

7.2. Consistency between the C3S Atlas dataset and its origins: Multiple indicators#
Production date: 2025-10-01.
Dataset version: 2.0.
Produced by: Olivier Burggraaff, Nicole Reynolds (National Physical Laboratory).
🌍 Use case: Retrieving climate indicators from the Copernicus Interactive Climate Atlas#
❓ Quality assessment question#
Are the climate indicators in the dataset underpinning the Copernicus Interactive Climate Atlas consistent with their origin datasets?
Can the dataset underpinning the Copernicus Interactive Climate Atlas be reproduced from its origin datasets?
The Copernicus Interactive Climate Atlas, or C3S Atlas for short, is a C3S web application providing an easy-to-access tool for exploring climate projections, reanalyses, and observational data [Gutiérrez+24]. Version 2.0 of the application allows the user to interact with 12 datasets:
Type |
Dataset |
|---|---|
Climate Projection |
CMIP6 |
Climate Projection |
CMIP5 |
Climate Projection |
CORDEX-CORE |
Climate Projection |
CORDEX-EUR-11 |
Reanalysis |
ERA5 |
Reanalysis |
ERA5-Land |
Reanalysis |
ORAS5 |
Reanalysis |
CERRA |
Observations |
E-OBS |
Observations |
BERKEARTH |
Observations |
CPC |
Observations |
SST-CCI |
These datasets are provided through an intermediary dataset, the Gridded dataset underpinning the Copernicus Interactive Climate Atlas or C3S Atlas dataset for short [C3S Atlas dataset]. Compared to their origins, the versions of the climate datasets within the C3S Atlas dataset have been processed following the workflow in Figure 7.2.1.

Fig. 7.2.1 Schematic representation of the workflow for the production of the C3S Atlas dataset from its origin datasets, from the User-tools for the C3S Atlas.#
Because a wide range of users interact with climate data through the C3S Atlas application, it is crucial that the underpinning dataset represent its origins correctly. In other words, the C3S Atlas dataset must be consistent with and reproducible from its origins. Here, we assess this consistency and reproducibility by comparing climate indicators retrieved from the C3S Atlas dataset with their equivalents calculated from the origin dataset, mirroring the workflow from Figure 7.2.1. While a full analysis and reproduction of every record within the C3S Atlas dataset is outside the scope of quality assessment (and would require high-performance computing infrastructure), a case study with a narrower scope probes these quality attributes of the dataset and can be a jumping-off point for further analysis by the reader.
This notebook is part of a series:
Notebook |
Contents |
|---|---|
Consistency between the C3S Atlas dataset and its origins: Case study |
Comparison between C3S Atlas dataset and one origin dataset (CMIP6) for one indicator ( |
Consistency between the C3S Atlas dataset and its origins: Multiple indicators |
Comparison between C3S Atlas dataset and one origin dataset (CMIP6) for multiple indicators. |
Consistency between the C3S Atlas dataset and its origins: Multiple origin datasets |
Comparison between C3S Atlas dataset and multiple origin datasets for one indicator. |
📢 Quality assessment statement#
These are the key outcomes of this assessment
Climate indicators (here 25 monthly indicators) provided by the C3S Atlas dataset are highly consistent with values calculated from its origin datasets (here the CMIP6 multi-model ensemble).
There are some differences in coverage between the C3S Atlas dataset and its origins due to deliberate masking, e.g. agricultural indicators in the Arctic circle, but these do not affect the vast majority use cases for the C3S Atlas.
Differences between the C3S Atlas dataset and a manual reproduction are rare and generally negligible (median absolute difference ≤0.02% for all but 2 indicators). Where differences occur, they can be explained by details of the workflow implementation or deliberate choices.
The C3S Atlas is traceable and reproducible, and can be confidently used to view, analyse, and download climate data.
For specific use cases, like scientific papers, it is recommended to manually process the origin dataset instead of using the C3S Atlas. This is not necessary for other use cases, such as climate risk assessments and climate reports, in which case the C3S Atlas can be used as is.
📋 Methodology#
This quality assessment tests the consistency between climate indicators retrieved from the Gridded dataset underpinning the Copernicus Interactive Climate Atlas [C3S Atlas dataset] and their equivalents calculated from the origin datasets, as well as the reproducibility of said dataset.
