2.3. Time series#
This Jupyter Notebook reproduces the Time Series (see figure bellow) product from the C3S Atlas.
The time series panel displays the annual/seasonal values year by year, along the historical or historical and future climate periods. For observations/reanalysis, the time-series panel displays the regionally aggregated annual/seasonal series. For climate projections, the time-series displays the regionally aggregated annual/seasonal series for the raw values or the changes (anomalies relative to the selected baseline in this case) for all the model simulations forming the ensemble, as well as the ensemble median. A gray shading indicates the particular period selected, as represented in the map; in the case of Global Warming Levels, the shading area exhibits different gray shading intensities according to the overlaps of 20-year periods where the warming level is first reached by the different models (higher shade intensity indicates years with higher overlap). Detailed (percentile) information is also provided.
2.3.1. Load Python packages and clone and install the c3s-atlas GitHub repository from the ecmwf-projects#
Clone (git clone) the c3s-atlas repository and install them (pip install -e .).
Further details on how to clone and install the repository are available in the requirements section
import os
import xarray as xr
import glob
from datetime import date
import numpy as np
from pathlib import Path
import cdsapi
import matplotlib.pyplot as plt
import cartopy.crs as ccrs
from c3s_atlas.utils import (
season_get_name,
extract_zip_and_delete,
)
from c3s_atlas.customized_regions import (
Mask
)
from c3s_atlas.analysis import (
annual_weighted_average
)
from c3s_atlas.products import (
time_series,
)
from c3s_atlas.GWLs import (
load_GWLs,
select_member_GWLs,
get_selected_data
)
2.3.2. Time series for observations/reanalysis#
Linear trend analysis is included in the time series for observations and reanalysis. However, this analysis is not recommended for projections, as climate change may not scale linearly.
Download climate data with the CDS API#
cdsapi_url= "https://cds.climate.copernicus.eu/api"
cdsapi_key= ""
c = cdsapi.Client(url=cdsapi_url, key=cdsapi_key)
⚠️ Warning: Exposed API Credentials
For security reasons, it is not recommended to hardcode your Copernicus Climate Data Store (CDS) API credentials — such as
