Reproducing the single-system graphical products for additional variables#
Introduction#
This Jupyter Notebook shows how the products shown in the C3S seasonal graphical products can be calculated from data in the Climate Data Store (CDS), and plotted. The C3S seasonal graphical and data products are described in this documentation page.
This example code can be used as the basis for creating graphical products which are not part of the C3S suite. In this example we look at monthly mean daily minimum temperature real-time forecasts (for one system, ECMWF System 51), which is a variable available in the CDS dataset but not the graphical products. A ‘tercile summary’ is computed from tercile probabilities. An ensemble mean anomaly is also calculated and plotted with significance testing applied. This will be used in a further example to create multi-system combinations.
Note
Some of the python code uses a set of utility functions available in the GitHub respository which hosts these Notebooks.
Configuration#
Here we set which variable(s) will be downloaded, for which C3S seasonal system. We also set which real-time forecast date we will create a real-time forecast for, and which hindcast period to use (which will be used to calculate the terciles and anomalies).
Note that the URL and KEY need to be filled in with the details from your CDS account, and the cdsapi package needs to be installed. Ideally, a .cdsapirc file should be created, to avoid the possibility of exposing credentials when sharing Notebooks. CDS API requests can now also be made using earthkit, as shown in this example.
Import required modules and configure CDS API key and client.
# import required modules
import cdsapi
import os
import xarray as xr
import numpy as np
import pandas as pd
import sys
from pathlib import Path
# Date and time related libraries
from dateutil.relativedelta import relativedelta
from calendar import monthrange
# Plotting libraries
import matplotlib.pyplot as plt
import cartopy.crs as ccrs
import cartopy.feature as cfeature
# Add parent directory to path so we can import the utils package
sys.path.insert(0, str(Path.cwd().parent))
from utils.tools import getForecastsystemDetails
# config to avoid issues saving to netcdf if needed
os.environ['HDF5_USE_FILE_LOCKING'] = 'FALSE'
URL = 'https://cds.climate.copernicus.eu/api'
KEY = '' # INSERT CDS KEY HERE IF NEEDED
c = cdsapi.Client(url=URL, key=KEY) # if a .cdsapirc file is used, url and key can be omitted
c = cdsapi.Client()
CDS API requests#
Here we request the desired hindcast and real-time forecast data in GRIB format using the CDS API, and save it within a ‘data’ folder in the current working directory, organized by originating centre and real-time forecast system. For this example, the CDS API keywords used are:
Format: Grib
Variable: minimum_2m_temperature_in_the_last_24_hours set via ‘cds_var_name’
Originating centre: ECMWF set via ‘origin’
System: 51 this refers to SEAS5 system 51, set via ‘system’
Product type: Monthly mean all ensemble members will be retrieved
Year: 1993 to 2016 for the hindcast 2024 for the real-time forecast, set via ‘hc_years’ and ‘fc_year’
Month: 02 February, set via ‘st_mon’
Leadtime month: 1 to 6 all lead months available, February to July in this case
Set some parameters for the request, and to be used later during plotting.
origin = 'ecmwf' # originating centre label for the CDS request
system = '51' # forecast system identifier for the CDS request
prov = f'{origin}.s{system}'
# Get system details from configuration files in utils directory using format ukmo.s604
system_details = getForecastsystemDetails(prov)
lagged = system_details.get('system_details',{}).get('isLagged',False)
print(system_details)
# define some other parameters for the data request
fc_yr = '2024' # the real-time forecast year
st_mon = '02' # the real-time forecast start month
# select a variable, tmin in this case
var = 'tmin'
var_str = 'daily mean T2m' # for plotting
var_cds_name = '2m_temperature'
lt_mons = [1, 2, 3, 4, 5, 6] # cover all lead months when plotting month by month
hc_start = '1993'
hc_end = '2016'
hc_years = '_'.join([hc_start, hc_end]) # string to print the hindcast period, and label the file
# data path in cwd
data_path = os.sep.join(['data', origin, system])
try:
os.makedirs(data_path)
except FileExistsError:
# directory already exists
pass
{'origin_details': {'MARS_origin': 'ecmf', 'label': 'ECMWF'}, 'system_details': {'name': 'SEAS5 (C3Sv5.1)', 'in_c3s': '20221101', 'ens_size': {'products': {'hc': 25}}}}
Make the hindcast request and save the data.
#HINDCAST REQUEST - 1993-2016
c.retrieve(
'seasonal-monthly-single-levels',
{
'format': 'grib',
'variable': var_cds_name,
'originating_centre': origin,
'system': system,
'product_type': 'monthly_mean',
'year': [
'1993', '1994', '1995',
'1996', '1997', '1998',
'1999', '2000', '2001',
'2002', '2003', '2004',
'2005', '2006', '2007',
'2008', '2009', '2010',
'2011', '2012', '2013',
'2014', '2015', '2016',
],
'month': [st_mon],
'leadtime_month': lt_mons
},
data_path + f'/{var}_mm_{origin}_{system}_{hc_years}_{st_mon}.grib'
Make the real-time forecast request and save the data.
#FORECAST REQUEST
c.retrieve(
'seasonal-monthly-single-levels',
{
'format': 'grib',
'variable': [var_cds_name],
'originating_centre': origin,
'system': system,
'product_type': 'monthly_mean',
'year': [fc_yr],
'month': [st_mon],
'leadtime_month': lt_mons
},
data_path + f'/{var}_mm_{origin}_{system}_{fc_yr}_{st_mon}.grib'
)
Load real-time forecast and hindcast data#
First, prepare for the lagged start time coordinates, where careful treatment is required when loading the data into xarray. Some of the seasonal forecast monthly data on the CDS comes from systems using members initialized on different start dates (lagged start date ensembles). In the GRIB encoding used for those systems we will therefore have two different xarray/cfgrib keywords for the real start date of each member (time) and for the nominal start date (indexing_time) which is the one we would need to use for those systems initializing their members with a lagged start date approach.
# For the re-shaping of time coordinates in xarray.Dataset we need to select the right one
# -> burst mode ensembles (e.g. ECMWF SEAS5) use "time".
# -> lagged start ensembles (e.g. MetOffice GloSea6) use "indexing_time" (see documentation about nominal start date)
if lagged:
st_dim_name = 'indexing_time'
else:
st_dim_name = 'time'
Now load the hindcast data as an xarray object using cfgrib (link), and inspect it.
# load hindcasts
hc_path = data_path + '/' + '_'.join([var, 'mm', origin, system, hc_years, st_mon]) + '.grib'
hcst = xr.open_dataarray(hc_path, engine='cfgrib',
backend_kwargs=dict(time_dims=('forecastMonth', st_dim_name)))
# rename indexing time or time to start date
hcst = hcst.rename({st_dim_name: 'start_date', 'longitude': 'lon', 'latitude': 'lat'})
# roll longitude
hcst = hcst.assign_coords(lon=(((hcst.lon + 180) % 360) - 180)).sortby('lon')
hcst
<xarray.DataArray 't2m' (number: 25, forecastMonth: 6, start_date: 24,
lat: 180, lon: 360)> Size: 933MB
[233280000 values with dtype=float32]
Coordinates:
* number (number) int64 200B 0 1 2 3 4 5 6 7 ... 18 19 20 21 22 23 24
* forecastMonth (forecastMonth) int64 48B 1 2 3 4 5 6
* start_date (start_date) datetime64[ns] 192B 1993-02-01 ... 2016-02-01
surface float64 8B ...
* lat (lat) float64 1kB 89.5 88.5 87.5 86.5 ... -87.5 -88.5 -89.5
* lon (lon) float64 3kB -179.5 -178.5 -177.5 ... 177.5 178.5 179.5
Attributes: (12/31)
GRIB_paramId: 167
GRIB_dataType: fcmean
GRIB_numberOfPoints: 64800
GRIB_typeOfLevel: surface
GRIB_stepUnits: 1
GRIB_stepType: instant
... ...
GRIB_shortName: 2t
GRIB_totalNumber: 0
GRIB_units: K
long_name: 2 metre temperature
units: K
standard_name: unknownNow load the real-time forecast data in the same manner.
fc_path = data_path + '/' + '_'.join([var, 'mm', origin, system, fc_yr, st_mon]) + '.grib'
fcst = xr.open_dataarray(fc_path, engine='cfgrib',
backend_kwargs=dict(time_dims=('forecastMonth', st_dim_name)))
# rename indexing time or time to start date
fcst = fcst.rename({st_dim_name: 'start_date', 'longitude': 'lon', 'latitude': 'lat'})
# roll longitude
fcst = fcst.assign_coords(lon=(((fcst.lon + 180) % 360) - 180)).sortby('lon')
fcst
<xarray.DataArray 't2m' (number: 51, forecastMonth: 6, lat: 180, lon: 360)> Size: 79MB
[19828800 values with dtype=float32]
Coordinates:
* number (number) int64 408B 0 1 2 3 4 5 6 7 ... 44 45 46 47 48 49 50
* forecastMonth (forecastMonth) int64 48B 1 2 3 4 5 6
start_date datetime64[ns] 8B ...
surface float64 8B ...
* lat (lat) float64 1kB 89.5 88.5 87.5 86.5 ... -87.5 -88.5 -89.5
* lon (lon) float64 3kB -179.5 -178.5 -177.5 ... 177.5 178.5 179.5
Attributes: (12/31)
GRIB_paramId: 167
GRIB_dataType: fcmean
GRIB_numberOfPoints: 64800
GRIB_typeOfLevel: surface
GRIB_stepUnits: 1
GRIB_stepType: instant
... ...
GRIB_shortName: 2t
GRIB_totalNumber: 0
GRIB_units: K
long_name: 2 metre temperature
units: K
standard_name: unknownFor the real-time forecast array, add a ‘valid time’ coordinate, which will be useful for labeling the plots later.
valid_time = [pd.to_datetime(fcst.start_date.values) + relativedelta(months=fcmonth-1) for fcmonth in fcst.forecastMonth]
fcst = fcst.assign_coords(valid_time=('forecastMonth',valid_time))
fcst
<xarray.DataArray 't2m' (number: 51, forecastMonth: 6, lat: 180, lon: 360)> Size: 79MB
[19828800 values with dtype=float32]
Coordinates:
* number (number) int64 408B 0 1 2 3 4 5 6 7 ... 44 45 46 47 48 49 50
* forecastMonth (forecastMonth) int64 48B 1 2 3 4 5 6
start_date datetime64[ns] 8B 2024-02-01
surface float64 8B ...
