

2.1. In-situ precipitation and air temperature for compound heatwave-drought monitoring#
Production date: 13/05/2026
Produced by: Beatriz Lopes and Ana Oliveira (CoLAB +ATLANTIC)
🌍 Use case: representing compound heatwaves-droughts in Europe#
❓ Quality assessment questions#
User Question: How well does gridded data derived from observations represent local exposure to heatwave-drought compound events?
We aim to evaluate the completeness of the E-OBS daily gridded meteorological data for Europe from 1950 to present derived from in-situ observations (henceforth, E-OBS) from the Climate Data Store (CDS) of the Copernicus Climate Change Service (C3S), to represent compound heatwave-drought events and their trend over Europe, as an example of using E-OBS in the scope of the European State of Climate [1].
📢 Quality assessment statement#
These are the key outcomes of this assessment
The study examined how heatwave–drought compound events evolved across Europe, over time and space, using extreme temperature and drought indices to define compound heatwave-drought months as those that were characterised by drought conditions and simultaneously experienced at least one heatwave.
Compound drought–heatwave events occur most frequently in southern and eastern Europe, particularly in Mediterranean and Continental-type climates, while Northern, Alpine, and Maritime bioregions experience fewer events. Statistical trend analysis reveals increasing compound-event occurrences in many southern and central European regions, whereas northern coastal areas generally show weaker or insignificant trends. These results are generally in agreement with previous studies (e.g. Weynants et al. [6] and Mathbout et al. [7]).
As described in this dataset’s documentation, the usage of this dataset should be with caution in interpreting trends and extremes, considering the potential limitations in accuracy and completeness, especially in regions with sparse observational data [6].
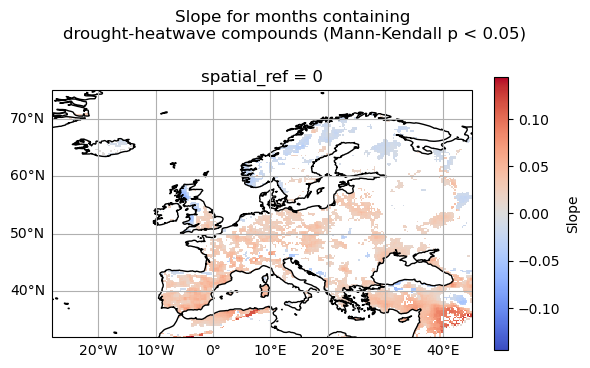
Fig. 2.1.1 Figure A. Trends of months containing heatwave-drought compounds.#
📋 Methodology#
This notebook provides an assessment of months containing heatwave-drought compounds using E-OBS daily gridded meteorological data for Europe from 1950 to present derived from in-situ observations dataset, E-OBS. Months containing at least one heatwave–drought compound event are identified as those in which the 3-month Standardised Precipitation Evapotranspiration Index (SPEI-3), calculated at a monthly temporal resolution using a 1-month rolling step, falls below −1, while at least one heatwave event occurs within the same month, using the 90th percentile of the daily mean temperature (TG) as the detection threshold for excessive heat (TG90p). The latter is selected as a subcomponent of the Excess Heat Factor (EHF) index. Both climate indices are based on the recommendations of the World Meteorological Organization (WMO)’s Expert Team on Sector-Specific Climate Indices (ET-SCI), in conjunction with sector experts.
The assessment examines the occurrence and temporal trends of these compound-event months using the Mann–Kendall trend test and Sen’s slope estimator.
The analysis and results follow the next outline:
1. Define the Area of Interest (AoI), search and download E-OBS
2. Identify months containing compound events
📈 Analysis and results#
1. Define the Area of Interest (AoI), search and download E-OBS#
1.1 Import the required packages#
We will be working with data in NetCDF format. To best handle this data, we will use libraries for working with multidimensional arrays, particularly Xarray. We will also need libraries for plotting and viewing data; in this case we will use Matplotlib and Cartopy.