cdsapi_urlandcdsapi_key— directly in notebooks.Instead, it is best to store them securely in a
.cdsapircfile located in your home directory.📄 More info: CDS API - How to use the API
project = "ERA5"
var = 'r'
season = [3, 4, 5] # Months
dest = Path('./data/ERA5')
os.makedirs(dest, exist_ok=True)
filename = 'r_ERA5_mon_194001-202212.zip'
dataset = "multi-origin-c3s-atlas"
request = {
"origin": "era5",
"domain": "global",
"period": "1940-2024",
"variable": "monthly_precipitation",
"bias_adjustment": "no_bias_adjustment",
'area': [44.5, -9.5, 35.5, 3.5]
}
c.retrieve(dataset, request).download(dest / filename)
extract_zip_and_delete(dest / filename)
ds = xr.open_dataset(dest / "r_ERA5_mon_194001-202212.nc")
attrs = {
"project" : project,
"variable": var,
"season": season,
"season_name" : season_get_name(season),
"actual_year": date.today().year,
"unit" : ds[var].units
}
Analysis#
trend_period=slice('1991','2020')
mask = Mask(ds).regions_AR6(['MED'])
filtered_ds = ds.where(mask)
time_series_ds, results = annual_weighted_average(filtered_ds, var,
season, trend = True,
trend_period=trend_period)
Plot#
time_series_plot = time_series(time_series_ds, var, attrs,
mode = 'trend', season = season,
results = results, trend_period=trend_period)
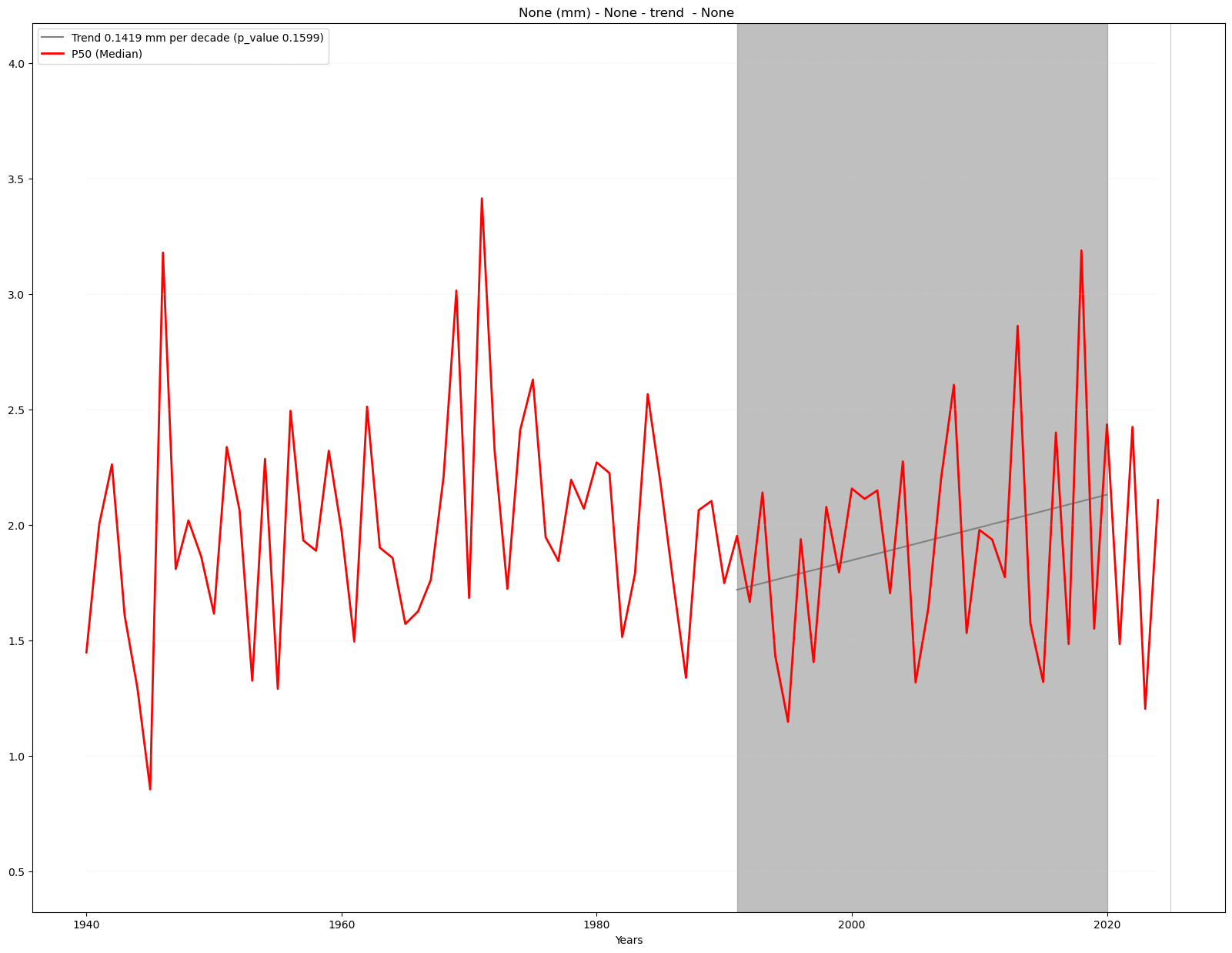
Linear trend analysis is ony calculated for the chosen trend period
Download climate data with the CDS API#
project = "E-OBS"
var = 'r'
season = [3, 4, 5] # Months
dest = Path('./data/E-OBS')
os.makedirs(dest, exist_ok=True)
filename = 'r_eobs_mon_194001-202212.zip'
dataset = "multi-origin-c3s-atlas"
request = {
"origin": "e_obs",
"domain": "europe",
"period": "1950-2021",
"variable": "monthly_precipitation",
"bias_adjustment": "no_bias_adjustment",
'area': [44.5, -9.5, 35.5, 3.5]
}
c.retrieve(dataset, request).download(dest / filename)
extract_zip_and_delete(dest / filename)
ds = xr.open_dataset(dest / "r_eobs_mon_194001-202212.nc")
attrs = {
"project" : project,
"variable": var,
"season": season,
"season_name" : season_get_name(season),
"actual_year": date.today().year,
"unit" : ds[var].units
}
Analysis#
The time_series function calculates and returns p-values for linear regression trends for the trend_period selected. Robustness is defined using the significance of the linear trends as obtained from standard hypothesis testing (and obscuring regions with non-significant trends using “x”).