* lat (lat) float64 1kB 89.5 88.5 87.5 86.5 ... -87.5 -88.5 -89.5
* lon (lon) float64 3kB -179.5 -178.5 -177.5 ... 177.5 178.5 179.5
valid_time (forecastMonth) datetime64[ns] 48B 2024-02-01 ... 2024-07-01
Attributes: (12/31)
GRIB_paramId: 167
GRIB_dataType: fcmean
GRIB_numberOfPoints: 64800
GRIB_typeOfLevel: surface
GRIB_stepUnits: 1
GRIB_stepType: instant
... ...
GRIB_shortName: 2t
GRIB_totalNumber: 0
GRIB_units: K
long_name: 2 metre temperature
units: K
standard_name: unknownSelect ensemble members#
Here select which ensemble members to use. For some lagged start systems a subset of the available ensemble members are used in the graphical products, as described in the documentation.
# for some lagged systems sub-select 'qualifying' ensemble members used in the C3S graphical products
if lagged:
max_hc = system_details['system_details'].get('ens_size', {}).get('products', {}).get('hc', 'none')
max_fc = system_details['system_details'].get('ens_size', {}).get('products', {}).get('fc', 'none')
if isinstance(max_hc, int) and hcst.sizes.get('number', 0) > max_hc:
hcst = hcst.isel(number=slice(0, max_hc))
if isinstance(max_fc, int) and fcst.sizes.get('number', 0) > max_fc:
fcst = fcst.isel(number=slice(0, max_fc))
Category based probability forecast product#
Calculate tercile boundaries#
The first step of calculating probabilities for the tercile summary is to calculate the terciles from the hindcast period.
quantiles = [1. / 3., 2. / 3.]
hcst_qbnds = hcst.quantile(quantiles, ['start_date', 'number'])
hcst_qbnds
<xarray.DataArray 't2m' (quantile: 2, forecastMonth: 6, lat: 180, lon: 360)> Size: 6MB
array([[[[245.89117432, 245.88857015, 245.88759867, ..., 245.89312744,
245.89312744, 245.8924764 ],
[245.77175903, 245.78022257, 245.79353333, ..., 245.76808167,
245.76352437, 245.76524862],
[245.79079183, 245.79378255, 245.77629598, ..., 245.81074524,
245.79404704, 245.79079183],
...,
[238.25794474, 238.44224548, 238.60303243, ..., 237.94477336,
238.04144287, 238.14217122],
[235.29316203, 235.32256063, 235.35258993, ..., 235.18936157,
235.23148092, 235.26594035],
[234.39111837, 234.40283712, 234.41404724, ..., 234.34221903,
234.35612996, 234.37994893]],
[[247.05482992, 247.0483195 , 247.04536438, ..., 247.06881205,
247.06425476, 247.05873617],
[246.97591146, 246.96875 , 246.96158854, ..., 246.96059672,
246.97166443, 246.98130798],
[246.91692098, 246.90811157, 246.90095011, ..., 246.95377604,
246.93586222, 246.92154439],
...
[227.56704203, 227.82528178, 228.03858439, ..., 227.06853231,
227.22148132, 227.3719635 ],
[223.26383972, 223.31497192, 223.35872904, ..., 223.06654358,
223.13125102, 223.20546977],
[221.84247335, 221.85394796, 221.86761983, ..., 221.8151296 ,
221.8229421 , 221.83270772]],
[[273.74724325, 273.74779256, 273.74775187, ..., 273.74832153,
273.74772135, 273.74724325],
[273.77182007, 273.76986694, 273.76898193, ..., 273.78004964,
273.77730306, 273.77390544],
[273.79667155, 273.78979492, 273.7835083 , ..., 273.80637614,
273.8040568 , 273.80225627],
...,
[226.08777873, 226.32985433, 226.56804911, ..., 225.631073 ,
225.76887004, 225.90531413],
[221.83491007, 221.89095052, 221.9313151 , ..., 221.62709045,
221.6891276 , 221.75295003],
[220.21778361, 220.23275757, 220.24708049, ..., 220.16830444,
220.1832784 , 220.20215861]]]])
Coordinates:
* forecastMonth (forecastMonth) int64 48B 1 2 3 4 5 6
* lat (lat) float64 1kB 89.5 88.5 87.5 86.5 ... -87.5 -88.5 -89.5
* lon (lon) float64 3kB -179.5 -178.5 -177.5 ... 177.5 178.5 179.5
* quantile (quantile) float64 16B 0.3333 0.6667Compute real-time forecast probabilities#
Now calculate the real-time forecast probabilities by counting the number of ensemble members above and below the upper and lower terciles.
fc_ens = fcst.sizes['number']
print(" ####### FC ENS SIZE ####### ")
print(fc_ens)
above = fcst.where(fcst > hcst_qbnds.sel(quantile=2. / 3.)).count('number')
below = fcst.where(fcst < hcst_qbnds.sel(quantile=1. / 3.)).count('number')
####### FC ENS SIZE #######
51
Now calculate probabilities for each tercile category (above, below, and normal), and combine them to create a single array to use for plotting the tercile summary.
P_above = 100. * (above / float(fc_ens))
P_below = 100. * (below / float(fc_ens))
P_normal = 100. - (P_above + P_below)
a = P_above.where(P_above > np.maximum(40. + 0 * P_above, P_below), 0.)
b = P_below.where(P_below > np.maximum(40. + 0 * P_below, P_above), 0.)
P_summary = a - b
P_summary
<xarray.DataArray 't2m' (forecastMonth: 6, lat: 180, lon: 360)> Size: 3MB
array([[[100. , 100. , 100. , ..., 100. ,
100. , 100. ],
[100. , 100. , 100. , ..., 100. ,
100. , 100. ],
[100. , 100. , 100. , ..., 100. ,
100. , 100. ],
...,
[ 58.82352941, 58.82352941, 58.82352941, ..., 58.82352941,
58.82352941, 56.8627451 ],
[ 64.70588235, 64.70588235, 64.70588235, ..., 64.70588235,
64.70588235, 64.70588235],
[ 52.94117647, 52.94117647, 52.94117647, ..., 52.94117647,
52.94117647, 52.94117647]],
[[ 72.54901961, 72.54901961, 72.54901961, ..., 72.54901961,
72.54901961, 72.54901961],
[ 76.47058824, 76.47058824, 76.47058824, ..., 76.47058824,
76.47058824, 76.47058824],
[ 78.43137255, 78.43137255, 78.43137255, ..., 76.47058824,
76.47058824, 76.47058824],
...
[ 50.98039216, 50.98039216, 50.98039216, ..., 52.94117647,
52.94117647, 50.98039216],
[ 50.98039216, 50.98039216, 52.94117647, ..., 50.98039216,
50.98039216, 50.98039216],
[ 0. , 0. , 0. , ..., 0. ,
0. , 0. ]],
[[ 0. , 0. , 0. , ..., 0. ,
0. , 0. ],
[ 43.1372549 , 43.1372549 , 41.17647059, ..., 41.17647059,
41.17647059, 43.1372549 ],
[ 41.17647059, 41.17647059, 41.17647059, ..., 0. ,
0. , 41.17647059],
...,
[ 52.94117647, 52.94117647, 52.94117647, ..., 50.98039216,
52.94117647, 52.94117647],
[ 52.94117647, 50.98039216, 52.94117647, ..., 52.94117647,
52.94117647, 52.94117647],
[ 50.98039216, 50.98039216, 50.98039216, ..., 50.98039216,
50.98039216, 50.98039216]]])
Coordinates:
* forecastMonth (forecastMonth) int64 48B 1 2 3 4 5 6
start_date datetime64[ns] 8B 2024-02-01
surface float64 8B 0.0
* lat (lat) float64 1kB 89.5 88.5 87.5 86.5 ... -87.5 -88.5 -89.5
* lon (lon) float64 3kB -179.5 -178.5 -177.5 ... 177.5 178.5 179.5
valid_time (forecastMonth) datetime64[ns] 48B 2024-02-01 ... 2024-07-01Plot tercile summary#
Here set up a directory for saving the plots, and set up some plot parameters.
# levels to use when shading the plot, and corresponding colours
contour_levels = [-100., -70., -60., -50., -40., 40., 50., 60., 70., 100.]
