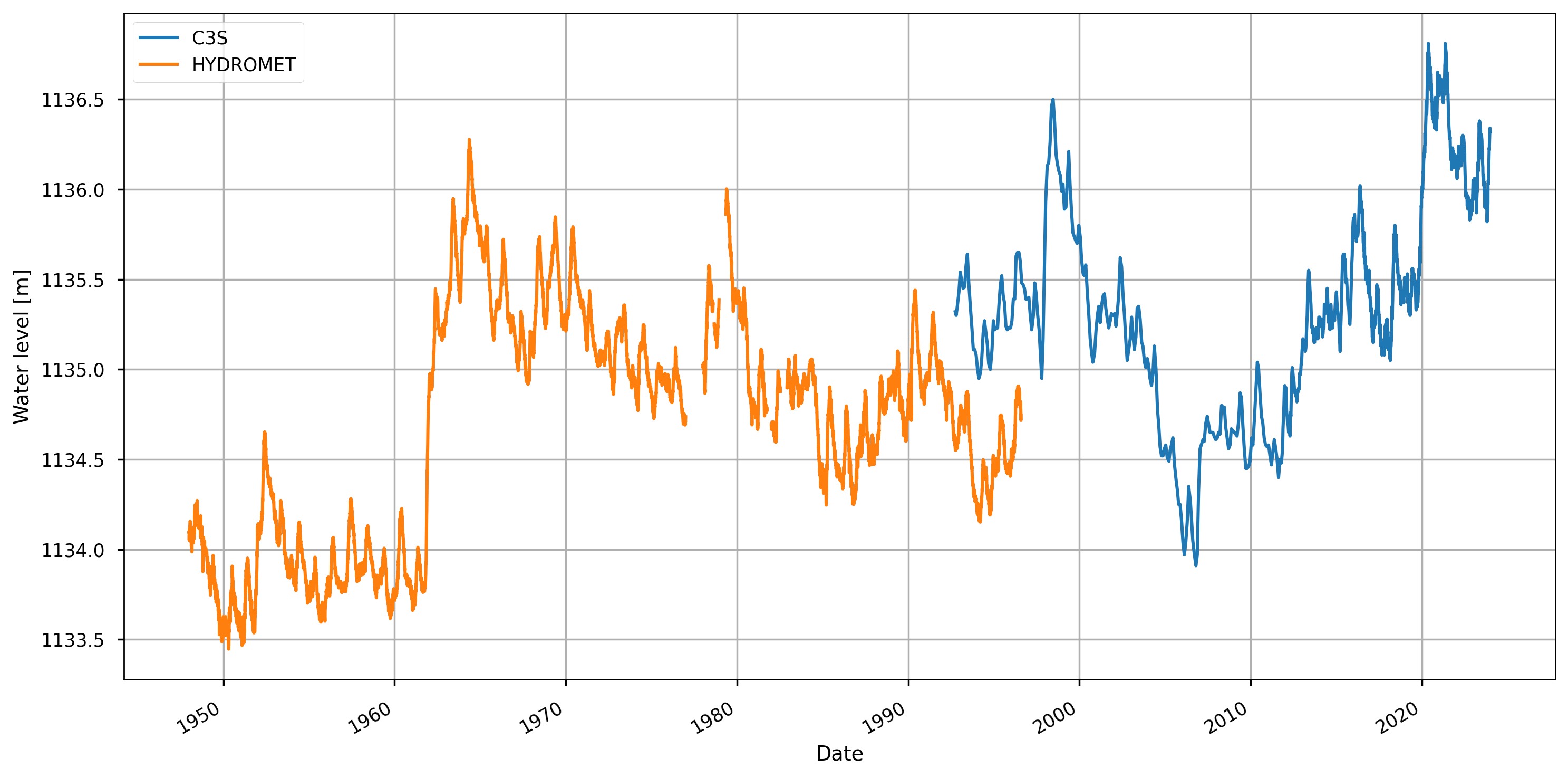
Figure 3. HYDROMET (1948-1996) and C3S (1992-2023) datasets timeseries before correction.