This notebook expands the analysis set out in the case study to investigate multiple indicators (listed below, descriptions from the User-tools for the C3S Atlas) derived from the CMIP6 multi-model ensemble [CMIP6 dataset]:
Indicator |
Unit |
Full description |
|---|---|---|
|
°C |
Monthly mean of daily mean near-surface (2-metre) air temperature |
|
°C |
Monthly mean of daily minimum near-surface (2-metre) air temperature |
|
°C |
Monthly mean of daily maximum near-surface (2-metre) air temperature |
|
°C |
Monthly mean of near-surface (2-metre) air temperature difference between the maximum and minimum daily temperature |
|
°C |
Monthly minimum of daily minimum near-surface (2-metre) air temperature |
|
°C |
Monthly maximum of daily maximum near-surface (2-metre) air temperature |
|
d |
Monthly count of days with maximum near-surface (2-metre) temperature above 35 °C |
|
d |
Monthly count of days with maximum near-surface (2-metre) temperature above 40 °C |
|
d |
Monthly count of tropical nights (days with minimum temperature above 20 °C) |
|
d |
Monthly count of days with minimum near-surface (2-metre) temperature below 0 °C |
|
mm |
Monthly mean of daily accumulated precipitation of liquid water equivalent from all phases |
|
mm |
Monthly average of daily precipitation amount of liquid water equivalent from all phases on days with precipitation amount above or equal to 1 mm |
|
mm |
Monthly mean of daily accumulated liquid water equivalent thickness snowfall |
|
mm |
Monthly maximum of 1-day accumulated precipitation of liquid water equivalent from all phases |
|
d |
Monthly count of days with daily accumulated precipitation of liquid water equivalent from all phases above 1 mm |
|
d |
Monthly count of days with daily accumulated precipitation of liquid water equivalent from all phases above 10 mm |
|
d |
Monthly count of days with daily accumulated precipitation of liquid water equivalent from all phases above 20 mm |
|
mm |
Monthly mean daily accumulated potential evapotranspiration (Hargreaves method, 1985), which is the rate at which evapotranspiration would occur under ambient conditions from a uniformly vegetated area when the water supply is not limiting |
|
mm |
Monthly mean of daily amount of water in the atmosphere due to conversion of both liquid and solid phases to vapor (from underlying surface and vegetation) |
|
g/kg |
Monthly amount of moisture in the air near the surface divided by amount of air plus moisture at that location |
|
hPa |
Monthly average air pressure at mean sea level |
|
m/s |
Monthly mean of daily mean near-surface (10-metre) wind speed |
|
% |
Monthly mean cloud cover area percentage |
|
W/m² |
Monthly mean incident solar (shortwave) radiation that reaches a horizontal plane at the surface |
|
W/m² |
Monthly mean incident thermal (longwave) radiation at the surface (during cloudless and overcast conditions) |
The analysis and results are organised in the following steps, which are detailed in the sections below:
Install User-tools for the C3S Atlas.
Import all required libraries.
Define indicators.
Define helper functions.
2. Calculate indicators from the origin dataset
Download data from the origin dataset(s).
Homogenise data.
Calculate indicator(s).
Regrid the origin data to the C3S Atlas grid.
3. Retrieve indicators from the C3S Atlas dataset
Download data from the C3S Atlas dataset.
Consistency: Compare the C3S Atlas and reproduced datasets on native grids.
Reproducibility: Compare the C3S Atlas and reproduced datasets on the C3S Atlas grid.
📈 Analysis and results#
1. Code setup#
Note
This notebook uses earthkit for downloading (earthkit-data) and visualising (earthkit-plots) data. Because earthkit is in active development, some functionality may change after this notebook is published. If any part of the code stops functioning, please raise an issue on our GitHub repository so it can be fixed.
Install the User-tools for the C3S Atlas#
This notebook uses the User-tools for the C3S Atlas, which can be installed from GitHub using pip.
For convenience, the following cell can do this from within the notebook.
Further details and alternative options for installing this library are available in its documentation.
Import required libraries#
In this section, we import all the relevant packages needed for running the notebook.
Define indicators#
This section defines functions and variables for calculating and using the climate indicators. These are split into three cells, corresponding to their input and output data types.
Daily data → Monthly indicators:
Monthly data → Monthly indicators:
Monthly data → Yearly indicators. These yearly indicators are not used in the rest of the analysis, but are included as a jumping-off point for the reader’s own analysis.
The following cell defines some convenience functions for calculating multiple indicators in a loop, grouped according to their input and output data types:
The following cell defines earthkit-plots styles for the indicators. These styles define the colour maps and colour bar ranges for each quantity. Earthkit-plots styles are explained further in the corresponding documentation.
Helper functions#
This section defines some functions and variables used in the following analysis, allowing code cells in later sections to be shorter and ensuring consistency.