contour_colours = ["navy", "blue", "deepskyblue", "cyan", "white", "yellow", "orange", "orangered", "tab:red"]
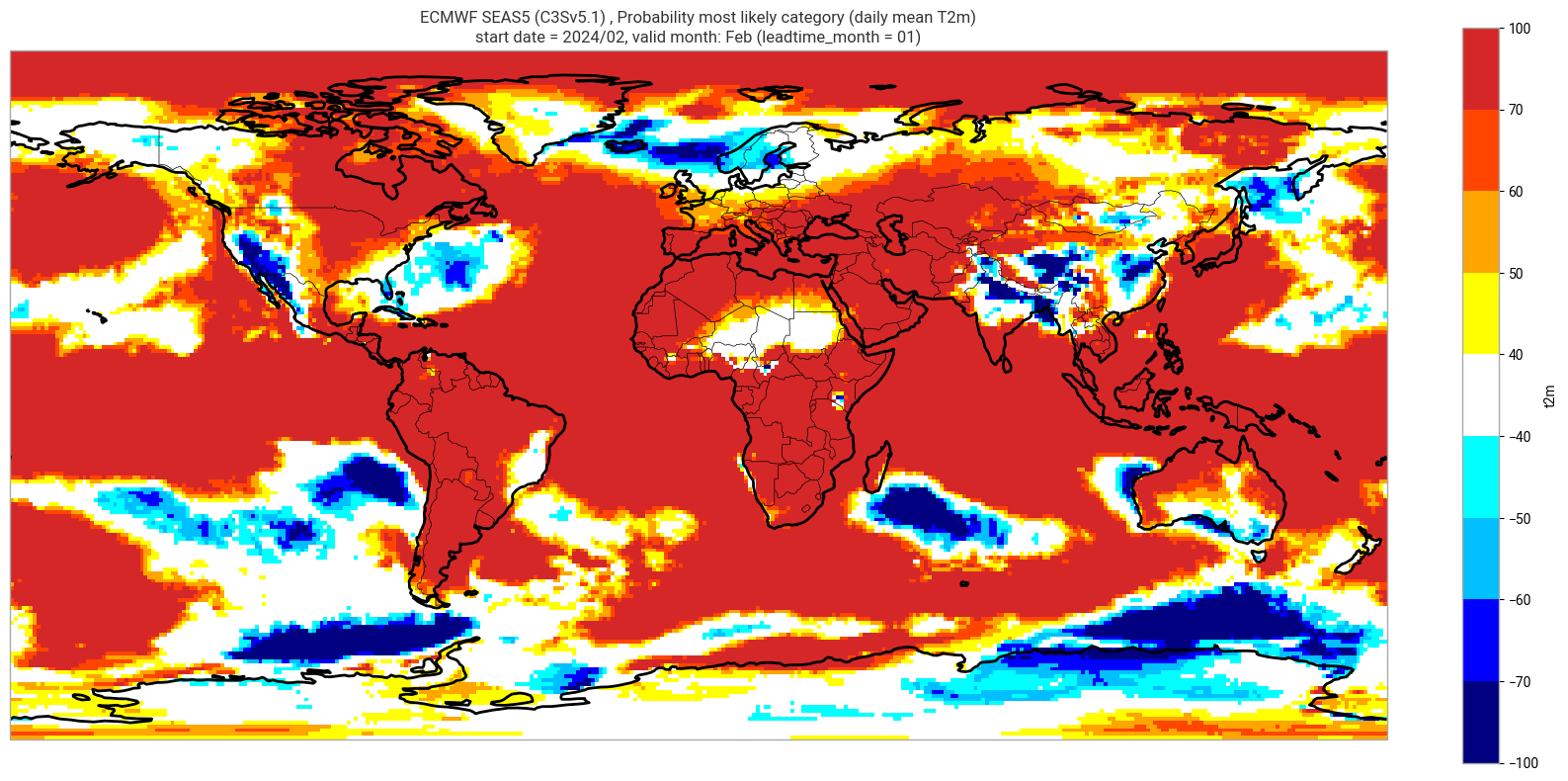
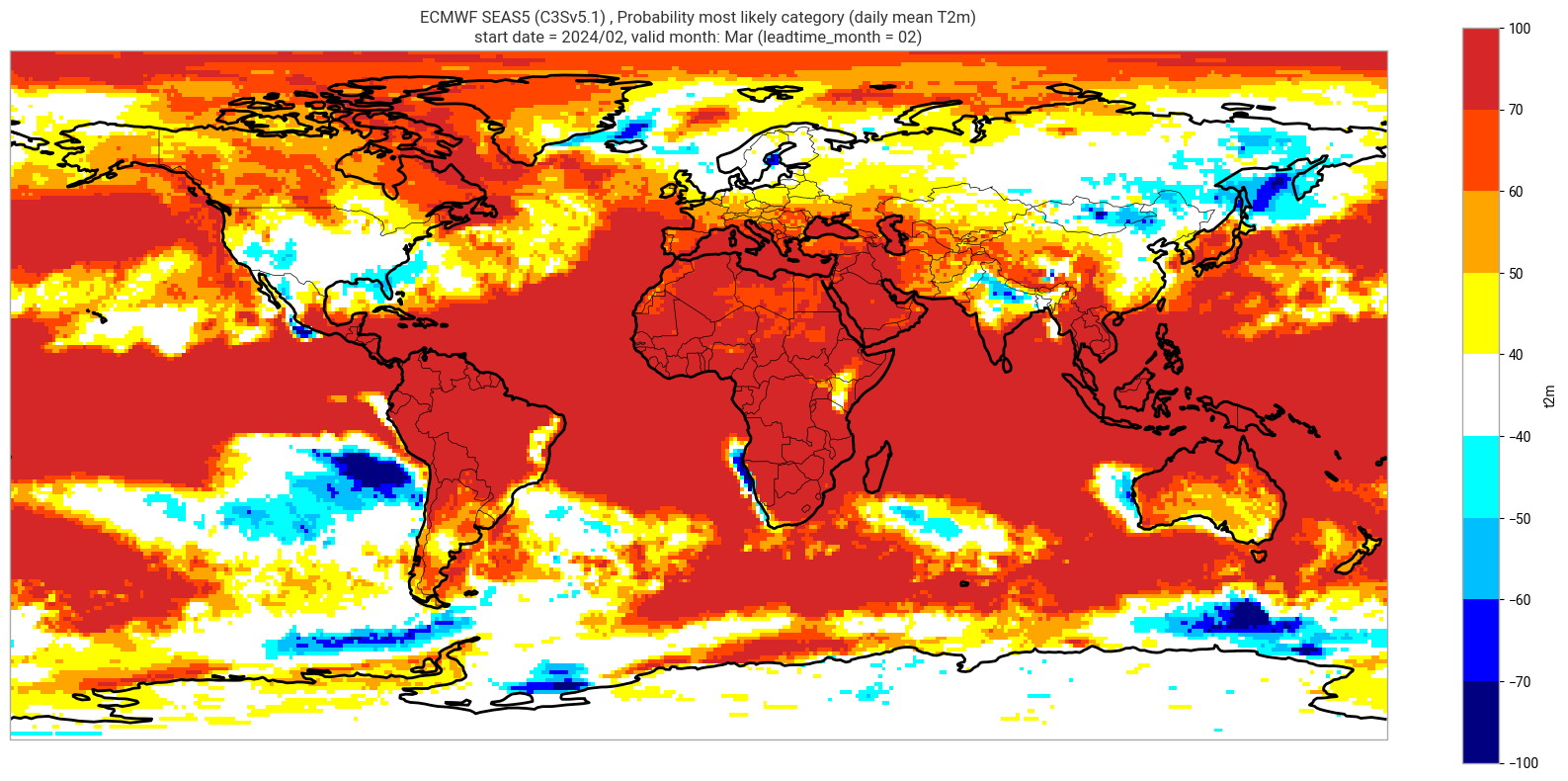
Reproduce the C3S seasonal charts tercile summary plot, which shows if either the upper or lower category has a probability which exceeds 40%. The white areas of the plot mean either that the middle category is the most probable, or that all categories have similar probabilities. The plot is also explained in the chart caption, and the corresponding description in the C3S seasonal product descriptions page.
Note: the C3S graphical products are contour plots rather than the grid mesh plots below.
orig_label = system_details.get('origin_details',{}).get('label','UnknownOrigin')
sys_name = system_details.get('system_details',{}).get('name','UnknownSystem')
for ltm in lt_mons:
plot_data = P_summary.sel(forecastMonth=ltm) # extract the specific real-time forecast month
# clip the data to sit within levels range
plot_data = plot_data.clip(min=-99, max=99)
valid_time = pd.to_datetime(plot_data.valid_time.values)
vm_str = valid_time.strftime('%b') # valid month string to label the plot
sys_txt = f'{orig_label} {sys_name} '
title_txt1 = sys_txt + f', Probability most likely category ({var_str})'
title_txt2 = f'start date = {fc_yr}/{st_mon}, valid month: {vm_str} (leadtime_month = {ltm:02})'
fig = plt.figure(figsize=(16, 8))
ax = plt.axes(projection=ccrs.PlateCarree())
ax.add_feature(cfeature.BORDERS, edgecolor='black', linewidth=0.5)
ax.add_feature(cfeature.COASTLINE, edgecolor='black', linewidth=2.)