To obtain the reconstructed dataseries of Lake Victoria’s water levels it is necessary to perform a correction to HYDROMET data based on the overlaping period (1992-1996).
| HYDROMET | C3S | |
|---|---|---|
| date | ||
| 1992-09-28 | 1134.567 | 1135.32 |
| 1992-10-18 | 1134.572 | 1135.30 |
| 1992-11-15 | 1134.597 | 1135.36 |
| 1992-12-16 | 1134.672 | 1135.43 |
| 1993-01-14 | 1134.767 | 1135.54 |
Average Difference (C3S - HYDROMET) = 77.8 ± 3.0 cm
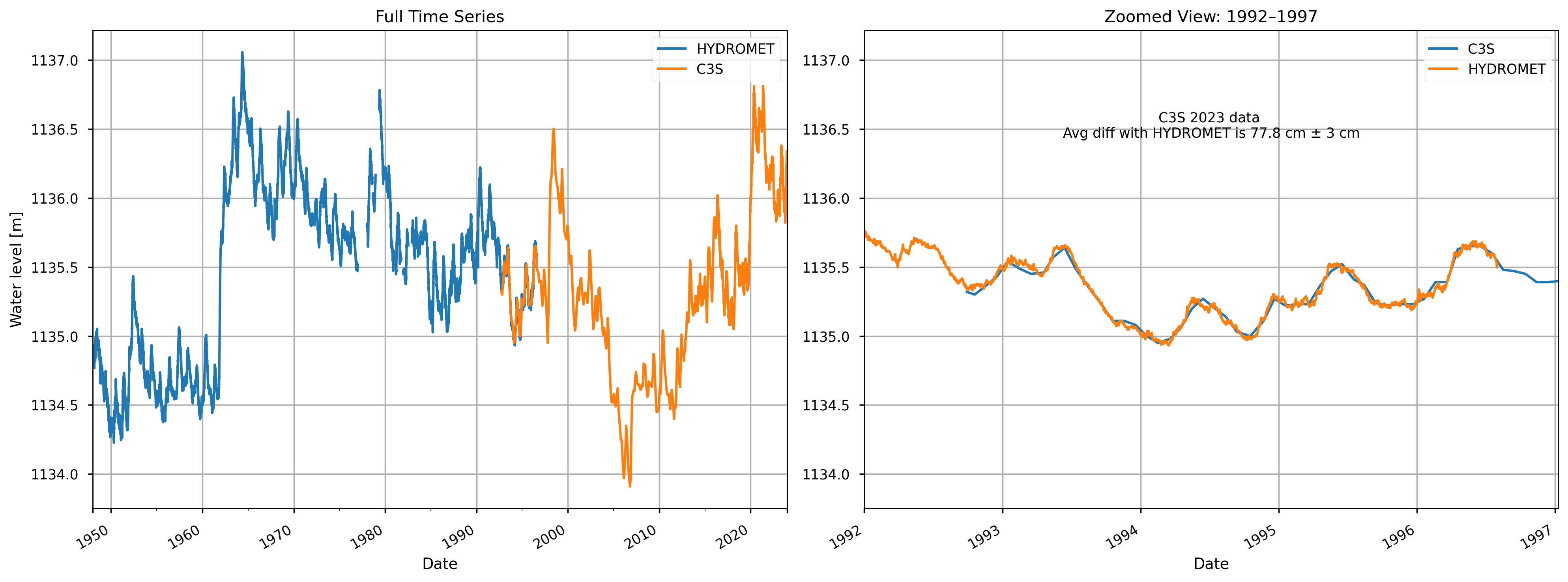
Figure 4. HYDROMET (1948-1996) and C3S (1992-2023) datasets timeseries after correction.
The average difference between the two datasets is 77.8 ± 3.0 cm [1]. The HYDROMET dataset was corrected using this value.