A p-value indicates the level of significance of the trend:
A small p-value (usually less than 0.05) means it’s very unlikely to be random — so we can trust the trend is significant.
A large p-value means the trend might just be noise or coincidence, so we don’t consider it reliable.
trend_period=slice('1991','2020')
mask = Mask(ds).regions_AR6(['MED'])
filtered_ds = ds.where(mask)
time_series_ds, results = annual_weighted_average(filtered_ds, var,
season, trend = True,
trend_period=trend_period)
Plot#
time_series_plot = time_series(time_series_ds, var, attrs,
mode = 'trend', season = season,
results = results, trend_period=trend_period)
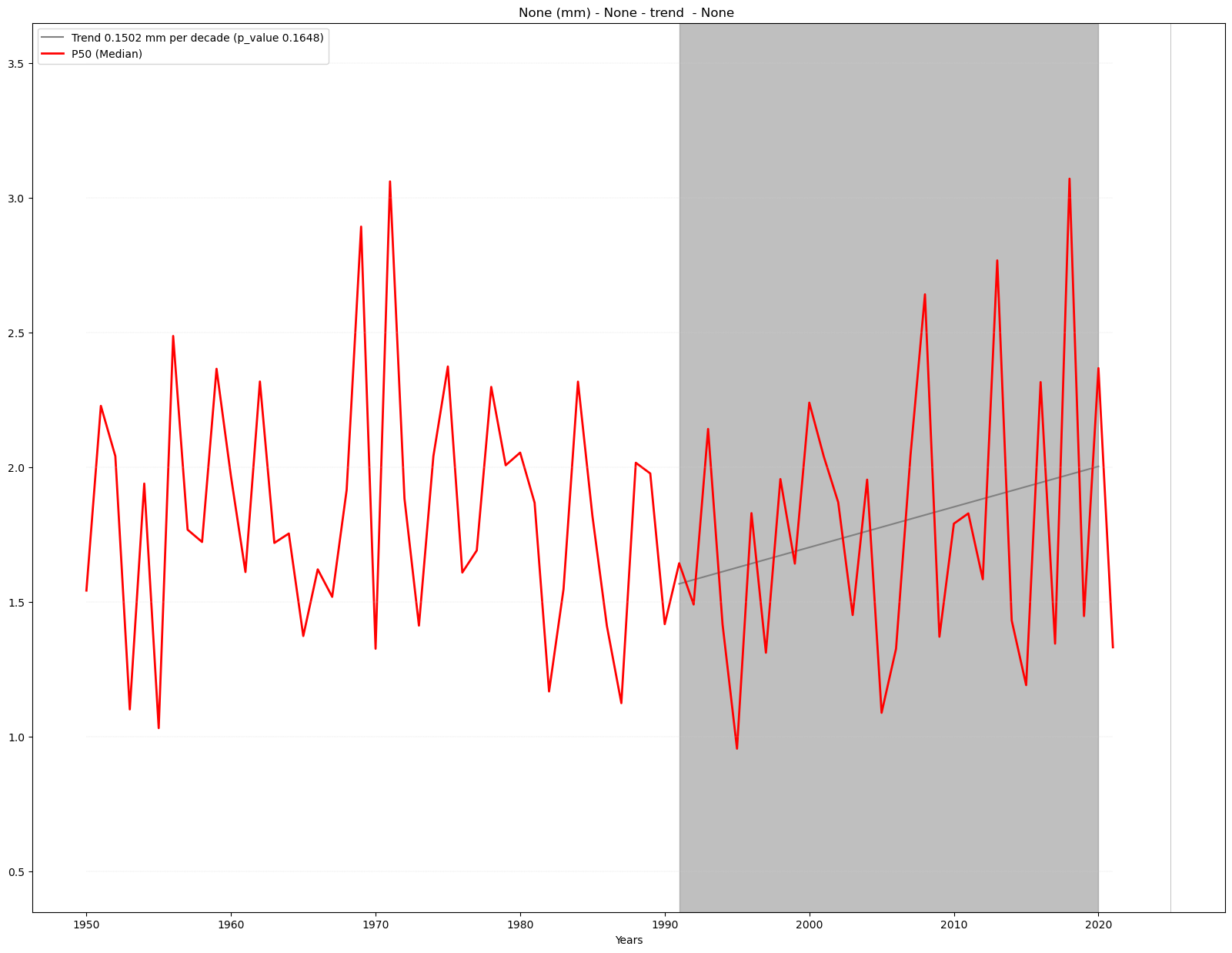
Linear trend analysis is ony calculated for the chosen trend period
2.3.3. Time series for projections#
The time series for projections show all the model simulations forming the ensemble, as well as the ensemble median
project = "CMIP6"
scenario = "ssp370"
var = 'r'
dest = Path('./data/CMIP6') # directory to download the files
os.makedirs(dest, exist_ok=True)
Download historical data#
filename = 'r_CMIP6_historical_mon_185001-201412.zip'
dataset = "multi-origin-c3s-atlas"
request = {
"origin": "cmip6",
"experiment": "historical",
"period": "1850-2014",
"variable": "monthly_precipitation",
"bias_adjustment": "no_bias_adjustment",
'area': [44.5, -9.5, 35.5, 3.5]
}
c.retrieve(dataset, request).download(dest / filename)
extract_zip_and_delete(dest / filename)
Download SSP scenario#
filename = 'r_CMIP6_ssp370_mon_201501-210012.zip'
dataset = "multi-origin-c3s-atlas"
request = {
"origin": "cmip6",
"experiment": "ssp3_7_0",
"period": "2015-2100",
"variable": "monthly_precipitation",
"bias_adjustment": "no_bias_adjustment",
'area': [44.5, -9.5, 35.5, 3.5]
}
c.retrieve(dataset, request).download(dest / filename)
extract_zip_and_delete(dest / filename)
Concatenate historical and SSP scenarios#