plot_data.plot(levels=contour_levels, colors=contour_colours,
cbar_kwargs={'fraction': 0.033, 'extend': 'neither'})
plt.title(title_txt1 + '\n' + title_txt2)
plt.tight_layout()
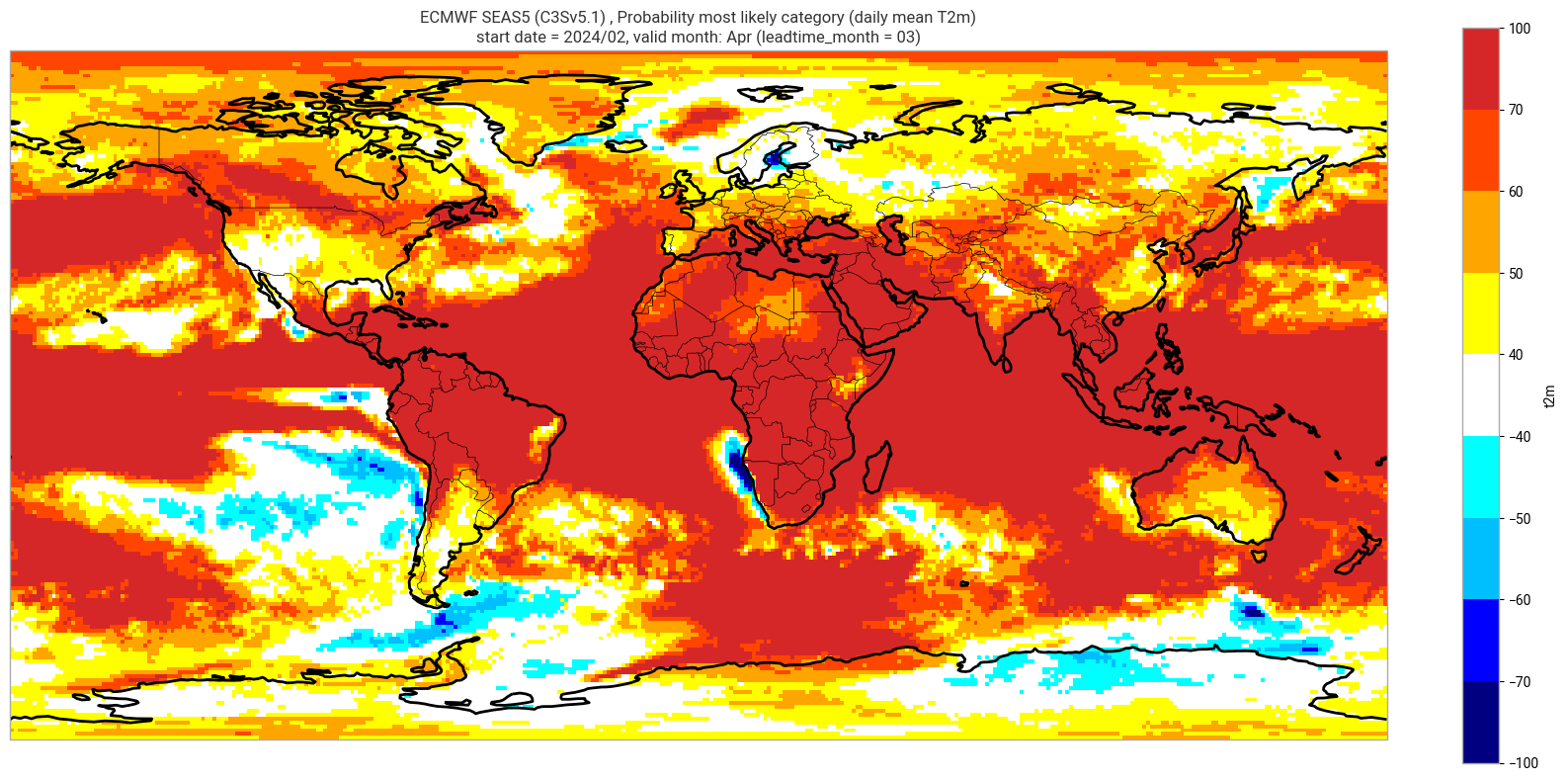
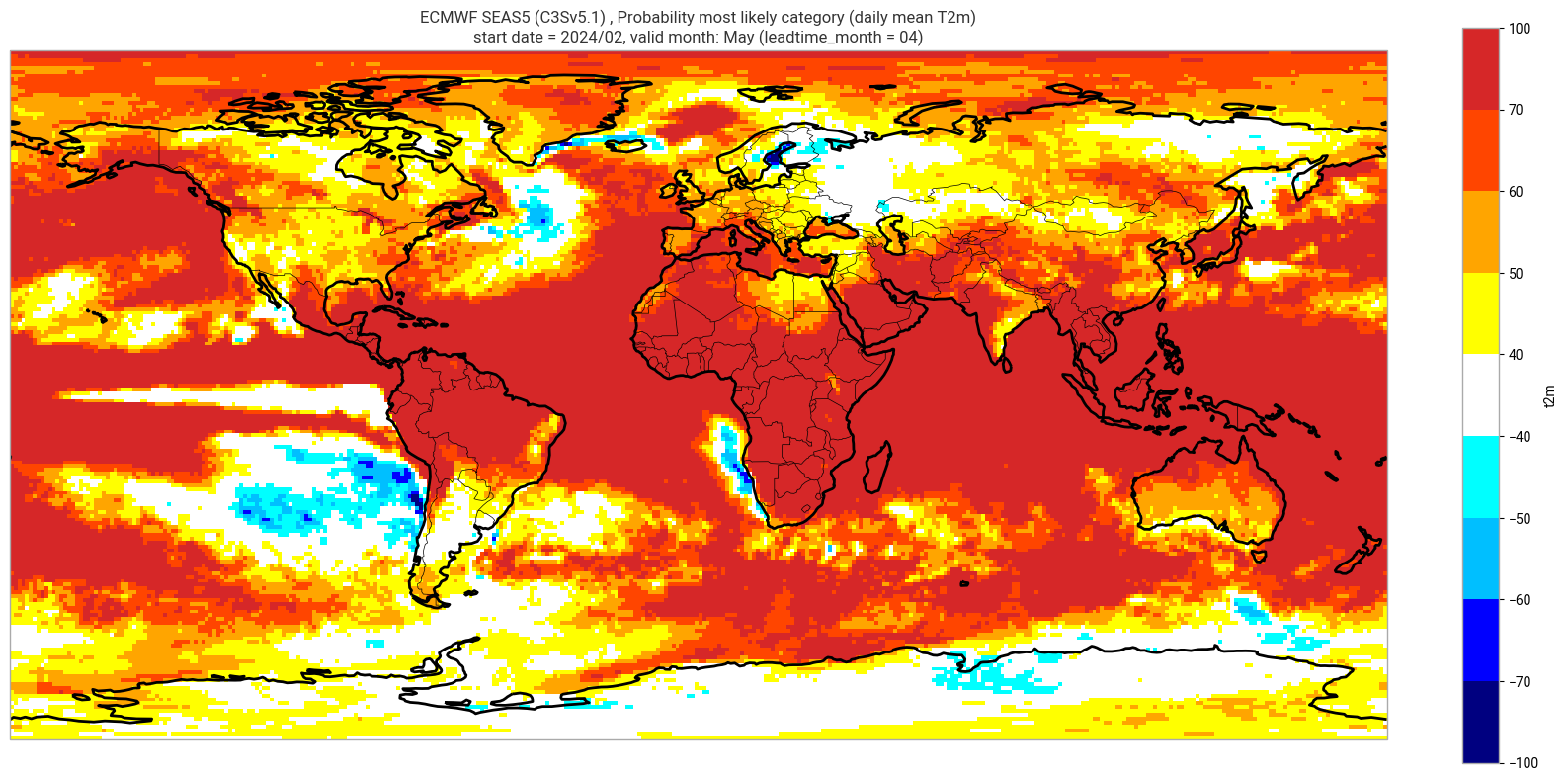
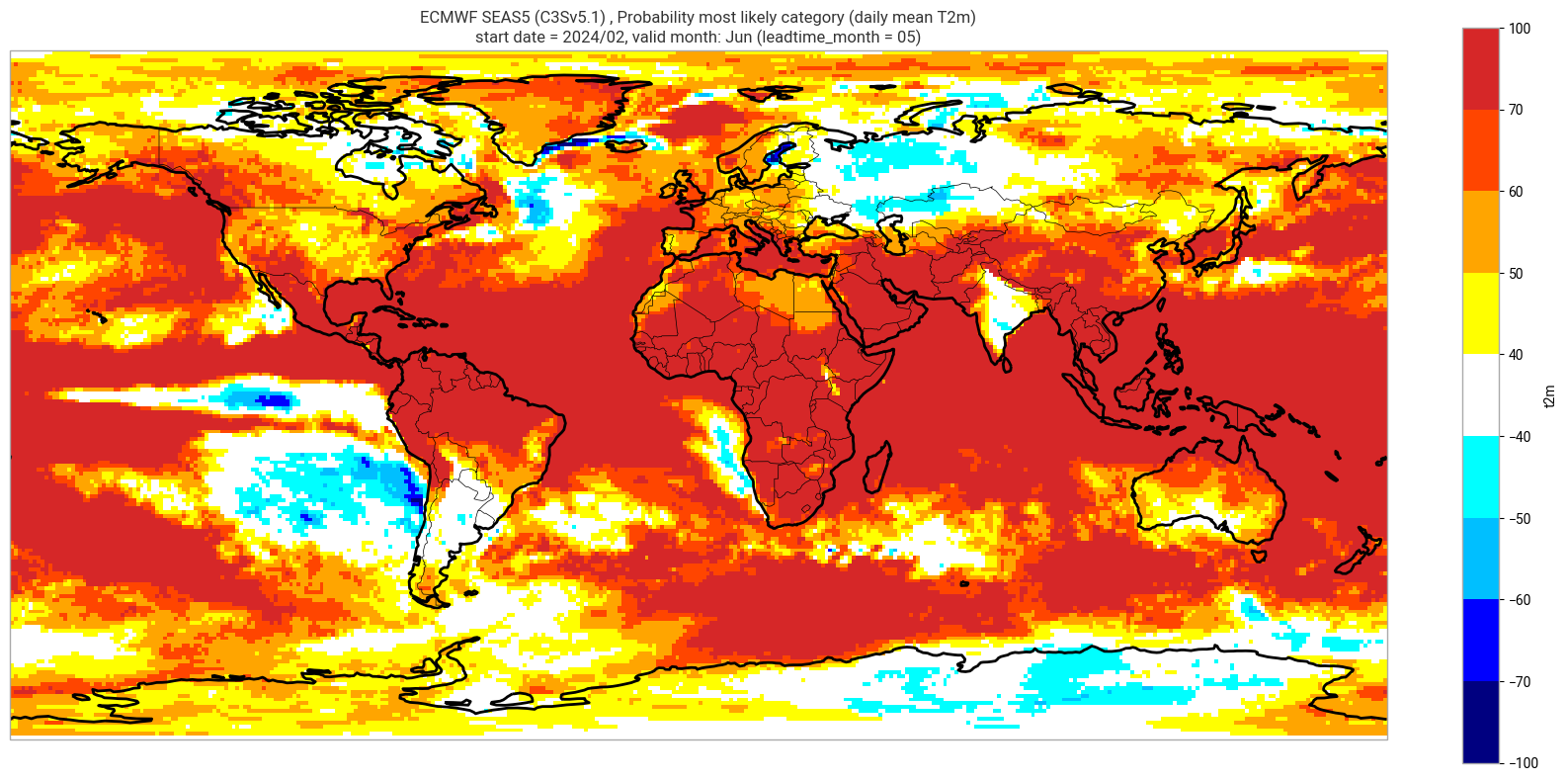
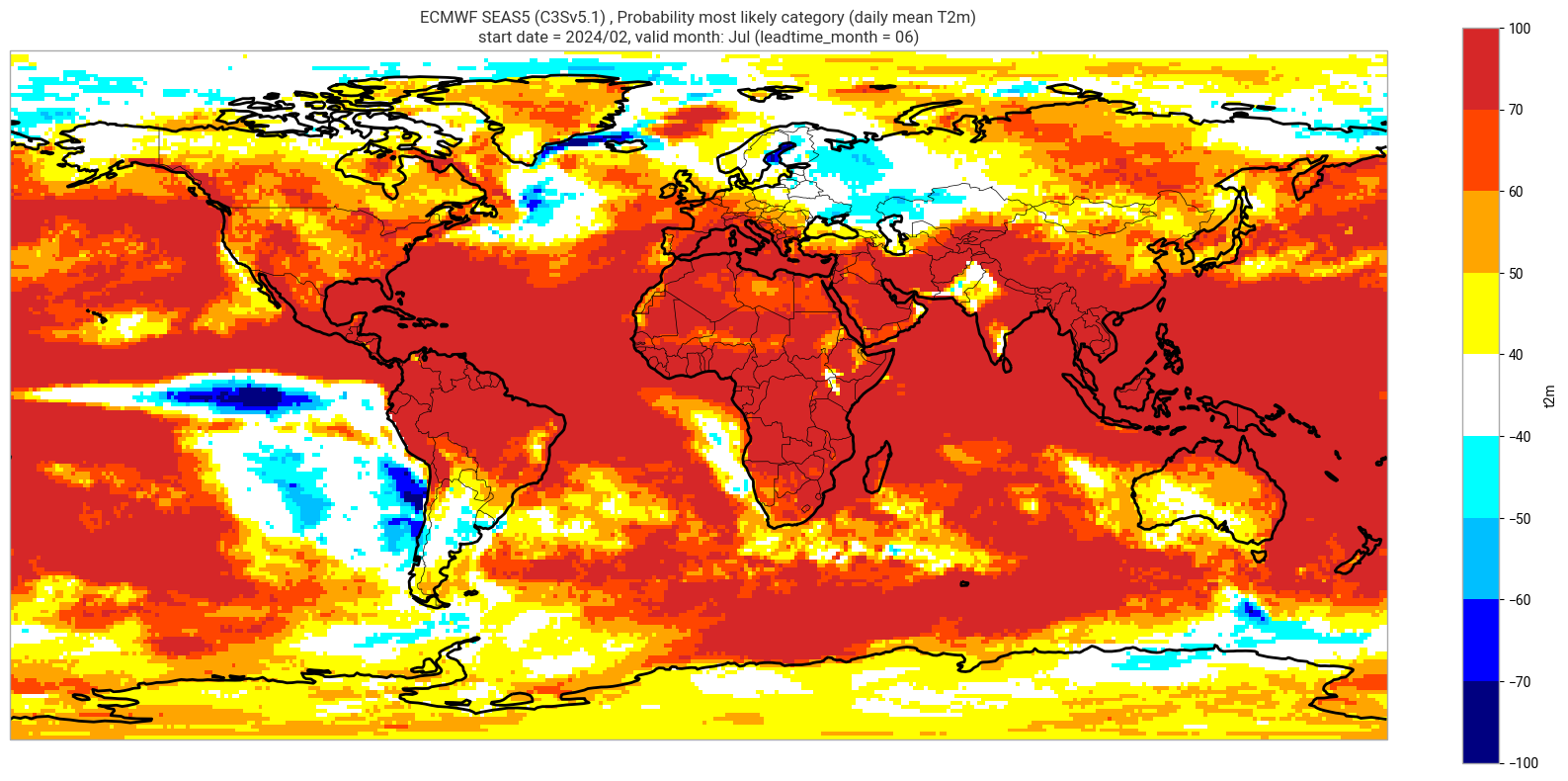
Deterministic forecast product#
Compute ensemble mean real-time forecast anomaly#
Calculate the ensemble mean anomaly using the real-time forecast array and the hindcast array.
hcst_clim = hcst.mean(['start_date', 'number']) # mean climatology, over start years and ensemble members, for each lead time for the chosen start month
fcst_anom = fcst - hcst_clim
fcst_anom_mean = fcst_anom.mean(['number'])
fcst_anom_mean
<xarray.DataArray 't2m' (forecastMonth: 6, lat: 180, lon: 360)> Size: 2MB
array([[[ 5.9437885e+00, 5.9465756e+00, 5.9492173e+00, ...,
5.9372778e+00, 5.9394183e+00, 5.9414916e+00],
[ 5.5511594e+00, 5.5556259e+00, 5.5601540e+00, ...,
5.5449376e+00, 5.5464611e+00, 5.5481291e+00],
[ 5.1224976e+00, 5.1268730e+00, 5.1316385e+00, ...,
5.1071410e+00, 5.1126575e+00, 5.1180587e+00],
...,
[ 1.0351394e+00, 1.0224998e+00, 1.0101564e+00, ...,
1.0523508e+00, 1.0476738e+00, 1.0433774e+00],
[ 1.0846686e+00, 1.0816010e+00, 1.0786606e+00, ...,
1.0824513e+00, 1.0837929e+00, 1.0855495e+00],
[ 7.7852225e-01, 7.7736741e-01, 7.7659458e-01, ...,
7.8039014e-01, 7.7970856e-01, 7.7939469e-01]],
[[ 1.9754519e+00, 1.9729198e+00, 1.9702654e+00, ...,
1.9836866e+00, 1.9808948e+00, 1.9778736e+00],
[ 1.8911563e+00, 1.8884836e+00, 1.8860707e+00, ...,
1.9037868e+00, 1.8993350e+00, 1.8946767e+00],
[ 1.8090264e+00, 1.8068606e+00, 1.8050705e+00, ...,
1.8172027e+00, 1.8142099e+00, 1.8113071e+00],
...
[ 9.0033227e-01, 8.9601374e-01, 8.9155221e-01, ...,
9.1310686e-01, 9.0883714e-01, 9.0460026e-01],
[ 7.6888019e-01, 7.6831865e-01, 7.6764631e-01, ...,
7.6306748e-01, 7.6553613e-01, 7.6796979e-01],