1.2 Data Overview#
To search for data, visit the CDS website: http://cds.climate.copernicus.eu Here you can search for ‘in-situ observations’ using the search bar. The data we need for this tutorial is the E-OBS daily gridded meteorological data for Europe from 1950 to present, derived from in-situ observations. This catalogue entry provides a daily gridded dataset of historical meteorological observations, covering Europe (land-only), from 1950 to the present. This data is derived from in-situ meteorological stations, made available through the European Climate Assessment & Dataset (ECA&D) project, as provided by National Meteorological and Hydrological Services (NMHSs) and other data-holding institutes. E-OBS comprises a set of spatially continuous Essential Climate Variables (ECVs) from the Surface Atmosphere, following the Global Climate Observing System (GCOS) convention, provided as the mean and spread of the spatial prediction ensemble algorithm, at regular latitude-longitude grid intervals (at a 0.1° and 0.25° spatial resolution), and covering a long time period, from 1 January 1950 to the present day. In addition to the land surface elevation, E-OBS includes daily air temperature (mean, maximum and minimum), precipitation amount, wind speed, sea-level pressure and shortwave downwelling radiation. The E-OBS version used for this Use Case, E-OBSv31.0e, was released in September 2024 and its main difference from the previous E-OBSv30.0e is the inclusion of new series. Having selected the correct dataset, we now need to specify what product type, variables, and temporal and geographic coverage we are interested in. In this Use Case, the ensemble mean of daily mean temperature and Precipitation amount will be used, considering the last version available (31.0e). These can all be selected in the “Download data” tab from the CDS. In this tab, a form appears in which we will select the following parameters to download, for example:
Product Type: Ensemble mean
Variables: daily precipitation sum, and mean temperature
Grid resolution: 0.25
Period: Full period
Version: 31.0e
Format: Zip file (.zip)
At the end of the download form, select Show API request. This will reveal a block of code, which you can simply copy and paste into a cell of your Jupyter Notebook …
1.3. Download and prepare E-OBS data#
… having copied the API request to a Jupyter Notebook cell, running it will retrieve and download the data you requested into your local directory. However, before you run it, the terms and conditions of this particular dataset need to have been accepted directly at the CDS website. The option to view and accept these conditions is given at the end of the download form, just above the Show API request option. In addition, it is also useful to define the time period and Area of Interest (AoI) parameters and edit the request accordingly, as exemplified in the cells below.
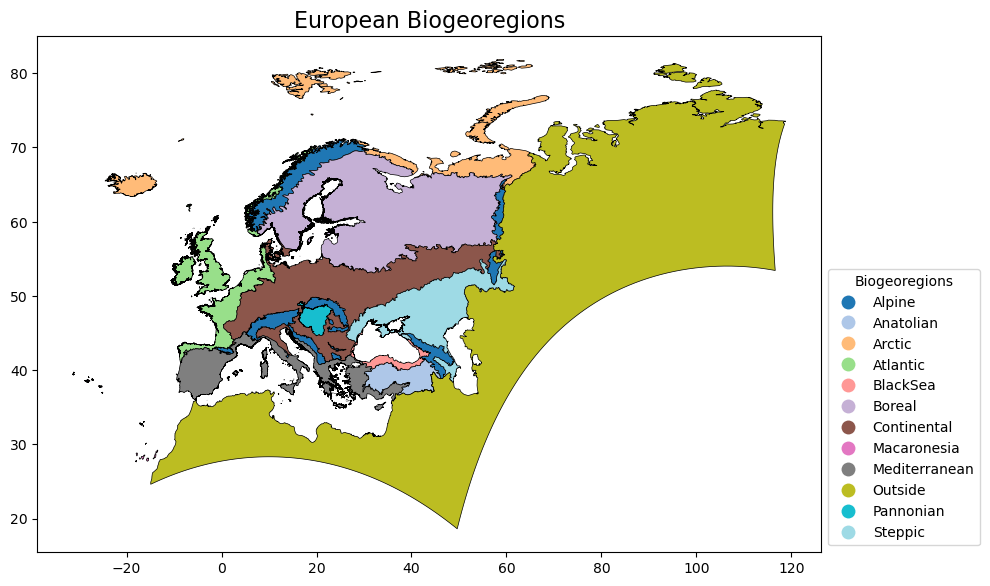
1.4 Download biogeographical regions shapefile#
To better illustrate the spatial patterns of compound heatwave-drought events over Europe, it is useful to use spatial aggregation units for our analysis. Here, we will be using the Biogeographical Regions in Europe. This dataset contains the official delineations used in the Habitats Directive (92/43/EEC) and for the EMERALD Network set up under the Convention on the Conservation of European Wildlife and Natural Habitats (Bern Convention), and the dataset is provided by the European Environmental Agency, available here: https://www.eea.europa.eu/en/analysis/maps-and-charts/biogeographical-regions-in-europe-2
['/data/wp5/.cache/pooch/biogeo_regions/eea_v_3035_1_mio_biogeo-regions_p_2016_v01_r00/BiogeoRegions2016.prj', '/data/wp5/.cache/pooch/biogeo_regions/eea_v_3035_1_mio_biogeo-regions_p_2016_v01_r00/BiogeoRegions2016.shp', '/data/wp5/.cache/pooch/biogeo_regions/eea_v_3035_1_mio_biogeo-regions_p_2016_v01_r00/README.md', '/data/wp5/.cache/pooch/biogeo_regions/eea_v_3035_1_mio_biogeo-regions_p_2016_v01_r00/Biogeographical_regions_Europe_2016_ver_1_metadata_c6d27566-e699-4d58-a132-bbe3fe01491b.xml', '/data/wp5/.cache/pooch/biogeo_regions/eea_v_3035_1_mio_biogeo-regions_p_2016_v01_r00/BiogeoRegions2016.sqlite', '/data/wp5/.cache/pooch/biogeo_regions/eea_v_3035_1_mio_biogeo-regions_p_2016_v01_r00/BiogeoRegions2016.dbf', '/data/wp5/.cache/pooch/biogeo_regions/eea_v_3035_1_mio_biogeo-regions_p_2016_v01_r00/BiogeoRegions2016.shx', '/data/wp5/.cache/pooch/biogeo_regions/eea_v_3035_1_mio_biogeo-regions_p_2016_v01_r00/BiogeoRegions2016.cpg']
Befor proceeding with the analysis, it’s useful to inspect the Biogeographical Regions dataset in terms of existing classes and their spatial distribution.