Data downloading & (pre-)processing#
The following functions help with downloading data from datasets with limits, by generating multiple CDS requests with similar parameters:
The following functions aid in sub-selecting data, e.g. selecting one model from the ensemble included in the C3S Atlas dataset or selecting data for a specific time frame:
The following functions help with downloading C3S Atlas data for one specific ensemble member and a subset of the temporal range (e.g. one year):
The following functions handle the homogenisation of origin data to a consistent format using the User-tools for the C3S Atlas:
The following functions handle regridding data based on ESMF as implemented in the User-tools for the C3S Atlas. This step is explained in more detail in the relevant section below.
Statistics#
The following functions calculate the difference (absolute / relative) between datasets, handling metadata etc.:
The following functions calculate and display metrics for the difference between two datasets, e.g. mean and median deviation:
Visualisation#
The following cells contain functions for plotting results, starting with some base helper functions (e.g. displaying in Jupyter Notebook or Jupyter Book style, adding textboxes with consistent formatting, etc.):
The following functions are also base helper functions, but specific to geospatial plots:
The following cell contains functions for geospatial comparisons between datasets on their native grids or on a common grid (the latter also showing the per-pixel difference):
The following cell contains functions for histogram comparisons between datasets on their native grids or on a common grid (the latter also showing the per-pixel difference):
2. Calculate indicators from the origin dataset#
Download data#
This assessment examines the dataset in one year (2080),
for one ensemble member
and
for one climate scenario
– which is not how climate projection data are normally used.
Good practice in climate science is to look at multi-year statistics and trends,
across multiple ensemble members.
However, since the purpose of this assessment is to assess the consistency and reproducibility of the post-processing performed to produce the C3S Atlas dataset,
it is valid to use a subset of the data here.
The specific subset used can be easily tweaked by changing the EXPERIMENT, MODEL, and YEARS variables in this section.
This notebook uses earthkit-data to download files from the CDS. If you intend to run this notebook multiple times, it is highly recommended that you enable caching to prevent having to download the same files multiple times. If you prefer not to use earthkit, the following requests can also be used with the cdsapi module. In either case (earthkit-data or cdsapi), it is required to set up a CDS account and API key as explained on the CDS website.
The first step is to define the parameters that will be shared between the download of the origin dataset (here CMIP6) and the C3S Atlas dataset (in the next section), namely the experiment and model member. Next, the request to download the corresponding data from CMIP6 is defined, in this notebook choosing several daily and monthly variables defined in the following cell. To simplify the data processing, daily and monthly variables are downloaded separately.
<xarray.Dataset> Size: 404MB
Dimensions: (time: 365, lat: 192, lon: 288)
Coordinates:
* time (time) object 3kB 2080-01-01 12:00:00 ... 2080-12-31 12:00:00
* lat (lat) float64 2kB -90.0 -89.06 -88.12 -87.17 ... 88.12 89.06 90.0
* lon (lon) float64 2kB 0.0 1.25 2.5 3.75 5.0 ... 355.0 356.2 357.5 358.8
height float64 8B 2.0
Data variables:
tas (time, lat, lon) float32 81MB dask.array<chunksize=(1, 192, 288), meta=np.ndarray>
tasmin (time, lat, lon) float32 81MB dask.array<chunksize=(1, 192, 288), meta=np.ndarray>
tasmax (time, lat, lon) float32 81MB dask.array<chunksize=(1, 192, 288), meta=np.ndarray>
pr (time, lat, lon) float32 81MB dask.array<chunksize=(1, 192, 288), meta=np.ndarray>
huss (time, lat, lon) float32 81MB dask.array<chunksize=(1, 192, 288), meta=np.ndarray>
Attributes: (12/48)
Conventions: CF-1.7 CMIP-6.2
activity_id: ScenarioMIP
branch_method: standard
branch_time_in_child: 60225.0
branch_time_in_parent: 60225.0
comment: none
... ...
title: CMCC-ESM2 output prepared for CMIP6
variable_id: tas
variant_label: r1i1p1f1
license: CMIP6 model data produced by CMCC is licensed und...
cmor_version: 3.6.0
tracking_id: hdl:21.14100/25c823a7-e043-463c-a6b7-4a6f067f78a4<xarray.Dataset> Size: 19MB
Dimensions: (time: 12, lat: 192, lon: 288)
Coordinates:
* time (time) object 96B 2080-01-16 12:00:00 ... 2080-12-16 12:00:00
* lat (lat) float64 2kB -90.0 -89.06 -88.12 -87.17 ... 88.12 89.06 90.0
* lon (lon) float64 2kB 0.0 1.25 2.5 3.75 5.0 ... 355.0 356.2 357.5 358.8
height float64 8B ...