Note that the historical and SSP scenarios may have a different number of members. Here, common members from the historical and SSP scenarios are concatenated into a single xarray.Dataset to facilitate their use going forward.
ds_hist = xr.open_dataset(dest / "r_CMIP6_historical_mon_185001-201412.nc")
ds_sce = xr.open_dataset(dest / "r_CMIP6_ssp370_mon_201501-210012.nc")
mem_inters = np.intersect1d(ds_hist.member_id.values, ds_sce.member_id.values)
ds_hist = ds_hist.isel(member = np.isin(ds_hist.member_id.values, mem_inters))
ds_sce = ds_sce.isel(member = np.isin(ds_sce.member_id.values, mem_inters))
ds = xr.concat([ds_hist, ds_sce], dim = 'time')
Define season#
season = [3, 4, 5] # Months
attrs = {
"project" : project,
"scenario": scenario,
"variable": var,
"season": season,
"season_name" : season_get_name(season),
"actual_year": date.today().year,
"unit" : ds[var].units
}
Select Region#
To reduce data size and download time, a geographical subset focusing on a specific area within the European region (Spain) is selected.
mask = Mask(ds).European_contries(['ESP'])
filtered_ds = ds.where(mask)
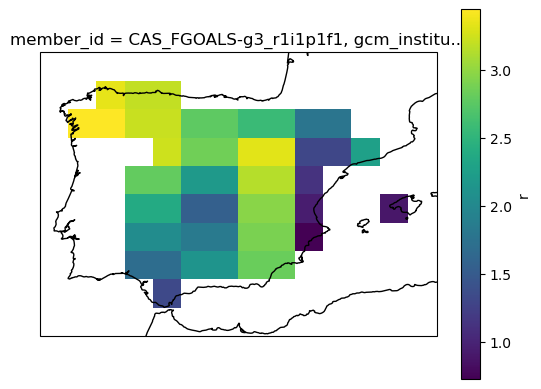
# mean spatial map for one member
ax = plt.axes(projection=ccrs.PlateCarree()) # Use PlateCarree for lat/lon projections
filtered_ds[var].isel(member=0).mean(dim='time').plot(ax=ax, transform=ccrs.PlateCarree())
ax.coastlines()
plt.show()
Analysis for the product#
The annual_weighted_average function calculates the yearly spatial mean of a dataset, weighted by the cosine of the latitude. This is a common approach to account for the varying size of grid cells at different latitudes, as areas near the poles have smaller grid cells than those near the equator. By applying this weighting, the function ensures that each grid cell contributes appropriately to the overall average, regardless of its geographical location.