[ 2.8198990e-01, 2.8258589e-01, 2.8312713e-01, ...,
2.7548039e-01, 2.7802113e-01, 2.8073928e-01]],
[[-5.6104474e-03, -5.6307926e-03, -5.9114345e-03, ...,
-4.3640137e-03, -4.8648608e-03, -5.3423713e-03],
[-1.6802619e-03, -1.7401003e-03, -2.1134920e-03, ...,
-8.1140856e-04, -1.1608647e-03, -1.2350644e-03],
[ 7.5647691e-03, 7.0920456e-03, 6.6133388e-03, ...,
8.3031747e-03, 8.3893416e-03, 8.3450619e-03],
...,
[ 9.7371930e-01, 9.7202647e-01, 9.6994525e-01, ...,
9.7838849e-01, 9.7706395e-01, 9.7543573e-01],
[ 9.7090656e-01, 9.6740693e-01, 9.6420258e-01, ...,
9.7612810e-01, 9.7480953e-01, 9.7327346e-01],
[ 7.9503769e-01, 7.9385316e-01, 7.9259956e-01, ...,
7.9664165e-01, 7.9609293e-01, 7.9598129e-01]]], dtype=float32)
Coordinates:
* forecastMonth (forecastMonth) int64 48B 1 2 3 4 5 6
start_date datetime64[ns] 8B 2024-02-01
surface float64 8B 0.0
* lat (lat) float64 1kB 89.5 88.5 87.5 86.5 ... -87.5 -88.5 -89.5
* lon (lon) float64 3kB -179.5 -178.5 -177.5 ... 177.5 178.5 179.5
valid_time (forecastMonth) datetime64[ns] 48B 2024-02-01 ... 2024-07-01Save the ensemble mean anomaly for possible future use.
save_name = '_'.join([var, origin, system, fc_yr, st_mon, 'ensmean_anom.nc'])
fcst_anom_mean.to_netcdf(os.sep.join([data_path, save_name]))
Plot ensemble mean anomaly#
Note, the level values will need to be updated for variables other than Tmin/Tmax/Tmean.
contour_levels = [-2., -1.5, -1., -0.5, -0.2, 0.2, 0.5, 1.0, 1.5, 2.0]
contour_colours = ["navy", "blue", "deepskyblue", "cyan", "white", "yellow", "orange", "orangered", "tab:red"]
# clip the data to -2 and 2
fcst_anom_mean = fcst_anom_mean.clip(min=-1.99, max=1.99)
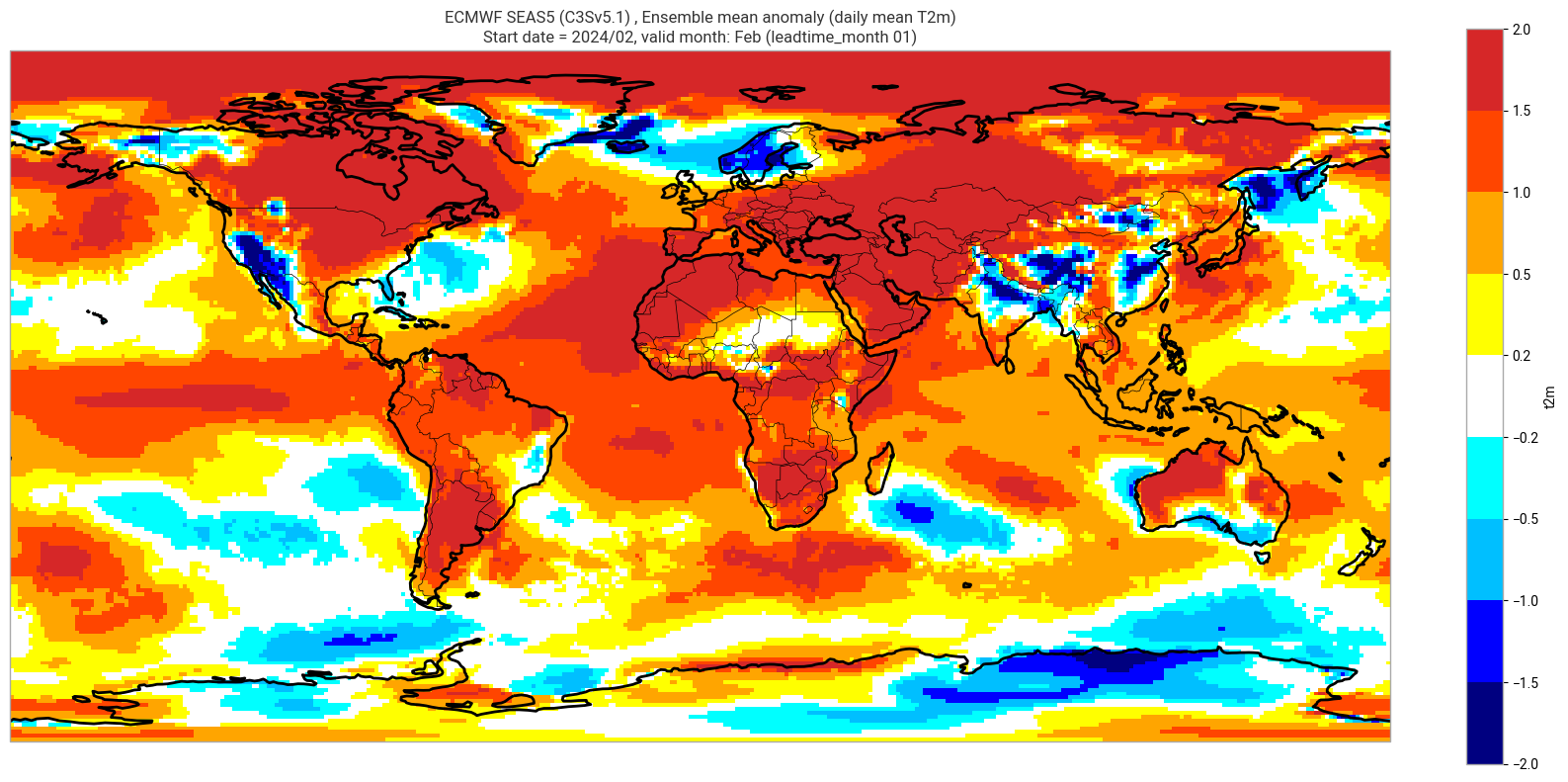
Make a basic plot for one lead month#
We plot the ensemble mean anomaly for the first real-time forecast month. Here no significance testing is applied, this will be added in the next step, so this plot is just to demonstrate the difference this makes.