Data variables:
evspsbl (time, lat, lon) float32 3MB dask.array<chunksize=(1, 192, 288), meta=np.ndarray>
prsn (time, lat, lon) float32 3MB dask.array<chunksize=(1, 192, 288), meta=np.ndarray>
sfcWind (time, lat, lon) float32 3MB dask.array<chunksize=(1, 192, 288), meta=np.ndarray>
clt (time, lat, lon) float32 3MB dask.array<chunksize=(1, 192, 288), meta=np.ndarray>
rsds (time, lat, lon) float32 3MB dask.array<chunksize=(1, 192, 288), meta=np.ndarray>
rlds (time, lat, lon) float32 3MB dask.array<chunksize=(1, 192, 288), meta=np.ndarray>
psl (time, lat, lon) float32 3MB dask.array<chunksize=(1, 192, 288), meta=np.ndarray>
Attributes: (12/48)
Conventions: CF-1.7 CMIP-6.2
activity_id: ScenarioMIP
branch_method: standard
branch_time_in_child: 60225.0
branch_time_in_parent: 60225.0
comment: none
... ...
title: CMCC-ESM2 output prepared for CMIP6
variable_id: evspsbl
variant_label: r1i1p1f1
license: CMIP6 model data produced by CMCC is licensed und...
cmor_version: 3.6.0
tracking_id: hdl:21.14100/11eb4243-d050-40aa-bc3a-34b8c1195cb6Homogenise data#
One of the steps in the C3S Atlas dataset production chain is homogenisation, i.e. ensuring consistency between data from different origin datasets.
This homogenisation is implemented in the User-tools for the C3S Atlas, specifically the c3s_atlas.fixers.apply_fixers function.
The following changes are applied:
The names of the spatial coordinates are standardised to
[lon, lat].Longitude is converted from
[0...360]to[-180...180]format.The time coordinate is standardised to the CF standard calendar.
Variable units are standardised (e.g. °C for temperature).
Variables are resampled / aggregated to the required temporal resolution.
The homogenisation is applied in the following code cells, separately for the daily and monthly data.
More details can be found in the case study for tx35.
Calculate indicators#
The climate indicators are calculated using xclim. The functions defined above perform the calculations.
<xarray.Dataset> Size: 90MB
Dimensions: (lat: 192, lon: 288, time: 12)
Coordinates:
* lat (lat) float64 2kB -90.0 -89.06 -88.12 -87.17 ... 88.12 89.06 90.0
* lon (lon) float64 2kB -178.8 -177.5 -176.2 -175.0 ... 177.5 178.8 180.0
height float64 8B 2.0
* time (time) datetime64[ns] 96B 2080-01-01 2080-02-01 ... 2080-12-01
Data variables: (12/25)
t (time, lat, lon) float32 3MB dask.array<chunksize=(1, 192, 288), meta=np.ndarray>
tn (time, lat, lon) float32 3MB dask.array<chunksize=(1, 192, 288), meta=np.ndarray>
tx (time, lat, lon) float32 3MB dask.array<chunksize=(1, 192, 288), meta=np.ndarray>
dtr (time, lat, lon) float32 3MB dask.array<chunksize=(1, 192, 288), meta=np.ndarray>
tnn (time, lat, lon) float32 3MB dask.array<chunksize=(1, 192, 288), meta=np.ndarray>
txx (time, lat, lon) float32 3MB dask.array<chunksize=(1, 192, 288), meta=np.ndarray>
... ...
evspsbl (time, lat, lon) float32 3MB dask.array<chunksize=(1, 192, 288), meta=np.ndarray>
psl (time, lat, lon) float32 3MB dask.array<chunksize=(1, 192, 288), meta=np.ndarray>
sfcwind (time, lat, lon) float32 3MB dask.array<chunksize=(1, 192, 288), meta=np.ndarray>
clt (time, lat, lon) float32 3MB dask.array<chunksize=(1, 192, 288), meta=np.ndarray>
rsds (time, lat, lon) float32 3MB dask.array<chunksize=(1, 192, 288), meta=np.ndarray>
rlds (time, lat, lon) float32 3MB dask.array<chunksize=(1, 192, 288), meta=np.ndarray>Regrid to C3S Atlas grid#
Note
This notebook uses xESMF for regridding data. xESMF is most easily installed using mamba/conda as explained in its documentation. Users who cannot or do not wish to use mamba/conda can manually compile and install ESMF on their machines. In future, this notebook will use earthkit-regrid instead, once it reaches suitable maturity.
The final step in the processing is regridding to the standardised grid used in the C3S Atlas dataset (Figure 7.2.1).
This is performed through a custom function in the User-tools for the C3S Atlas,
specifically c3s_atlas.interpolation.