| PK_UID | short_name | pre_2012 | code | name | geometry | |
|---|---|---|---|---|---|---|
| 0 | 1 | alpine | ALP | Alpine | Alpine Bio-geographical Region | MULTIPOLYGON (((13.95511 42.15849, 13.97267 42... |
| 1 | 2 | anatolian | ANA | Anatolian | Anatolian Bio-geographical Region | POLYGON ((44.23502 41.00345, 44.29092 40.95563... |
| 2 | 3 | arctic | ARC | Arctic | Arctic Bio-geographical Region | MULTIPOLYGON (((-14.15531 64.59547, -14.16376 ... |
| 3 | 4 | atlantic | ATL | Atlantic | Atlantic Bio-geographical Region | MULTIPOLYGON (((-7.91327 51.9073, -7.91331 51.... |
| 4 | 5 | blackSea | BLS | BlackSea | Black Sea Bio-geographical Region | MULTIPOLYGON (((31.68171 41.40784, 31.67965 41... |
| 5 | 6 | boreal | BOR | Boreal | Boreal Bio-geographical Region | MULTIPOLYGON (((15.96006 56.17099, 15.96028 56... |
| 6 | 7 | continental | CON | Continental | Continental Bio-geographical Region | MULTIPOLYGON (((11.68926 54.66394, 11.6891 54.... |
| 7 | 8 | macaronesia | MAC | Macaronesia | Macaronesian Bio-geographical Region | MULTIPOLYGON (((-15.36375 27.9894, -15.36341 2... |
| 8 | 9 | mediterranean | MED | Mediterranean | Mediterranean Bio-geographical Region | MULTIPOLYGON (((12.52998 35.52716, 12.53124 35... |
| 9 | 10 | outside | OUT | Outside | outside Europe | MULTIPOLYGON (((10.83582 33.89309, 10.87423 33... |
| 10 | 11 | pannonian | PAN | Pannonian | Pannonian Bio-geographical Region | MULTIPOLYGON (((19.14193 45.12975, 19.14147 45... |
| 11 | 12 | steppic | STE | Steppic | Steppic Bio-geographical Region | MULTIPOLYGON (((30.37039 40.37592, 30.35937 40... |
2. Identify months containing compound events#
Now we can identify our months containing at least one compound event. In this analysis, compound events are defined as months during which drought conditions coincide (based on SPEI) with the occurrence of at least one heatwave (based on TG90p) event. Although identifying compound events at the monthly scale is a limitation, this approach was necessary because the drought and heatwave algorithms operate over different temporal scopes. Therefore, using different assumptions regarding the temporal scale of extremes may lead to different results, and care should be taken when interpreting them.
For this, we first identify drought and heatwave conditions.
2.1 Calculate Standardised Precipitation Evapotranspiration Index (SPEI)#
The SPEI index incorporates temperature data to account for both precipitation and evapotranspiration (ET), making it sensitive to climate-driven changes in water demand. This allows SPEI to better reflect drought conditions under warming scenarios, as it considers not only rainfall deficits but also increased evaporation due to higher temperatures. While several ET estimation algorithms exist, here we use the Thornthwaite method, which is based on temperature and solar radiation, by latitude and season. The functions for Evapotranspiration computation were based on the “climate_indices” Python library, from James Adams [2].
SPEI index requires the definition of the time scale for aggregating the variables and calculate its values as seasonal or annual summaries (e.g., 3 months, 6 months, 1 year). Here we are going to select 3 months as the target time, and proceed to calculate the precipitation and evapotranspiration sums over this period with a 1-month rolling window to obtain the index calculated for every month (i.e., based on that month and the prior two).
2.2 Calculate Heatwaves#
Several heatwave definitions exist, adopting different thresholds and formulations, and based on different daily air temperature statistics (e.g., TG, TN or TX). As mentioned earlier, here, heatwaves are defined as periods during which TG exceeds the 90th percentile of a climatological baseline for at least three consecutive days. This approach is loosely based on the Excess Heat Factors (EHF)’s Excess Heat Index Significance (EHIsig) component, which measures how hot the current day is compared to a long-term reference [3] [4]. While the EHF multiplies this component with the short-term Excess Heat Acclimatization (EHIaccl) counterpart, for a heatwave to be detected, the EHIsig is the primary condition, while ensuring 3-days as the minimum duration of the excess.
The percentile threshold is calculated for each calendar day based on a reference period, allowing the definition to adapt to local climate conditions. To reduce short-term variability and ensure temporal consistency, the 90th percentile climatological threshold is smoothed using a 7-day moving average (sliding window).