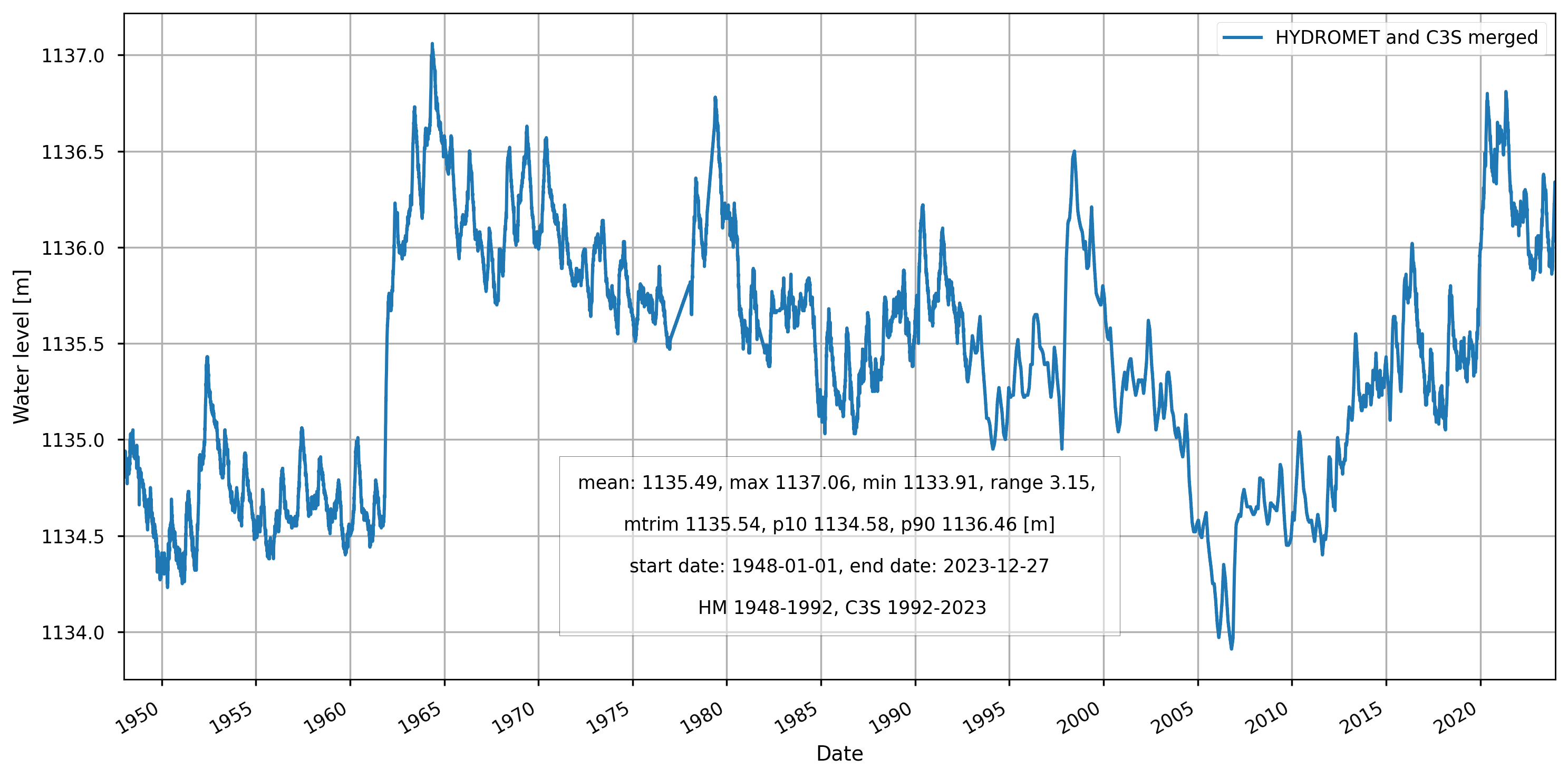
Figure 5. Reconstructed Lake Victoria’s water levels timeseries (1948-2023).
A single dataset combining both sources was created. For the overlap period between 1992 and 1997, C3S LWL-v5.0 data were used when available. The gaps were filled by interpolation to have a daily resolution.
4. Probabilistic extreme event analysis#
Pietroiusti et al. (2024) [1] assessed the influence of anthropogenic climate change on the 2020 Lake Victoria floods using the extreme event attribution framework outlined by Philip et al. (2020) [5] and van Oldenborgh et al. (2021) [6]. The methodology follows a structured sequence of steps: (i) defining the event, (ii) estimating probabilities and trends based on observational data, (iii) validating climate models, (iv) conducting attribution using multiple models and methods, and (v) synthesizing the findings into clear attribution statements.