This function is based on ESMF, as noted above.
Note that the C3S Atlas workflow calculates indicators first, then regrids. For operations that involve averaging, like smoothing and regridding, the order of operations can affect the result, especially in areas with steep gradients [Burggraaff+20]. Examples of such areas for a temperature index are coastlines and mountain ranges. In the case of C3S Atlas, this order of operations was a conscious choice to preserve the “raw” signals, e.g. preventing extreme temperatures from being smoothed out. However, it can affect the indicator values and therefore must be considered when using the C3S Atlas application or dataset.
Due to the number of variables involved, this section can take several minutes to run.
<xarray.Dataset> Size: 106MB
Dimensions: (lon: 360, lat: 180, time: 12, bnds: 2)
Coordinates:
* lon (lon) float64 3kB -179.5 -178.5 -177.5 ... 177.5 178.5 179.5
* lat (lat) float64 1kB -89.5 -88.5 -87.5 -86.5 ... 86.5 87.5 88.5 89.5
* time (time) datetime64[ns] 96B 2080-01-01 2080-02-01 ... 2080-12-01
Dimensions without coordinates: bnds
Data variables: (12/29)
t (time, lat, lon) float32 3MB dask.array<chunksize=(1, 180, 360), meta=np.ndarray>
lon_bnds (lon, bnds) float64 6kB -180.0 -179.0 -179.0 ... 179.0 179.0 180.0
lat_bnds (lat, bnds) float64 3kB -90.0 -89.0 -89.0 -88.0 ... 89.0 89.0 90.0
crs int64 8B 0
height float64 8B 2.0
tn (time, lat, lon) float32 3MB dask.array<chunksize=(1, 180, 360), meta=np.ndarray>
... ...
evspsbl (time, lat, lon) float32 3MB dask.array<chunksize=(1, 180, 360), meta=np.ndarray>
psl (time, lat, lon) float32 3MB dask.array<chunksize=(1, 180, 360), meta=np.ndarray>
sfcwind (time, lat, lon) float32 3MB dask.array<chunksize=(1, 180, 360), meta=np.ndarray>
clt (time, lat, lon) float32 3MB dask.array<chunksize=(1, 180, 360), meta=np.ndarray>
rsds (time, lat, lon) float32 3MB dask.array<chunksize=(1, 180, 360), meta=np.ndarray>
rlds (time, lat, lon) float32 3MB dask.array<chunksize=(1, 180, 360), meta=np.ndarray>3. Retrieve indicators from the C3S Atlas dataset#
Here, we download the same indicators as above directly from the Gridded dataset underpinning the Copernicus Interactive Climate Atlas so the values can be compared.
When downloading the C3S Atlas dataset from the CDS, it is not possible to specify a specific year or model like it is for e.g. CMIP6. Instead, data are downloaded in blocks of several decades and include all model members. To prevent memory issues from loading so many data at once, a custom function is used that downloads the data for each indicator and pulls out only the year and model member of interest. Because this is done in sequence (one indicator after another) rather than in parallel (all at the same time, like a normal earthkit-data download), this can result in the following cells taking relatively long (>1 hour) to run the first time. After the first time, caching in earthkit-data will (if enabled) speed this section up significantly.
<xarray.Dataset> Size: 78MB
Dimensions: (time: 12, lat: 180, lon: 360)
Coordinates: (12/16)
* lat (lat) float64 1kB -89.5 -88.5 -87.5 ... 87.5 88.5 89.5
* lon (lon) float64 3kB -179.5 -178.5 -177.5 ... 178.5 179.5
* time (time) datetime64[ns] 96B 2080-01-01 ... 2080-12-01
member_id <U23 92B ...
gcm_institution <U4 16B ...
gcm_model <U9 36B ...
... ...
threshold20c float64 8B ...
threshold0c float64 8B ...
threshold1mm float64 8B 1.0
threshold10mm float64 8B ...
threshold20mm float64 8B ...
height10m float64 8B ...