For this analysis, we want to identify if there is at least one heatwave event in each month.
2.3 Identify heatwave-drought compounds#
Having identified heatwave and droughts we can now define our months containing at least one compound event.
100%|██████████| 1/1 [00:00<00:00, 5.03it/s]
<xarray.Dataset> Size: 2GB
Dimensions: (latitude: 201, longitude: 464, time: 900)
Coordinates:
* latitude (latitude) float64 2kB 25.38 25.62 25.88 ... 74.88 75.12 75.38
* longitude (longitude) float64 4kB -40.38 -40.12 -39.88 ... 75.12 75.38
* time (time) datetime64[ns] 7kB 1950-01-01 1950-02-01 ... 2024-12-01
Data variables:
spei (latitude, longitude, time) float64 672MB dask.array<chunksize=(30, 30, 120), meta=np.ndarray>
hw (time, latitude, longitude) float64 672MB dask.array<chunksize=(120, 30, 30), meta=np.ndarray>
compound (time, latitude, longitude) float64 672MB dask.array<chunksize=(120, 30, 30), meta=np.ndarray>As the area of the pixels varies in latitude, a weighted approach is needed when calculating area-based statistics. Let’s then create weights to use later
2.4 Example for the year 2020#
To illustrate the concept of a compound month, we can plot the time series for 2020 of the variables averaged over the AoI.
Please note that, to ensure consistency between the time series, heatwaves here illustrated derive from the difference between the spatially weighted average air temperature and TG90p time series. Compound events derive form the intersection of these and the spatial mean of SPEI.
100%|██████████| 1/1 [00:00<00:00, 21.73it/s]
100%|██████████| 1/1 [00:00<00:00, 15.05it/s]
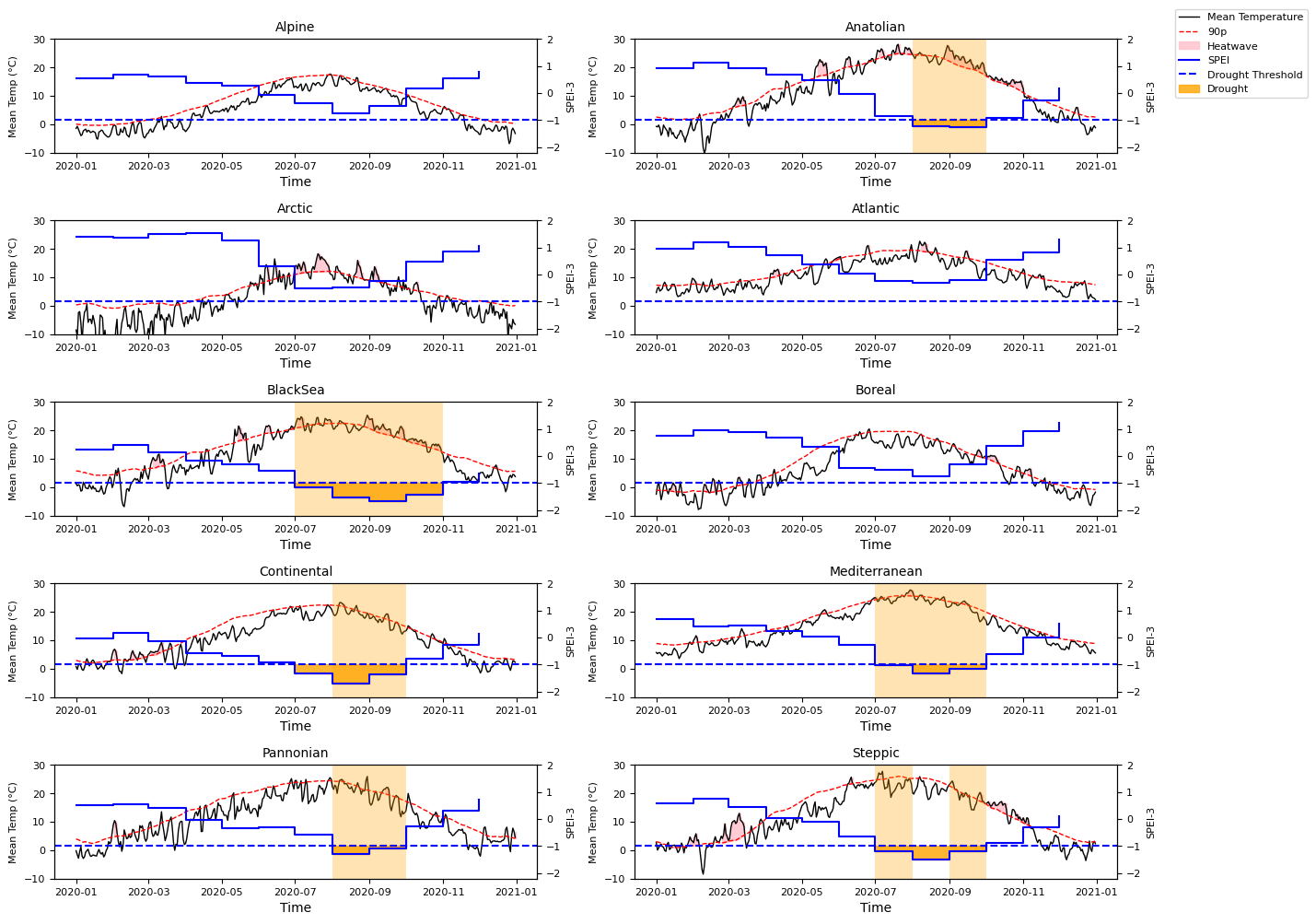
The figure shows regional variability in the occurrence and duration of heatwave-drought compounds, with Mediterranean, Steppic, Pannonian, Continental, Black Sea and Anatolian regions exhibiting compound heatwave-drought conditions during the summer and early autumn of 2020. In contrast, Alpine, Arctic, Atlantic and Boreal regions show no months with compound events during 2020.