ltm = 1
plot_data = fcst_anom_mean.sel(forecastMonth=ltm) # extract the specific real-time forecast month
valid_time = pd.to_datetime(plot_data.valid_time.values)
vm_str = valid_time.strftime('%b') # valid month string to label the plot
title_txt1 = sys_txt + f', Ensemble mean anomaly ({var_str})'
title_txt2 = f'Start date = {fc_yr}/{st_mon}, valid month: {vm_str} (leadtime_month = {ltm:02})'
fig = plt.figure(figsize=(16, 8))
ax = plt.axes(projection=ccrs.PlateCarree())
ax.add_feature(cfeature.BORDERS, edgecolor='black', linewidth=0.5)
ax.add_feature(cfeature.COASTLINE, edgecolor='black', linewidth=2.)
plot_data.plot(levels=contour_levels, colors=contour_colours,
cbar_kwargs={'fraction': 0.033, 'extend': 'neither'})
plt.title(title_txt1 + '\n' + title_txt2)
plt.tight_layout()
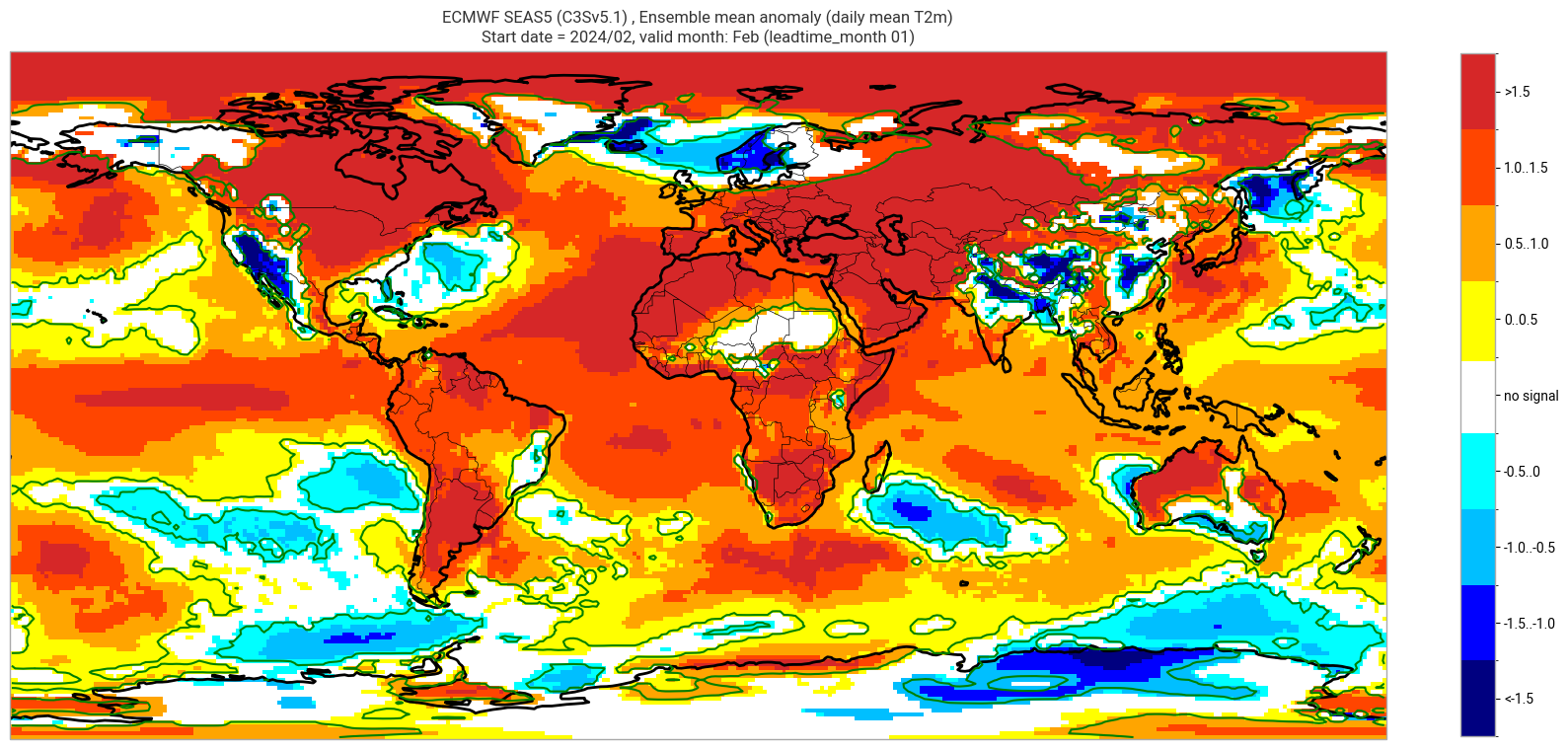
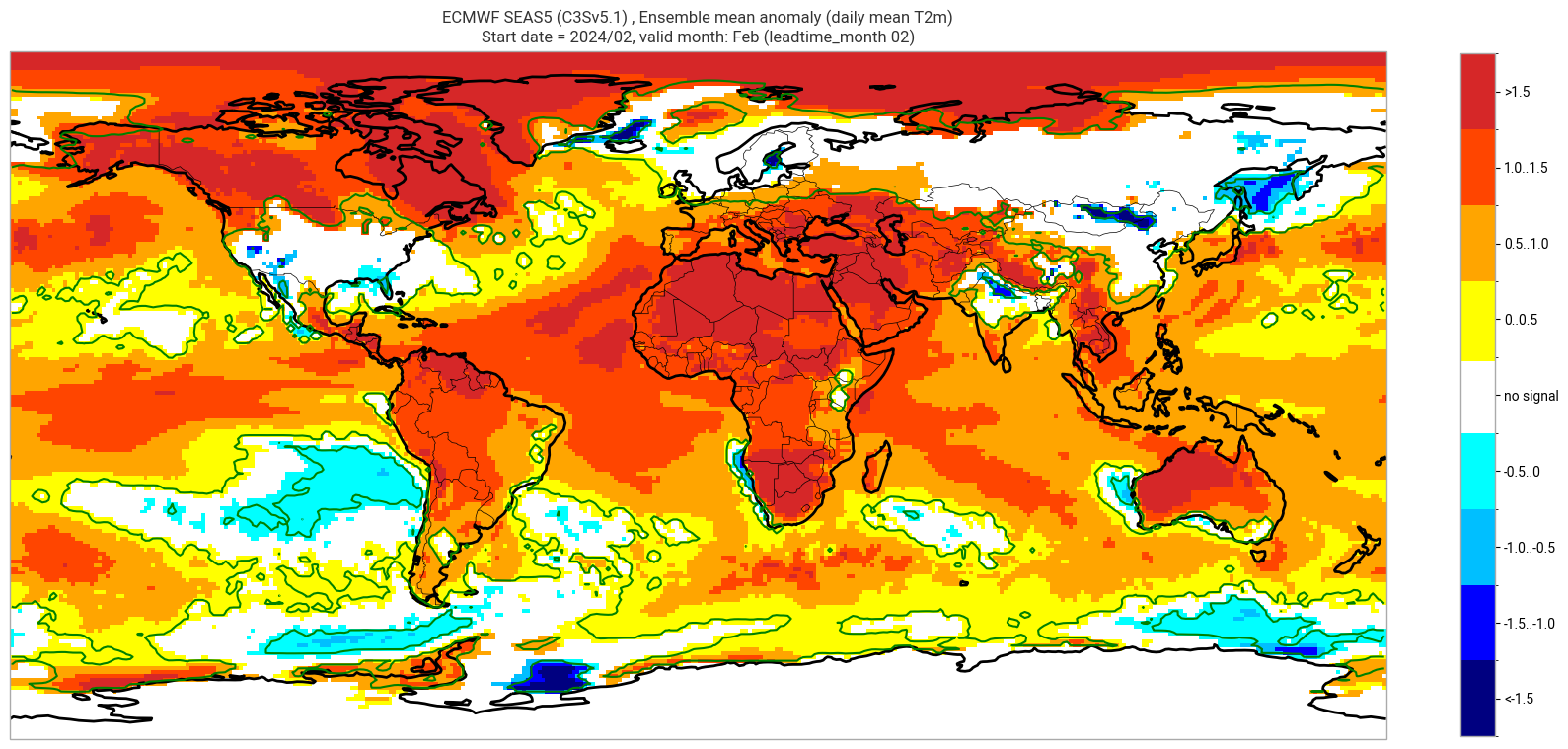
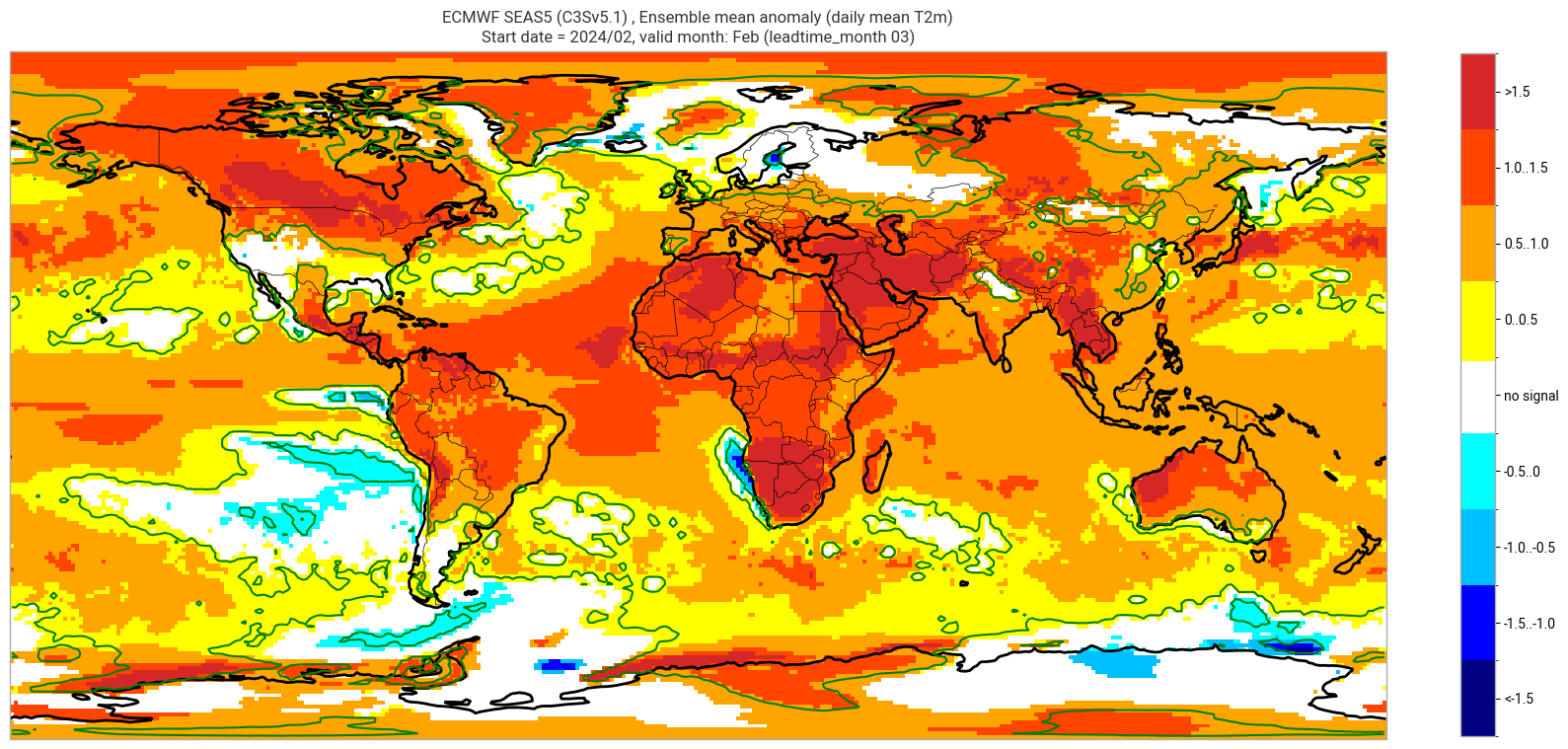
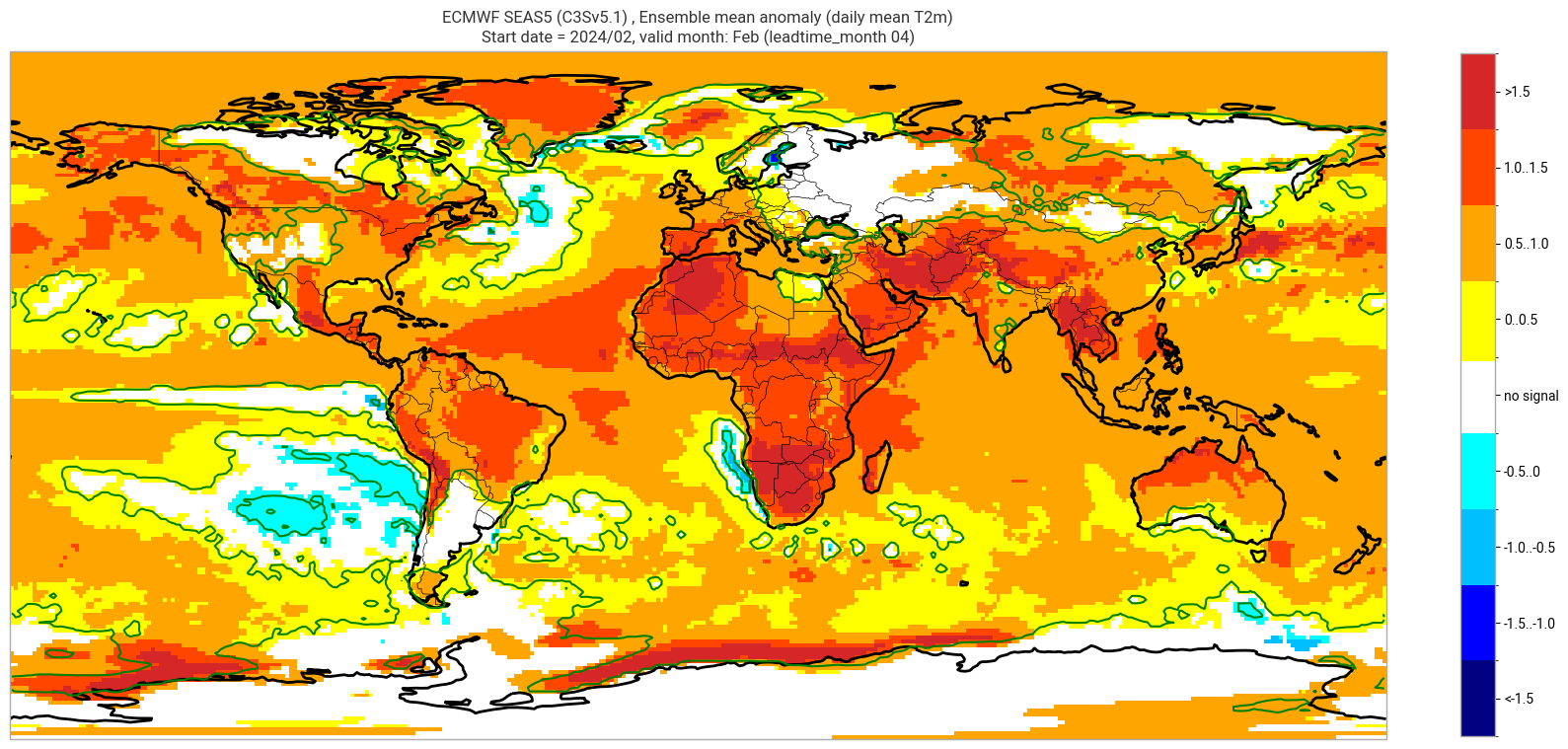
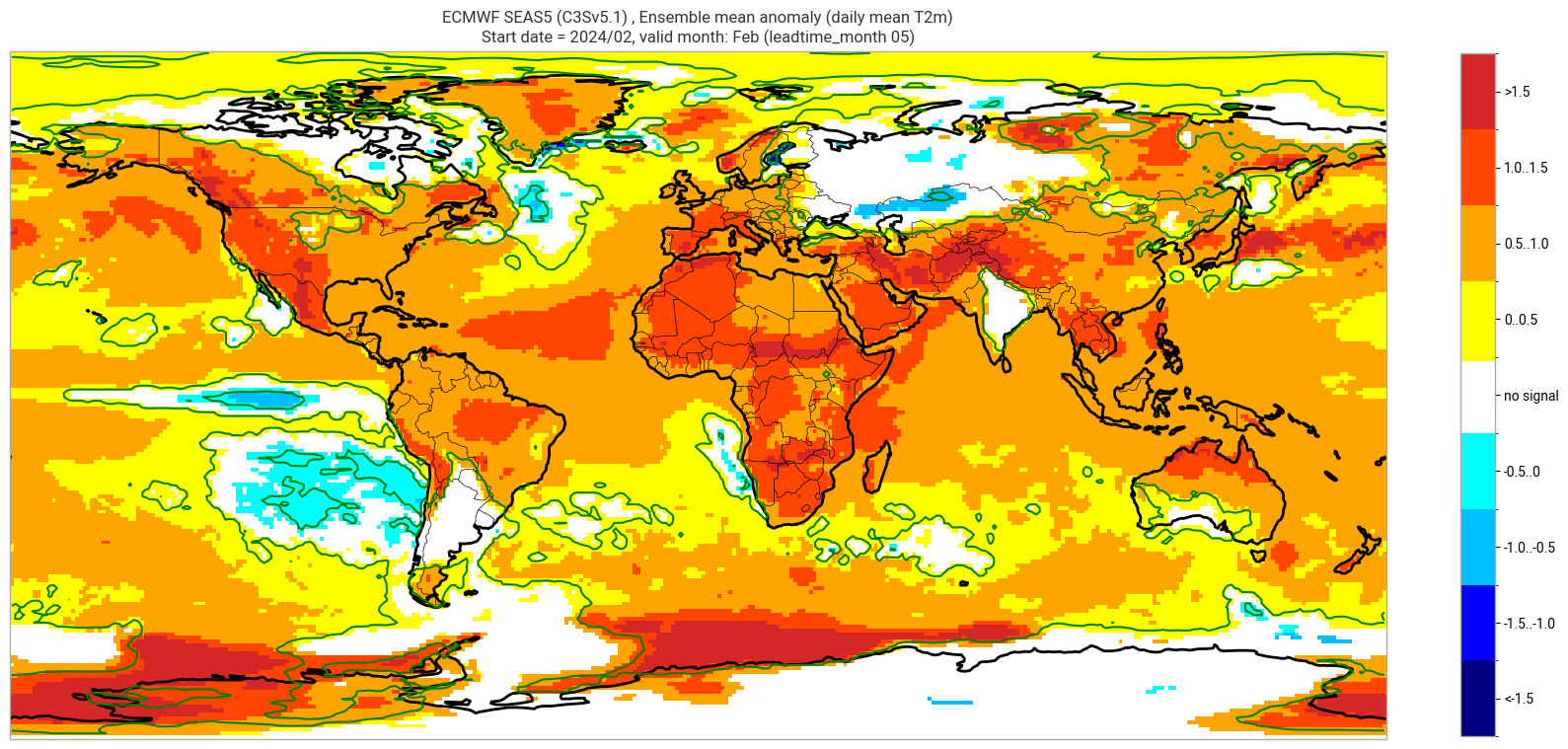
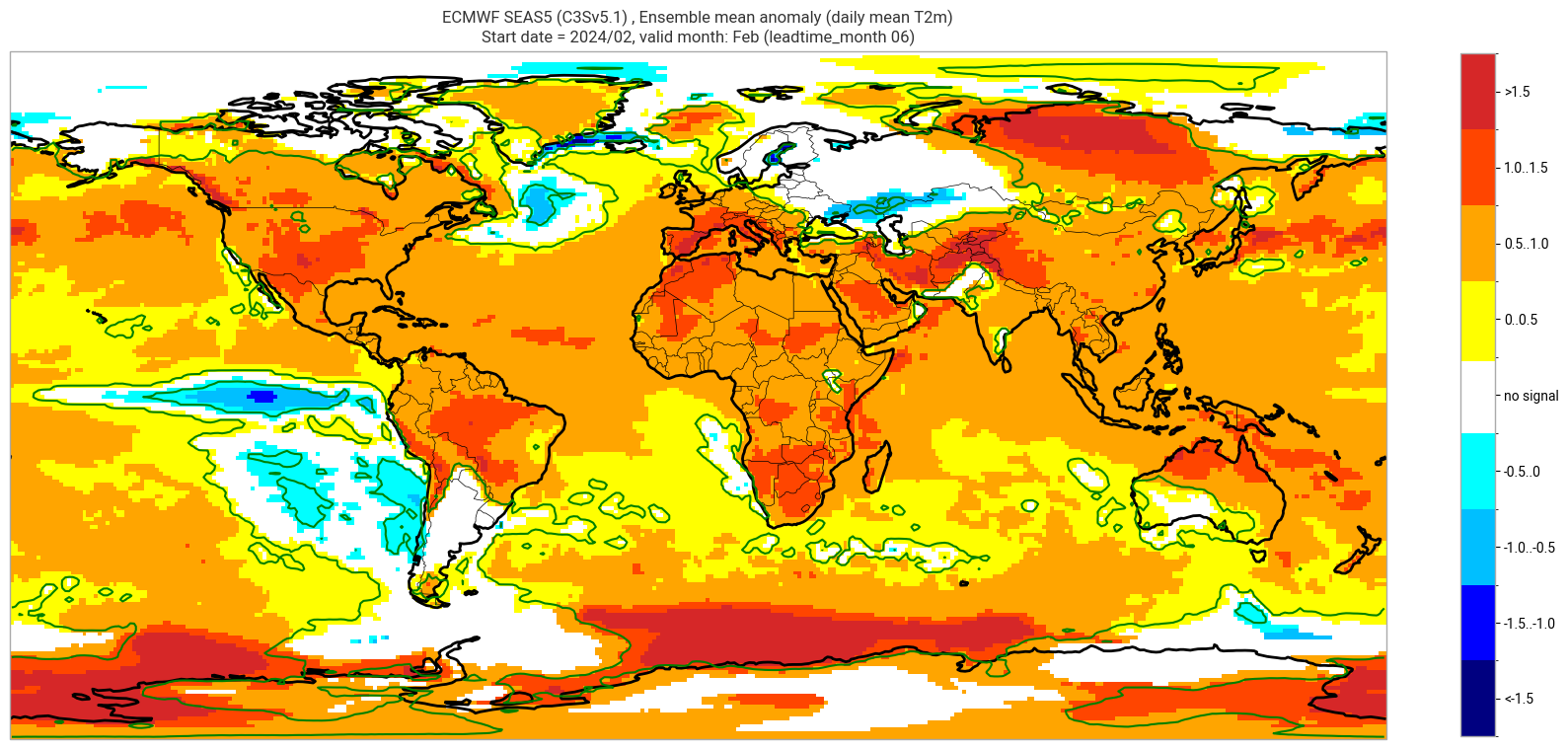
Add significance contours and masking#
The single-system ensemble mean plots in the C3S seasonal graphical products also include significance testing, following the approach taken for SEAS5 products (see https://www.ecmwf.int/sites/default/files/medialibrary/2017-10/System5_guide.pdf). Anomaly values below the 10% significance level are masked out, and significance contours are drawn for 1% and 10%. Note, due to the significance testing this cell takes longer to run than the previous one. Note that the colorbar requires customisation to represent the masking in a similar manner to the graphical products. The plot is also explained in the C3S chart caption, and the corresponding description in the C3S seasonal product descriptions page.
The first plot may be compared to the plot above, to see the difference the significance masking makes.