In this assessment, only the first step, event definition, is performed, using reconstructed Lake Victoria water level time series from the HYDROMET dataset and the C3S LWL-v5.0 product. The aim is to assess whether the C3S LWL-v5.0 dataset is suitable for use in attribution analyses of this kind. While the remaining steps involve model simulations and additional data sources that are beyond the scope of this assessment, the assumption is that if the observational component is consistent, the full attribution framework could, in principle, be applied using this dataset as well.
Event definition#
The variable chosen for analysis is the rate of change in water levels (ΔL) over a time window (Δt), with Δt set to 180 days since most of the level rise in the 2020 Lake Victoria flooding occurred during the six-month period between November 2019 and May 2020 [1]. The code computes ΔL for every possible 180-day interval in the dataset, groups these values by year, and identifies the single largest 180-day change for each year, this is the the annual block maximum. The annual block maxima are then ranked to compare the magnitude of events across years. Finally, the ranking and maximum ΔL/Δt for 2020 are reported.
🔹 2020 ΔL/Δt (180 days): 1.210 m
🔹 2020 Rank: 3 out of 74 years
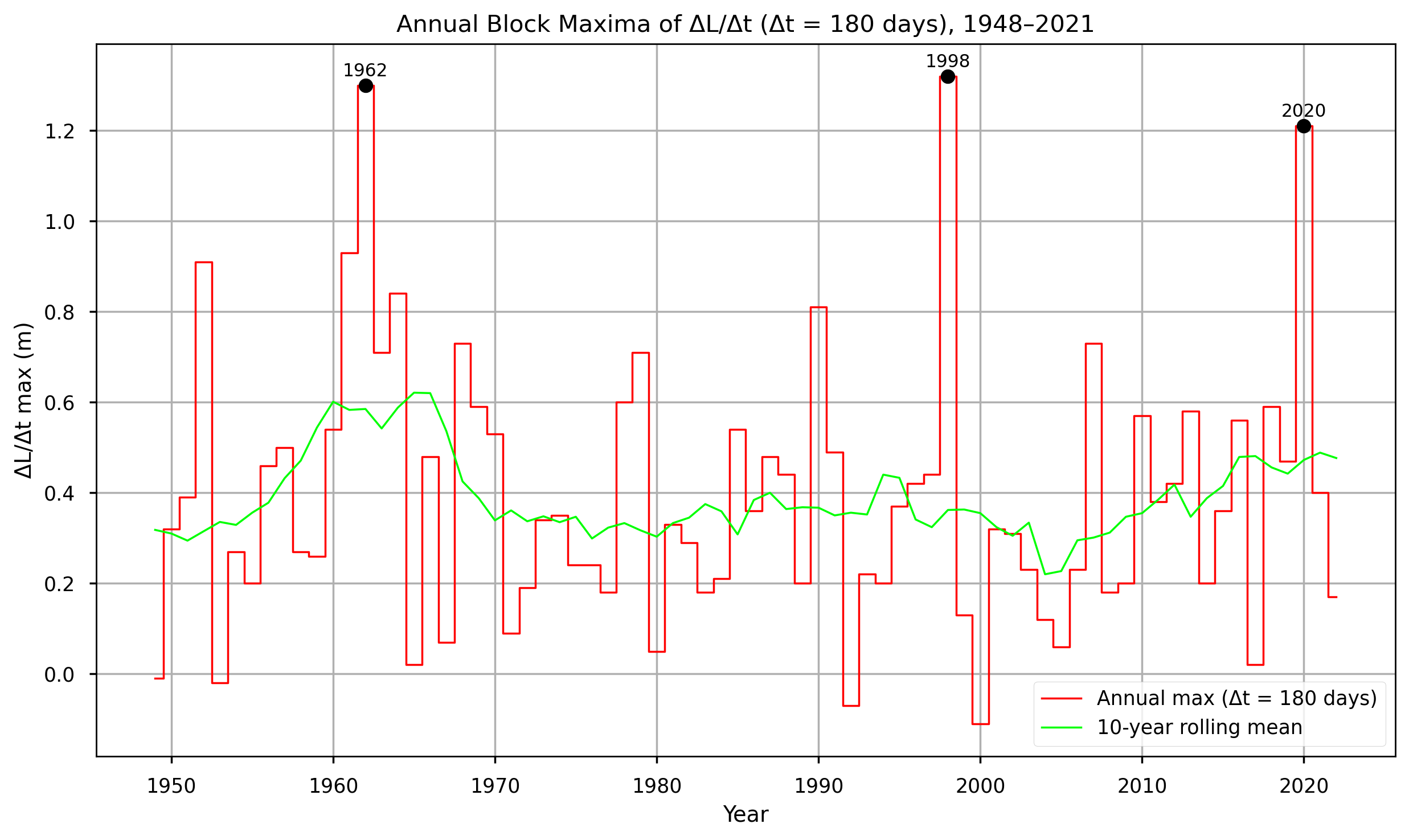
Figure 6. Annual block maxima time series \((\Delta L / \Delta t)_{\text{max}}\) with Δt=180 d for the period 1897–2021 and 10-year rolling mean of the time series (using C3S-LWL v5.0 data).