time_series_ds = annual_weighted_average(filtered_ds, var, season = season)
Plot#
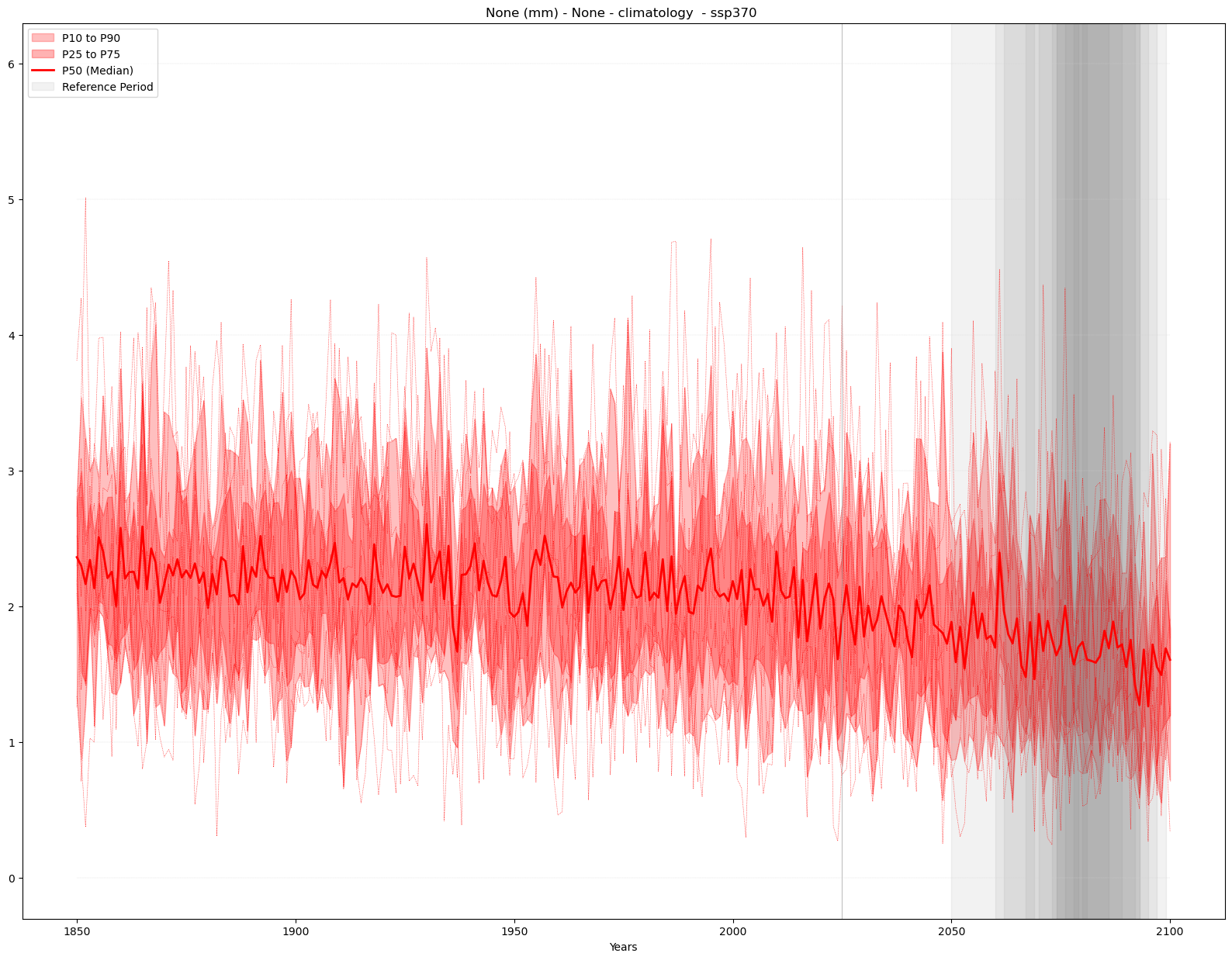
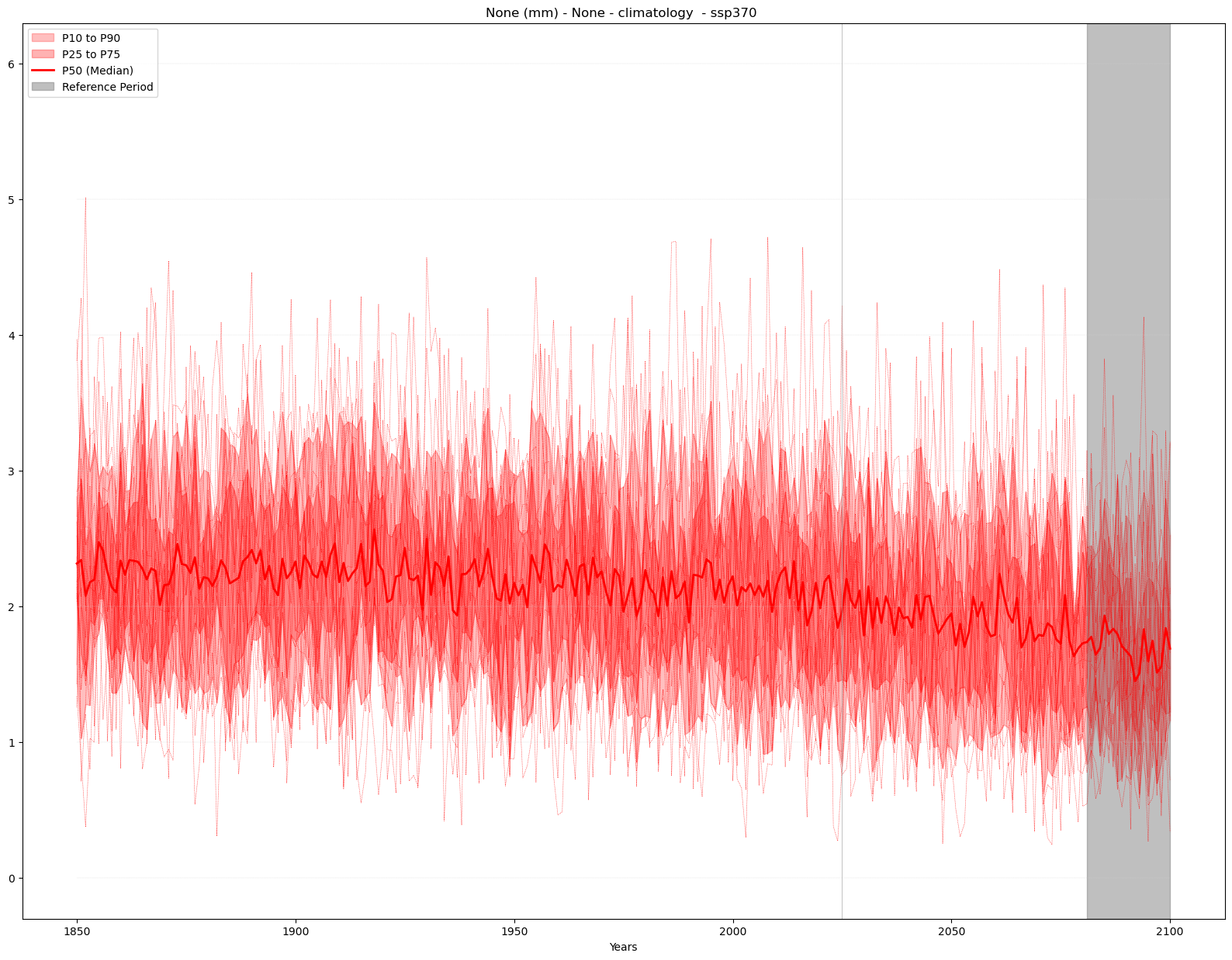
a) Climatology#
mode = 'climatology'
period = slice(2081, 2100)
time_series_plot = time_series(time_series_ds, var, attrs,
mode = mode, season = season, period = period)
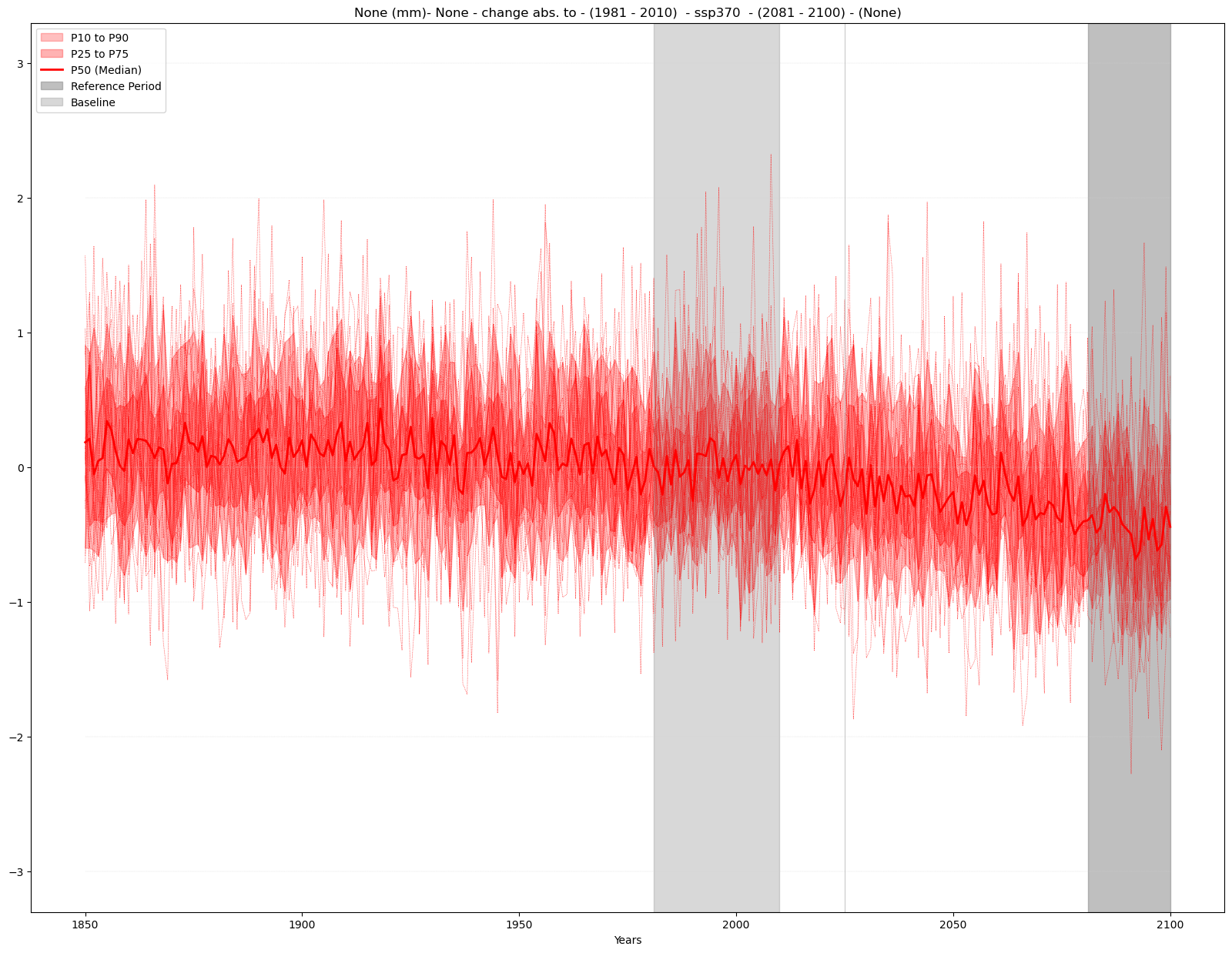
b) Absolute change#
mode = 'change'
diff = 'abs'
period = slice(2081,2100)
baseline_period = slice(1981,2010)