These plots, and the tercile summary plots above, are similar to the monthly C3S graphical product charts. Note that here we have plotted the first month of the real-time forecast (February, or leadtime_month = 1), while in the graphical products we show the monthly real-time forecasts starting with the month following the release month (which would be March in this case). The three-month aggregations shown in the graphical products could be created in a similar manner, by combining the corresponding monthly means, and then proceeding as above.
# Import function for non-paired rank-sum test
from scipy.stats import mannwhitneyu
# Significance thresholds
pval_thresh_low = 0.1
pval_thresh_high = 0.01
for ltm in lt_mons:
data1 = hcst.sel(forecastMonth=ltm)
data2 = fcst.sel(forecastMonth=ltm)
# need to flatten number and start date to 'samples'
# proceed in numpy for simplicity
data1 = data1.data # includes member and start date
data2 = data2.data # includes member
# flatten sample dimensions
data1 = data1.reshape(-1, *data1.shape[-2:]) # lat lon are the last dimensions
print('Flattened forecasts: ', data1.shape)
# non-paired approach, need to use Mann–Whitney U test
pvals2 = mannwhitneyu(data1, data2)
pvals2.pvalue
masked_anom_mean = fcst_anom_mean.sel(forecastMonth=ltm).where(pvals2.pvalue <= 0.1)
# specific values for Tmax, adjusted to add a dummy white section to label as 'no signal'
contour_levels = [-2., -1.5, -1., -0.5, -1e-15, 1e-15, 0.5, 1.0, 1.5, 2.0] # dummy values to plot central white portion in colorbar
cbar_colours = ["navy", "blue", "deepskyblue", "cyan", "white", "yellow", "orange", "orangered", "tab:red"]
cbar_labels = ["<-1.5", "-1.5..-1.0", "-1.0..-0.5", "-0.5..0", "no signal", "0..0.5", "0.5..1.0", "1.0..1.5", ">1.5"]
valid_time = pd.to_datetime(plot_data.valid_time.values)