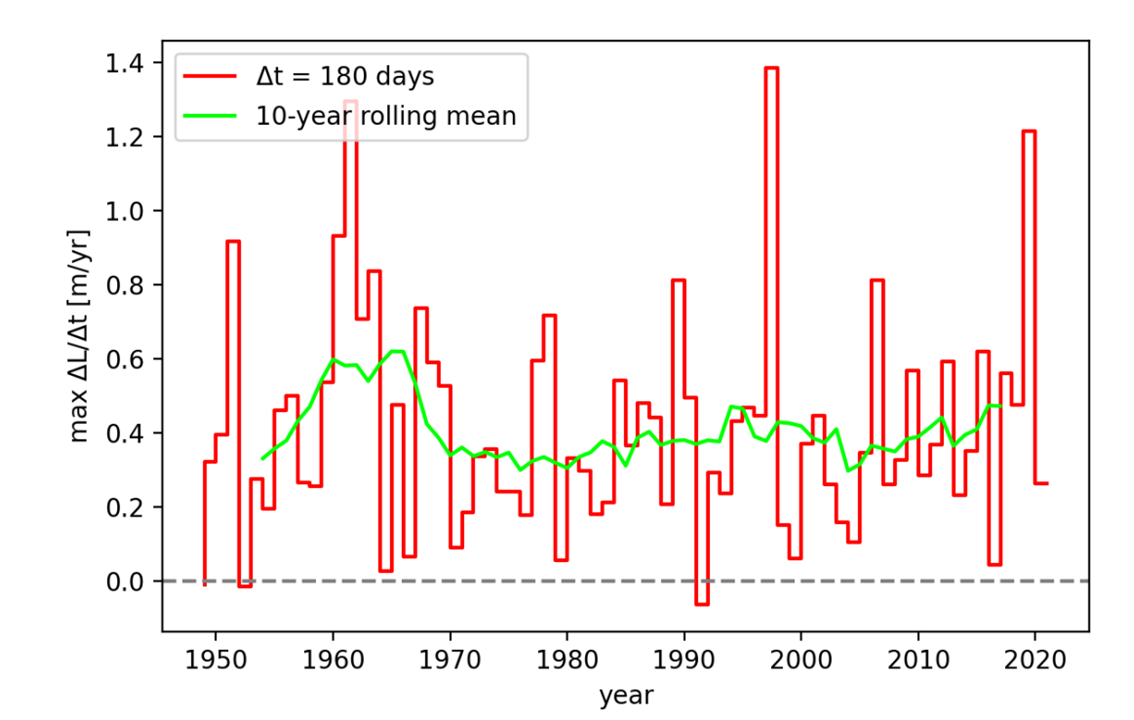
Figure 7. Annual block maxima time series \((\Delta L / \Delta t)_{\text{max}}\) with Δt=180 d for the period 1897–2021 and 10-year rolling mean of the time series (using DAHITI data). Source: Pietroiusti et al. (2022) [7]
The results of this analysis are consistent with those reported by Pietroiusti et al. (2024) [1]. According to the C3S-LWL v5.0 dataset, the year 2020 recorded the third-largest 180-day lake level rise, surpassed only by 1962 and 1998. The magnitude of the 2020 rise was 1.21 meters, which matches the value obtained by Pietroiusti et al. using the DAHITI dataset.