time_series_plot = time_series(time_series_ds, var, attrs,
mode = mode, diff = diff, season = season,
baseline_period = baseline_period, period = period)
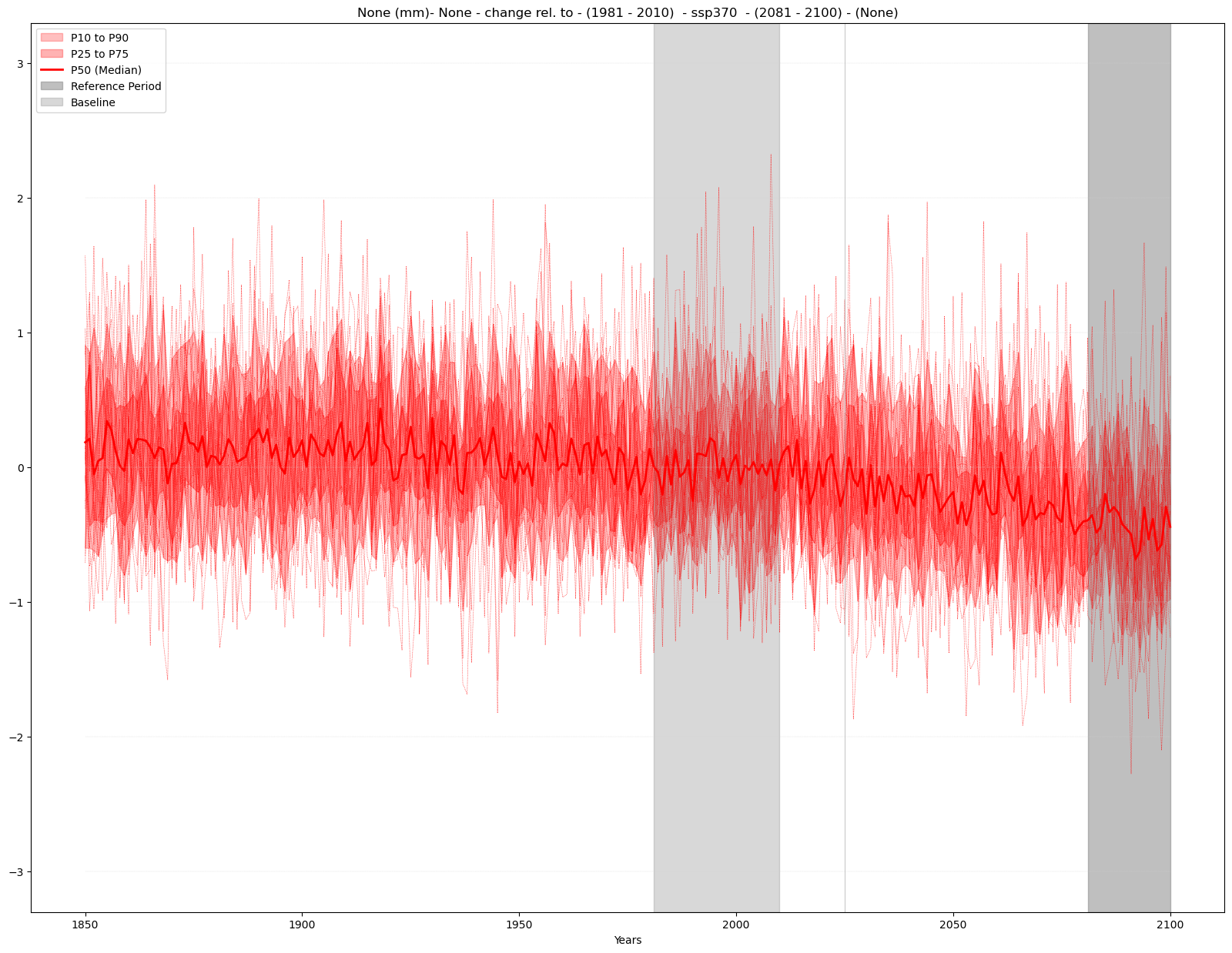
c) Relative change#
mode = 'change'
diff = 'rel'
period = slice(2081,2100)
baseline_period = slice(1981,2010)
time_series_plot = time_series(time_series_ds, var, attrs,
mode = mode, diff = diff, season = season,
baseline_period = baseline_period, period = period)
2.3.4. Globar Warming Levels#
Here, the time series are displayed for a specific Global Warming Level (GWL). To achieve this, the 20-year period in which each ensemble member reaches the chosen GWL is selected. The time series are then shown, representing either climatology or change for this specific period and region (Spain in this notebook).
These periods are calculated in the notebook GWLs.ipynb for CMIP5 and CMIP6. For CORDEX, the results from the driving CMIP5 models are used.
#Load the data and get the intersection of the members
GWL= '4'
GWLs_ds = load_GWLs(project)
GWLs_members_with_period = select_member_GWLs(filtered_ds, GWLs_ds, project, scenario, GWL)
filtered_GWLs_ds = get_selected_data(filtered_ds, GWLs_members_with_period)
Analysis#
time_series_GWL_ds = annual_weighted_average(filtered_GWLs_ds, var, season)
Plot#
mode = 'climatology'
baseline_period = slice(1981,2010)
time_series_plot = time_series(time_series_GWL_ds, var, attrs,
mode = mode, season = season,
baseline_period = baseline_period,
GWL = GWLs_members_with_period, GWLs = GWL)