vm_str = valid_time.strftime('%b') # valid month string to label the plot
title_txt1 = sys_txt + f', Ensemble mean anomaly ({var_str})'
title_txt2 = f'Start date = {fc_yr}/{st_mon}, valid month: {vm_str} (leadtime_month = {ltm:02})'
print(title_txt1)
print(title_txt2)
fig = plt.figure(figsize=(16, 8))
ax = plt.axes(projection=ccrs.PlateCarree())
ax.add_feature(cfeature.BORDERS, edgecolor='black', linewidth=0.5)
ax.add_feature(cfeature.COASTLINE, edgecolor='black', linewidth=2.)
im = masked_anom_mean.plot(levels=contour_levels, colors=cbar_colours, add_colorbar=False)
cbar = plt.colorbar(im, fraction=0.023, extend='neither', ticks=[-1.75, -1.25, -0.75, -0.25, 0, 0.25, 0.75, 1.25, 1.75])
cbar.ax.set_yticklabels(cbar_labels)
plt.contour(masked_anom_mean.lon.values, masked_anom_mean.lat.values, pvals2.pvalue, levels=[0.01], colors='green')
plt.title(title_txt1 + '\n' + title_txt2)
plt.tight_layout()
Flattened forecasts: (600, 180, 360)
ECMWF SEAS5 (C3Sv5.1) , Ensemble mean anomaly (daily mean T2m)
Start date = 2024/02, valid month: Feb (leadtime_month 01)
Flattened forecasts: (600, 180, 360)
ECMWF SEAS5 (C3Sv5.1) , Ensemble mean anomaly (daily mean T2m)
Start date = 2024/02, valid month: Feb (leadtime_month 02)
Flattened forecasts: (600, 180, 360)
ECMWF SEAS5 (C3Sv5.1) , Ensemble mean anomaly (daily mean T2m)
Start date = 2024/02, valid month: Feb (leadtime_month 03)
Flattened forecasts: (600, 180, 360)
ECMWF SEAS5 (C3Sv5.1) , Ensemble mean anomaly (daily mean T2m)
Start date = 2024/02, valid month: Feb (leadtime_month 04)
Flattened forecasts: (600, 180, 360)
ECMWF SEAS5 (C3Sv5.1) , Ensemble mean anomaly (daily mean T2m)
Start date = 2024/02, valid month: Feb (leadtime_month 05)
Flattened forecasts: (600, 180, 360)
ECMWF SEAS5 (C3Sv5.1) , Ensemble mean anomaly (daily mean T2m)
Start date = 2024/02, valid month: Feb (leadtime_month 06)