3. Heatwave-drought compound statistics#
Now, we are going to compute some statistics of the compound events at the pixel scale. We are going to start by calculating mean, sum and standard deviation of number of compound events over the climatological periods, as per the guidelines from the World Meteorological Organization (WMO) [5]:
1951-1980
1961-1990
1971-2000
1981-2010
1991-2020
After that, we are going to plot the years with the overall highest and lowest number of compound events over the whole european domain.
<xarray.DataArray 'compound' (year: 75, latitude: 201, longitude: 464)> Size: 56MB
dask.array<transpose, shape=(75, 201, 464), dtype=float64, chunksize=(10, 30, 30), chunktype=numpy.ndarray>
Coordinates:
* year (year) int64 600B 1950 1951 1952 1953 ... 2021 2022 2023 2024
* latitude (latitude) float64 2kB 25.38 25.62 25.88 ... 74.88 75.12 75.38
* longitude (longitude) float64 4kB -40.38 -40.12 -39.88 ... 75.12 75.38
spatial_ref int64 8B 0


Taken together, these figures indicate that months containing heatwave-drought compound events are not only becoming more frequent across Europe, but are also exhibiting greater variability (as measured through the standard deviation). Spatial differences are also noticeable, with the Mediterranean and Continental regions emerging as hotspots of these events. Let’s now complement by looking into the year that revealed the maximum and minimum counts of compound events.
<xarray.DataArray 'compound' (year: 75)> Size: 600B
dask.array<sum-aggregate, shape=(75,), dtype=float64, chunksize=(10,), chunktype=numpy.ndarray>
Coordinates:
* year (year) int64 600B 1950 1951 1952 1953 ... 2021 2022 2023 2024
spatial_ref int64 8B 0(array(2019.), array(1978.))
(<Figure size 1200x600 with 4 Axes>,
array([<GeoAxes: title={'center': 'spatial_ref = 0, year = 1978'}, xlabel='longitude', ylabel='latitude'>,
<GeoAxes: title={'center': 'spatial_ref = 0, year = 2019'}, xlabel='longitude', ylabel='latitude'>],
dtype=object))
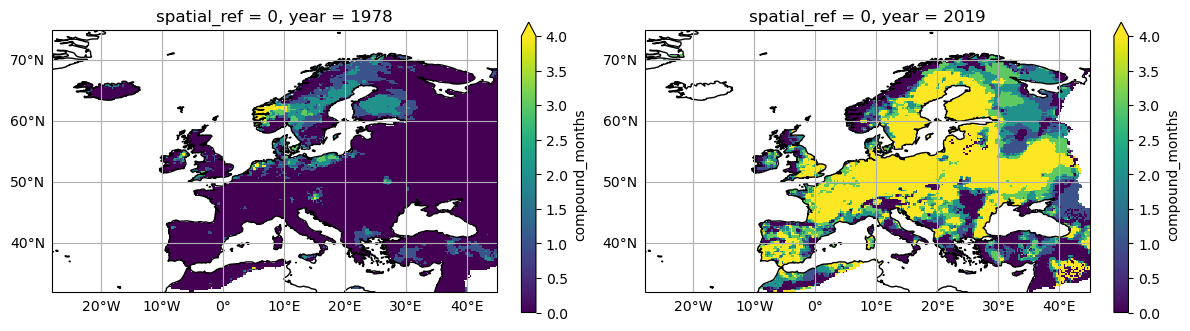
Year with the lowest number of months containing compounds over the AoI: 1978
Year with the highest number of months containing compounds over the AoI: 2019
4. Linear Trends#
To finalise the analysis, we are going to plot the trends of the annual number of months containing at least one heatwave- drought compound on a pixel-wise basis, as well as the percentage of area with compound events in each year by biogeographical region.