Data variables: (12/26)
t (time, lat, lon) float32 3MB dask.array<chunksize=(12, 26, 52), meta=np.ndarray>
crs int32 4B -2147483647
tn (time, lat, lon) float32 3MB dask.array<chunksize=(12, 26, 52), meta=np.ndarray>
tx (time, lat, lon) float32 3MB dask.array<chunksize=(12, 26, 52), meta=np.ndarray>
dtr (time, lat, lon) float32 3MB dask.array<chunksize=(12, 26, 52), meta=np.ndarray>
tnn (time, lat, lon) float32 3MB dask.array<chunksize=(12, 26, 52), meta=np.ndarray>
... ...
huss (time, lat, lon) float32 3MB dask.array<chunksize=(12, 26, 52), meta=np.ndarray>
psl (time, lat, lon) float32 3MB dask.array<chunksize=(12, 23, 52), meta=np.ndarray>
sfcwind (time, lat, lon) float32 3MB dask.array<chunksize=(12, 26, 52), meta=np.ndarray>
clt (time, lat, lon) float32 3MB dask.array<chunksize=(12, 26, 52), meta=np.ndarray>
rsds (time, lat, lon) float32 3MB dask.array<chunksize=(12, 23, 45), meta=np.ndarray>
rlds (time, lat, lon) float32 3MB dask.array<chunksize=(12, 26, 52), meta=np.ndarray>
Attributes: (12/26)
Conventions: CF-1.9 ACDD-1.3
title: Copernicus Interactive Climate Atlas: gridded...
summary: Monthly/annual gridded data from observations...
institution: Copernicus Climate Change Service (C3S)
producers: Institute of Physics of Cantabria (IFCA, CSIC...
license: CC-BY 4.0, https://creativecommons.org/licens...
... ...
geospatial_lon_min: -180.0
geospatial_lon_max: 180.0
geospatial_lon_resolution: 1.0
geospatial_lon_units: degrees_east
date_created: 2024-12-05 15:51:48.916442+01:00
tracking_id: 89974d82-56b6-4b47-958e-5954716013d34. Results#
This section contains the comparison between the indicator values retrieved from the C3S Atlas dataset vs those reproduced from the origin dataset.
The datasets are first compared on their native grids. This means a point-by-point comparison is not possible (because the points are not equivalent), but the distributions can be compared geospatially and overall. This qualitative comparison probes the consistency quality attribute: Are the climate indicators in the dataset underpinning the Copernicus Interactive Climate Atlas consistent with their origin datasets?
Second, the C3S Atlas dataset is compared to the indicators derived from the origin dataset and regridded to the C3S Atlas grid. This makes a quantitative point-by-point comparison possible. This second comparison probes how well the dataset underpinning the Copernicus Interactive Climate Atlas can be reproduced from its origin datasets, based on the workflow (Figure 7.2.1).
For the geospatial comparison,
we display the values of the indicators for one month,
across one region and globally.
As an example, we display the results across
Europe
in
June,
which should provide significant spatial variation.
This region can easily be modified in the following code cell using the domains provided by earthkit-plots.
Some examples are provided in the cell (commented out using #).
Consistency: Comparison on native grids#
As in the case study for tx35,
it is clear from the geospatial comparison
(Figure 7.2.2)
that the C3S Atlas dataset closely resembles a manual reproduction from its origin datasets.
The general distribution of indicator values is the same for
all indicators.
In a few cases,
such as
sdii (northern Africa, north of the Caspian Sea)
and
pet (northern Africa, seas, within the Arctic circle),
the two datasets differ in terms of coverage.
For pet,
this difference is due to a deliberate decision in the C3S Atlas workflow
to mask areas where agricultural studies do not make sense,
such as arid regions, areas permanently covered by ice, and regions with no vegetation.
This masking is explained in a Jupyter notebook written by the data provider.
This pattern is also visible in the overall distributions
(Figure 7.2.3),
which are again very similar for almost all indicators.
The distributions only differ clearly for
sdii
and
pet,
due to the aforementioned gaps and masks.
The overall conclusion from this comparison is the same as in the case study for tx35.
The C3S Atlas dataset and its origins are highly consistent,
but small differences exist due to the difference in grid.
There are also differences in data availability for some indicators,
due to deliberate masking of specific areas.
Users of the C3S Atlas dataset
– and thus users of the C3S Atlas application –
should be aware that the indicator values retrieved for a specific location may differ slightly from a manual analysis of the origin dataset.