However, some discrepancies emerge when comparing other years. For instance, in 2000, the C3S-LWL v5.0 data shows a negative value, indicating a consistent decrease in lake levels throughout the year (see Figure 6). Conversely, the corresponding figure in Pietroiusti et al. (2022) [7] (see Figure 7) shows a slightly positive value.
These differences likely stem from variations in the underlying datasets, as discussed in 2. Comparison of C3S LWL with the DAHITI dataset. In 2000, TOPEX/Poseidon was still the only mission providing data for the C3S-LWL, with only one value per month. Meanwhile, DAHITI applied Kalman-filtered interpolation, resulting in a denser time series. Because no reliable in situ data are available for this period, it is difficult to determine which dataset more accurately reflects reality.
Nevertheless, the agreement between both datasets on the 2020 block maximum strengthens confidence in the reliability of this result. Although C3S-LWL and DAHITI use different processing algorithms, the increased availability of satellite observations in recent years (particularly after 2016) has resulted in greater similarity between their outputs. With more frequent and higher-quality measurements from multiple missions, the differences between the datasets diminish, making the 1.21 meter increase observed in 2020 not only consistent across sources, but also giving more confidence in the result.
This assessment supports the suitability of the C3S-LWL v5.0 dataset for extreme event attribution applications, as the event-definition results closely match those from Pietroiusti et al. (2024) [1]. Since this step feeds directly into the rest of the workflow, similar outcomes would be expected in a full attribution analysis.
ℹ️ If you want to know more#
NASA (2021). Lake Victoria’s Rising Waters
ACSA Uganda & Uganda Coalition for Sustainble Development (UCSD) (2020). The Implication of Floods to Food Security During and the Aftermath of COVID-19 Pandemic in Uganda
Key resources#
Code libraries used:
C3S EQC custom functions,
c3s_eqc_automatic_quality_control, prepared by B-Open
Dataset documentation:
References#
[1] Pietroiusti, R., Vanderkelen, I., Otto, F. E. L., Barnes, C., Temple, L., Akurut, M., Bally, P., van Lipzig, N. P. M., and Thiery, W. (2024). Possible role of anthropogenic climate change in the record-breaking 2020 Lake Victoria levels and floods, Earth Syst. Dynam., 15, 225–264.
[2] Schwatke, C., Dettmering, D., Bosch, W., and Seitz, F. (2015). DAHITI - an innovative approach for estimating water level time series over inland waters using multi-mission satellite altimetry: , Hydrol. Earth Syst. Sci., 19, 4345-4364.
[3] WMO-UNPD (1974). Hydrometeorological Survey of the Catchments of Lakes Victoria, Kyoga and Albert: Vol 1 Meteorology and Hydrology of the Basin.
[4] Vanderkelen, I., Van Lipzig, N. P., and Thiery, W. (2018). Modelling the water balance of Lake Victoria (East Africa)-Part 1: Observational analysis. Hydrology and Earth System Sciences, 22(10):5509–5525.
[5] Philip, S., Kew, S., van Oldenborgh, G. J., Otto, F., Vautard, R., van der Wiel, K., King, A., Lott, F., Arrighi, J., Singh, R., and van Aalst, M. (2020). A protocol for probabilistic extreme event attribution analyses, Adv. Stat. Clim. Meteorol. Oceanogr., 6, 177–203.
[6] G. J. van Oldenborgh, K. van der Wiel, S. Kew, S. Philip, F. Otto, R. Vautard, A. King, F. Lott, J. Arrighi, R. Singh, and M. van Aalst. Pathways and pitfalls in extreme event attribution. Climatic Change, vol. 166, no. 1, p. 13, 2021.
[7] Pietroiusti, R., Vanderkelen, I., van Lipzig, N. P. M., and Thiery, W. (2022). Was the 2020 Lake Victoria flooding ‘caused’ by anthropogenic climate change? An event attribution study. M.Sc. thesis, Dept. of Hydrology and Climate, Vrije Universiteit Brussel and KU Leuven.
[8] Coles, S. (2001). An Introduction to Statistical Modeling of Extreme Values. Springer Series in Statistics. Springer-Verlag London. ISBN: 978-1-85233-459-8.