| sum | mean | min | max | std | ||
|---|---|---|---|---|---|---|
| region | period | |||||
| alpine | 1961-1990 | 1.25 | 0.76 | 0.0 | 4.08 | 1.12 |
| 1991-2020 | 1.78 | 1.08 | 0.0 | 5.34 | 1.49 | |
| trend (Sen's slope) | 0.53 | 0.32 | 0.0 | 1.26 | 0.37 | |
| anatolian | 1961-1990 | 10.60 | 0.64 | 0.0 | 3.33 | 0.94 |
| 1991-2020 | 26.48 | 1.54 | 0.0 | 4.34 | 1.36 | |
| trend (Sen's slope) | 15.89 | 0.90 | 0.0 | 1.02 | 0.42 | |
| arctic | 1961-1990 | 0.43 | 0.44 | 0.0 | 2.51 | 0.68 |
| 1991-2020 | 0.49 | 0.53 | 0.0 | 2.81 | 0.79 | |
| trend (Sen's slope) | 0.06 | 0.09 | 0.0 | 0.30 | 0.11 | |
| atlantic | 1961-1990 | 3.08 | 0.78 | 0.0 | 4.90 | 1.32 |
| 1991-2020 | 4.62 | 1.17 | 0.0 | 5.55 | 1.58 | |
| trend (Sen's slope) | 1.55 | 0.39 | 0.0 | 0.65 | 0.26 | |
| blackSea | 1961-1990 | 2.87 | 0.58 | 0.0 | 3.35 | 0.91 |
| 1991-2020 | 7.14 | 1.43 | 0.0 | 5.34 | 1.60 | |
| trend (Sen's slope) | 4.27 | 0.85 | 0.0 | 1.99 | 0.69 | |
| boreal | 1961-1990 | 10.03 | 0.85 | 0.0 | 3.60 | 1.04 |
| 1991-2020 | 13.15 | 1.13 | 0.0 | 4.62 | 1.36 | |
| trend (Sen's slope) | 3.12 | 0.28 | 0.0 | 1.03 | 0.32 | |
| continental | 1961-1990 | 6.27 | 0.75 | 0.0 | 4.09 | 1.17 |
| 1991-2020 | 12.36 | 1.48 | 0.0 | 6.05 | 1.76 | |
| trend (Sen's slope) | 6.08 | 0.73 | 0.0 | 1.96 | 0.59 | |
| mediterranean | 1961-1990 | 4.60 | 0.68 | 0.0 | 3.58 | 1.01 |
| 1991-2020 | 12.31 | 1.80 | 0.0 | 5.58 | 1.64 | |
| trend (Sen's slope) | 7.71 | 1.12 | 0.0 | 2.00 | 0.63 | |
| pannonian | 1961-1990 | 15.29 | 0.97 | 0.0 | 3.96 | 1.20 |
| 1991-2020 | 24.71 | 1.56 | 0.0 | 6.67 | 1.76 | |
| trend (Sen's slope) | 9.41 | 0.59 | 0.0 | 2.70 | 0.56 | |
| steppic | 1961-1990 | 3.29 | 0.80 | 0.0 | 3.77 | 1.08 |
| 1991-2020 | 6.66 | 1.63 | 0.0 | 4.69 | 1.47 | |
| trend (Sen's slope) | 3.38 | 0.84 | 0.0 | 0.92 | 0.39 |
<xarray.DataArray 'compound' (time: 75, latitude: 201, longitude: 464)> Size: 56MB
dask.array<transpose, shape=(75, 201, 464), dtype=float64, chunksize=(10, 30, 30), chunktype=numpy.ndarray>
Coordinates:
* time (time) datetime64[ns] 600B 1950-01-01 1951-01-01 ... 2024-01-01
* latitude (latitude) float64 2kB 25.38 25.62 25.88 ... 74.88 75.12 75.38
* longitude (longitude) float64 4kB -40.38 -40.12 -39.88 ... 75.12 75.38
spatial_ref int64 8B 0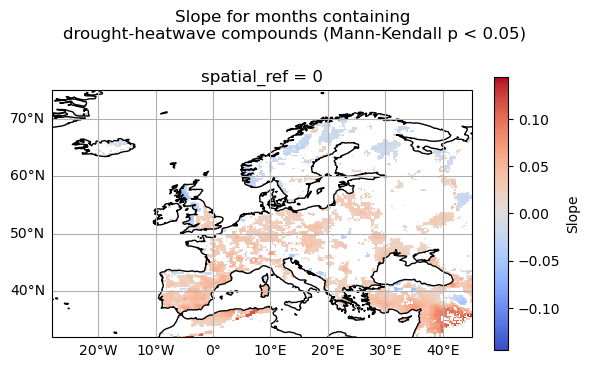
The results reveal that the increase in compound heatwave-drought occurrence is not spatially uniform across Europe. Significant positive trends dominate large parts of southern, western, and central Europe. Increases are particularly visible across the Iberian Peninsula, southern France, some regions of Italy, the Balkans, and portions of eastern Europe. When positive changes are detected, their magnitudes are mostly on the order of 0.5 additional months containing compound events per decade. In contrast, negative trends are more localised and mainly appear in northern and north-eastern Europe, as well as isolated regions near the eastern Mediterranean and Black Sea. However, these decreasing trends are spatially limited compared with the widespread positive trends observed elsewhere, and their magnitudes are much lower.