Fig. 7.2.2 Comparison between C3S Atlas dataset and reproduction for multiple indicators in one month, across Europe, on the native grid of each dataset.#

Fig. 7.2.3 Comparison between overall distributions of indicator values in the C3S Atlas dataset and its reproduction, across all spatial and temporal dimensions, on the native grid of each dataset.#
Reproducibility: Comparison on C3S Atlas grid#
After regridding to the C3S Atlas grid, the indicator values reproduced from the origin dataset can be compared point-by-point to the values retrieved from the C3S Atlas dataset. We first examine some metrics that describe the difference Δ between corresponding pixels:
| Mean Δ | Median Δ | Median |Δ| | % where |Δ| ≥ ε | Median |Δ| [%] | % where |Δ| ≥ 0.1% | Pearson r | |
|---|---|---|---|---|---|---|---|
| t | 0.00000 | 0.00000 | 0.00028 | 98.08282 | nan | nan | 1.00000 |
| tn | -0.00000 | 0.00000 | 0.00028 | 98.08783 | nan | nan | 1.00000 |
| tx | -0.00000 | 0.00000 | 0.00028 | 98.10905 | nan | nan | 1.00000 |
| dtr | 0.00000 | 0.00000 | 0.00033 | 98.39982 | 0.01457 | 6.62924 | 1.00000 |
| tnn | -0.00000 | -0.00000 | 0.00116 | 99.52688 | nan | nan | 1.00000 |
| txx | 0.00000 | 0.00000 | 0.00116 | 99.53447 | nan | nan | 1.00000 |
| tx35 | -0.00095 | 0.00000 | 0.00000 | 0.09388 | 0.00000 | 0.09079 | 0.99998 |
| tx40 | -0.00047 | 0.00000 | 0.00000 | 0.04720 | 0.00000 | 0.04398 | 0.99998 |
| tr | -0.00216 | 0.00000 | 0.00000 | 12.46425 | 0.00000 | 1.12269 | 1.00000 |
| fd | -0.10867 | 0.00000 | 0.00000 | 18.00463 | 0.00000 | 16.25874 | 0.99978 |
| r | -0.00003 | -0.00003 | 0.00028 | 98.00682 | 0.01431 | 12.93596 | 1.00000 |
| sdii | -0.00716 | -0.00007 | 0.00042 | 87.06713 | 0.00746 | 8.82253 | 0.99991 |
| prsn | -0.00000 | -0.00000 | 0.00000 | 37.15265 | 0.00000 | 10.82870 | 1.00000 |
| rx1day | -0.00000 | -0.00001 | 0.00116 | 99.49743 | 0.00997 | 10.05993 | 1.00000 |
| r01 | 0.41235 | 0.39551 | 0.40234 | 86.51813 | 3.02010 | 85.46824 | 0.99926 |
| r10 | 0.26182 | 0.04492 | 0.04590 | 52.45988 | 1.34875 | 52.32150 | 0.99599 |
| r20 | 0.14342 | 0.00000 | 0.00000 | 29.29900 | 0.00000 | 29.26363 | 0.98461 |
| pet | -0.04330 | -0.00001 | 0.00025 | 19.53099 | 0.00862 | 2.58153 | 0.98785 |
| evspsbl | 0.00000 | 0.00000 | 0.00024 | 97.97724 | 0.00839 | 8.67323 | 1.00000 |
| huss | 0.00013 | 0.00000 | 0.00027 | 98.09658 | 0.00311 | 11.36677 | 1.00000 |
| psl | -0.00003 | 0.00000 | 0.00061 | 96.88182 | 0.00006 | 0.00000 | 1.00000 |
| sfcwind | -0.00000 | -0.00000 | 0.00024 | 97.95782 | 0.00392 | 0.00000 | 1.00000 |
| clt | 0.00000 | 0.00000 | 0.00024 | 97.81430 | 0.00037 | 0.05350 | 1.00000 |
| rsds | 0.00000 | 0.00000 | 0.00023 | 92.04655 | 0.00013 | 1.08320 | 1.00000 |
| rlds | 0.00000 | 0.00000 | 0.00024 | 97.09195 | 0.00007 | 0.00000 | 1.00000 |
As in the case study for tx35,
it is clear that
the C3S Atlas dataset and its manual reproduction
are very similar.
The median difference, median absolute difference, and median absolute percentage difference
are all close to 0 for
almost all indicators.
The percentage of pixels with a non-zero difference
(defined here as |Δ| ≥ ε with ε = 10–5 to avoid floating-point errors)
is a less useful metric here since most of the indicators are
real numbers,
rather than integers like tx35.
This leaves more room for small differences in the data to appear due to
small changes in the origin dataset and/or the C3S Atlas workflow software,
which for an integer indicator like tx35 would tend to be rounded off.
For most indicators,
the relative difference between datasets is ≤0.1% for
the vast majority of point-by-point comparisons.
The distributions of indicator values and differences (Figure 7.2.5) confirm that the differences between the two datasets tend to be very small, with distributions centered around 0 and few outliers.
It is not clear why some indicators show larger differences.
For pet, the differences are due to masking in a specific region
(Northern Fennoscandia; Figure 7.2.4),
as discussed before.
However, the same is not true for the daily precipitation indicators
r01,
r10,
and
r20.
These particular indicators show high values and significant spread across Europe in June
(and presumably in other months)
meaning the differences may simply be due to regridding.