The use of the Mann–Kendall significance test ensures that only statistically robust trends are shown, reducing the influence of short-term variability.
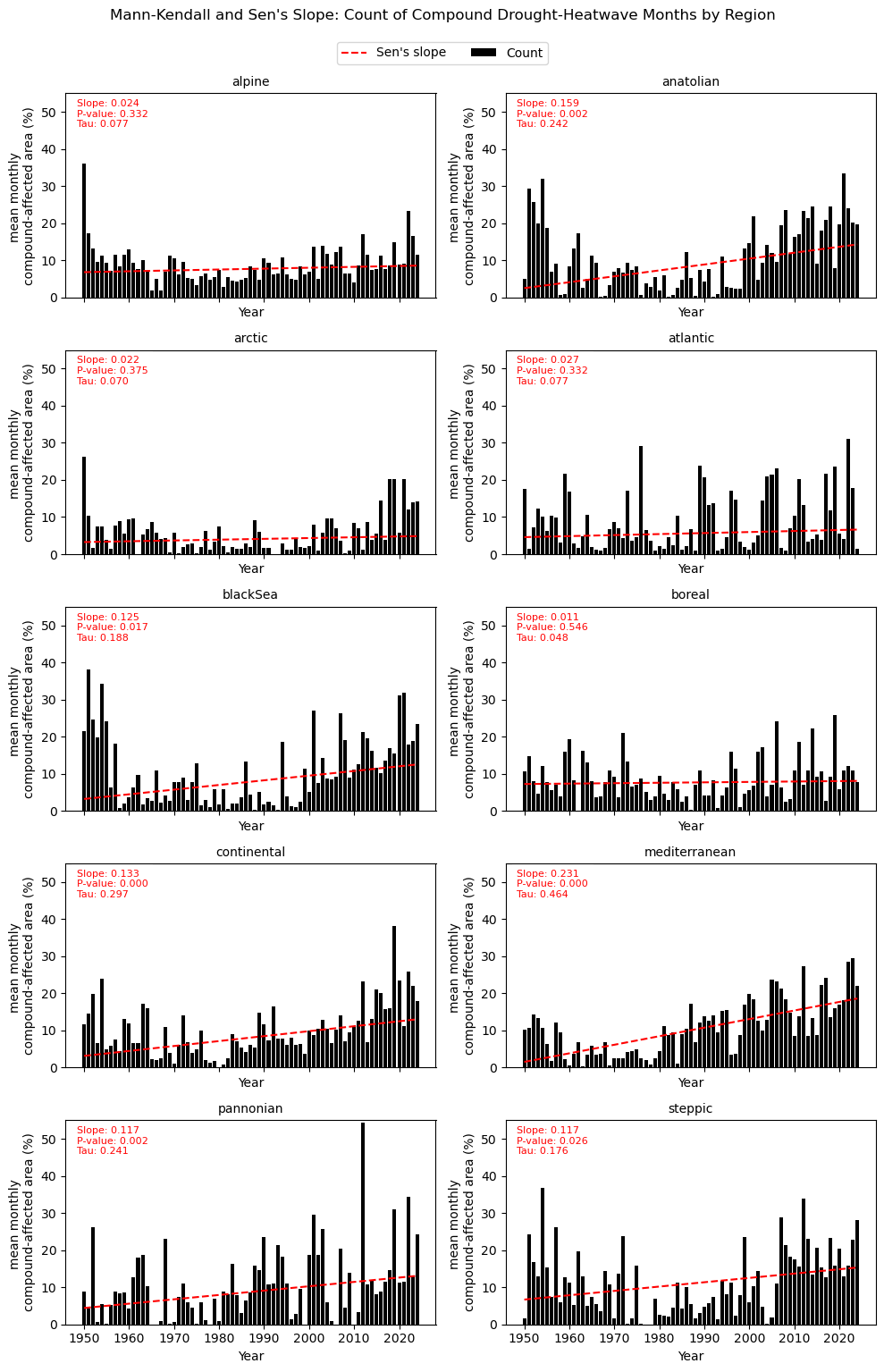
Trends of the area percentage of months containing at least one compound event also varies between the regions, with overall increases identified.
The strongest and most statistically significant increases are observed in the Mediterranean, Continental, Anatolian, Pannonian, Black Sea, and Steppic regions. Among these, the Mediterranean region shows the largest Sen’s slope (0.231) and the highest Kendall’s Tau (0.464), indicating a strong and persistent increase in the spatial extent of compound events over time. Similarly, Continental and Anatolian regions exhibit pronounced upward trends with highly significant p-values, suggesting that concurrent hot and dry conditions are becoming increasingly widespread in these climates.
The Black Sea, Pannonian, and Steppic regions also display significant positive trends, although with greater interannual variability. These regions show alternating periods of low and high compound occurrences, but the long-term tendency remains upward.
In contrast, Alpine, Arctic, Atlantic, and Boreal regions exhibit weaker and statistically non-significant trends, consistent with the 2020 plots (Section 2.4). Although these regions still show some increase in compound-event occurrence, the lower Sen’s slope values and higher p-values suggest that long-term changes are less robust.
5. Main takeaways#
The study analysed the spatial and temporal evolution of heatwave-drought compounds across Europe using E-OBS daily mean temperature data and SPEI-3 drought indicators. Compounds are defined as months in which drought conditions (SPEI-3 < −1) coincided with at least one heatwave event identified using a smoothed 90th percentile temperature threshold (TG90p). Although identifying compound events at the monthly scale is a limitation, this approach was necessary because the drought and heatwave algorithms operate over different temporal scopes. Therefore, using different assumptions regarding the temporal scale of extremes may lead to different results, and care should be taken when interpreting them.
The results show a clear spatial gradient in compound-event occurrence across Europe. Mediterranean, Continental, Pannonian, Steppic, Black Sea, and Anatolian regions consistently exhibited the highest frequency and spatial extent of compound drought–heatwave months, while Alpine, Atlantic, Arctic, and Boreal regions generally experience fewer events.
Trend analyses using the Mann–Kendall test and Sen’s slope demonstrate statistically significant positive trends in several European regions, especially in Mediterranean, Continental, Anatolian, Pannonian, Black Sea, and Steppic climates. In contrast, northern and maritime regions show weaker or non-significant trends, suggesting lower susceptibility to persistent compound hot–dry conditions.
Although different studies tend to use different metrics, the spatial patterns of the results agree with previous studies using SPEI and heatwaves to assess compound events (e.g. Weynants et al. [6] and Mathbout et al. [7]). The E-OBS dataset proved suitable for identifying broad regional patterns and changes in compound HW-drought across Europe.
However, as described in this dataset’s documentation, the usage of this dataset should be with caution in interpreting trends and extremes, considering the potential limitations in accuracy and completeness, especially in regions with sparse observational data [8]. Furthermore, the spatial variability in stations density should be considered when interpreting results at a more localised scale. For instance, it may also be influenced by factors such as changes in observational practices, station location shifts, or urbanisation effects, which can introduce uncertainties in the interpretation of long-term trends. For local-specific analysis, the ensemble spread can serve as a proxy in determining the pixel-wise level of uncertainty.
ℹ️ If you want to know more#
Key resources#
Some key resources and further reading were linked throughout this assessment.
The CDS catalogue entries for the data used were:
E-OBS daily gridded meteorological data for Europe from 1950 to present derived from in-situ observations: https://cds.climate.copernicus.eu/datasets/insitu-gridded-observations-europe?tab=overview
ERA5 hourly data on single levels from 1940 to present: https://cds.climate.copernicus.eu/datasets/reanalysis-era5-single-levels?tab=overview
Code libraries used:
C3S EQC custom functions,
c3s_eqc_automatic_quality_control, prepared by B-Open
If you want to know more about compound events:
IPCC Sixth Assessment Report - Chapter 11: Wheather and Climate Extreme Events in a Changing Climate https://www.ipcc.ch/report/ar6/wg1/chapter/chapter-11/
References#
[1] Copernicus Climate Change Service. 2024. European State of the Climate 2023.
[2] Adams, J. (2017). Climate_indices, an open source Python library providing reference implementations of commonly used climate indices.
[3] Nairn, J. R., & Fawcett, R. J. B. (2015). The Excess Heat Factor: A Metric for Heatwave Intensity and Its Use in Classifying Heatwave Severity. International Journal of Environmental Research and Public Health, 12(1), 227-253.
[4] Nairn, J., Ostendorf, B., & Bi, P. (2018). Performance of Excess Heat Factor Severity as a Global Heatwave Health Impact Index. International Journal of Environmental Research and Public Health, 15(11), 2494.
[5] World Meteorological Organization (WMO), Guidelines on the Calculation of Climate Normals.
[6] Weynants, M., Ji, C., Linscheid, N., Weber, U., Mahecha, M. D., and Gans, F. (2025) Dheed: an ERA5 based global database of compound dry and hot extreme events from 1950 to 2023, Earth Syst. Sci. Data, 17, 6621–6645.
[7] Mathbout, S., Boustras, G., Lopez Bustins, J. A., Martin Vide, J., & Papazoglou, P. (2025). Europe’s double threat: Evolving patterns of compound heatwaves and droughts. International Journal of Applied Earth Observation and Geoinformation, 145, 104987.
[8] Cornes, R., G. van der Schrier, E.J.M. van den Besselaar, and P.D. Jones. 2018: An Ensemble Version of the E-OBS Temperature and Precipitation Datasets, J. Geophys. Res. (Atmospheres), 123.