This also explains why there are non-integer differences:
since the C3S Atlas workflow calculates indicators and then regrids,
the regridded indicators can have non-integer values.
Similar effects can be seen in other indicators when converting between integer and floating-point data types.
We can extend the conclusion from the tx35 case study,
namely that the C3S Atlas dataset can be considered practically reproducible.
However,
some of the indicators show non-zero differences,
either
in specific locations
(e.g. pet)
or
distributed randomly
(e.g. r01).
These differences are caused
either
by deliberate decisions to mask certain regions
or
(likely)
by small differences in the data processing.
They are small and rare enough to be negligible for most users using the C3S Atlas dataset,
especially since they will typically use it through the application.
For further analysis,
it is generally best to manually process the origin dataset,
if only to remove the amount of steps that may affect the result.

Fig. 7.2.4 Comparison between C3S Atlas dataset and reproduction for multiple indicators in one month, across Europe, on the C3S Atlas dataset grid, including the per-pixel difference.#
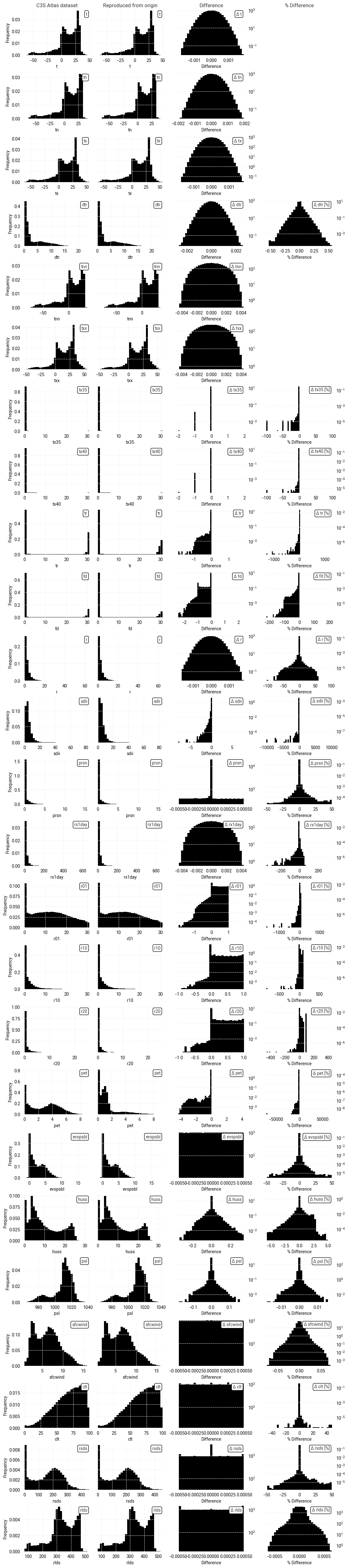
Fig. 7.2.5 Comparison between overall distributions of indicator values in the C3S Atlas dataset and its reproduction on the C3S Atlas grid, across all spatial and temporal dimensions, including the per-pixel difference.#
ℹ️ If you want to know more#
Key resources#
The CDS catalogue entries for the data used were:
Gridded dataset underpinning the Copernicus Interactive Climate Atlas: multi-origin-c3s-atlas
Consistency between the C3S Atlas dataset and its origins: Case study
Consistency between the C3S Atlas dataset and its origins: Multiple indicators
Consistency between the C3S Atlas dataset and its origins: Multiple origin datasets
CMIP6 climate projections: projections-cmip6
Code libraries used:
xclim climate indicator tools
More about the Copernicus Interactive Climate Atlas and its IPCC predecessor:
References#
[Gutiérrez+24] J. M. Gutiérrez et al., ‘The Copernicus Interactive Climate Atlas: a tool to explore regional climate change’, ECMWF Newsletter, vol. 181, pp. 38–45, Oct. 2024, doi: 10.21957/ah52ufc369.
[C3S Atlas dataset] Copernicus Climate Change Service, ‘Gridded dataset underpinning the Copernicus Interactive Climate Atlas’. Copernicus Climate Change Service (C3S) Climate Data Store (CDS), Jun. 17, 2024. doi: 10.24381/cds.h35hb680.
[CMIP6 dataset] Copernicus Climate Change Service, ‘CMIP6 climate projections’. Copernicus Climate Change Service (C3S) Climate Data Store (CDS), Mar. 23, 2021. doi: 10.24381/cds.c866074c.
[Burggraaff+20] O. Burggraaff, ‘Biases from incorrect reflectance convolution’, Optics Express, vol. 28, no. 9, pp. 13801–13816, Apr. 2020, doi: 10.1364/OE.391470.