

Calculation of global distribution and timeseries of Outgoing Longwave Radiation (OLR) using NOAA/NCEI HIRS data#
This notebook-tutorial provides a practical introduction to the HIRS dataset available on
C3S Earth’s radiation budget from 1979 to present derived from satellite observations.
We give a short introduction to the ECV Earth Radiation Budget, Outgoing Longwave Radiation (OLR) and provide three use cases of the dataset: plot the time-averaged global distribution of OLR (Use Case 1), calculate global timeseries of OLR (Use Case 2) and plot the Arctic weighted mean timeseries between 1979 and 2019 (Use Case 3).
We provide step-by-step instructions on data preparation. Use cases come with extensive documentation and each line of code is explained.
Two figures below are results of Use Case 1 and 2, and the result of a successful run of the code.
The notebook has three main sections with the following outline:
Table of Contents#
1. Introduction
2. Prerequisites and data preparations
3. Use cases
Use case 1: Climatology of the Outgoing Longwave Radiation (OLR)
Use case 2: Global time series of the OLR
Use case 3: OLR evolution in the Arctic
References
1. Introduction#
Please find further information about the dataset as well as the data in the Climate Data Store catalogue entry Earth’s Radiation Budget, sections “Overview”, “Download data” and “Documentation”:
The tutorial video describes the “Earth Radiation Budget” Essential Climate Variable and the methods and satellite instruments used to produce the data provided in the CDS catalogue entry:
2. Prerequisites and data preparations#
This chapter provides information on how to: run the notebook, lists necessary python libraries, and guides you through the process of data on data preparation: how to search and download the data via CDS API, and get it ready to be used.
2.1 How to access the notebook#
This tutorial is in the form of a Jupyter notebook. You will not need to install any software for the training as there are a number of free cloud-based services to create, edit, run and export Jupyter notebooks such as this. Here are some suggestions (simply click on one of the links below to run the notebook):
| Run the tutorial via free cloud platforms: |
 |
|
|
|---|
We are using cdsapi to download the data. This package is not yet included by default on most cloud platforms. You can use pip to install it:
!pip install cdsapi
Run the tutorial in local environment
If you would like to run this notebook in your own environment, we suggest you install Anaconda, which is the easiest way to get all libraries installed.
We will be working with data in NetCDF format. To best handle NetCDF data we will use libraries for working with multidimensional arrays, in particular Numpy, Pandas and Xarray. We will also need libraries for plotting and viewing data, in this case, we will use Matplotlib and Cartopy. Pylab and urllib3 change the plot style, and urllib for disabling warnings for data download via CDS API.
2.2 Import libraries#
# CDS API library
import cdsapi
# Libraries for working with multidimensional arrays
import xarray as xr
import numpy as np
import pandas as pd
# Library to work with zip-archives, OS-functions and pattern expansion
import zipfile
import os
# Libraries for plotting and visualising data
import matplotlib.pyplot as plt
import cartopy.crs as ccrs
import cartopy.feature as cfeature
# Disable warnings for data download via API
import urllib3
urllib3.disable_warnings()
2.3 Download data using CDS API#
This subsection describes the process of data search in the CDS catalogue, and data preparation for use in the use cases.
Set up CDS API credentials#
We will request data from the CDS programmatically with the help of the CDS API.
First, we need to manually set the CDS API credentials. To do so, we need to define two variables: URL and KEY.
To obtain these, first login to the CDS, then visit https://cds-beta.climate.copernicus.eu/how-to-api and copy the string of characters listed after “key:”. Replace the ######### below with this string.
URL = 'https://cds-beta.climate.copernicus.eu/api'
KEY = '#########'
Next, we specify a directory where we will download our data and some filenames which we will use in several of the subsequent cells:
DATADIR = './'
# Filename for the zip file downloaded from the CDS
download_zip_file = os.path.join(DATADIR, 'olr-monthly_v02r07.zip')
# Filename for the netCDF file which contain the merged contents of the monthly files.
merged_netcdf_file = os.path.join(DATADIR, 'olr-monthly_v02r07_197901_202207.nc')
Search for data#
To search for data, visit the CDS website: https://cds-beta.climate.copernicus.eu/. Here you can search for HIRS OLR data using the search bar. The data we need for this use case is the Earth’s Radiation Budget from 1979 to present derived from satellite observations. The Earth Radiation Budget (ERB) comprises the quantification of the incoming radiation from the Sun and the outgoing reflected shortwave and emitted longwave radiation. This catalogue entry comprises data from a number of sources.
Having selected the correct catalogue entry, we now need to specify what origin, variables, temporal and geographic coverage we are interested in. These can all be selected in the “Download data” tab. In this tab a form appears in which we will select the following parameters to download:
Origin:
NOAA/NCEI HIRSVariable:
Outgoing longwave radiationYear:
1979 to present(use “Select all” button)Month:
allGeographical area:
Whole available regionFormat:
Compressed zip file (.zip)
If you have not already done so, you will need to accept the terms & conditions of the data before you can download it.
At the end of the download form, select Show API request. This will reveal a block of code, which you can simply copy and paste into a cell of your Jupyter Notebook (see cell below) …
c = cdsapi.Client(url=URL, key=KEY)
c.retrieve(
'satellite-earth-radiation-budget',
{
'download_format': 'zip',
'data_format': 'netcdf_legacy',
'origin': 'noaa_ncei_hirs',
'variable': 'outgoing_longwave_radiation',
'year': ['%04d' % (year) for year in range(1979, 2023)],
'month': ['%02d' % (mnth) for mnth in range(1, 13)],
},
download_zip_file
)
2023-03-07 14:26:20,416 INFO Welcome to the CDS
2023-03-07 14:26:20,417 INFO Sending request to https://cds.climate.copernicus.eu/api/v2/resources/satellite-earth-radiation-budget
2023-03-07 14:26:20,544 INFO Request is completed
2023-03-07 14:26:20,545 INFO Downloading https://download-0010-clone.copernicus-climate.eu/cache-compute-0010/cache/data6/dataset-satellite-earth-radiation-budget-82e47200-a028-4824-bab6-64bd6b2167b7.zip to ./olr-monthly_v02r07.zip (17.7M)
2023-03-07 14:26:21,468 INFO Download rate 19.1M/s
Result(content_length=18523432,content_type=application/zip,location=https://download-0010-clone.copernicus-climate.eu/cache-compute-0010/cache/data6/dataset-satellite-earth-radiation-budget-82e47200-a028-4824-bab6-64bd6b2167b7.zip)
Unpack and merge data#
The zip files are now requested and downloaded to the data directory that we specified earlier. For the purposes of this tutorial, we will unzip the archive and merge all files into one NetCDF file. After that, we delete all individual files.
# Unzip the data. The dataset is split in monthly files.
# Full HIRS dataset consists of more than 500 files.
with zipfile.ZipFile(download_zip_file, 'r') as zip_ref:
filelist = [os.path.join(DATADIR, f) for f in zip_ref.namelist()]
zip_ref.extractall(DATADIR)
# Ensure the filelist is in the correct order:
filelist = sorted(filelist)
# Merge all unpacked files into one.
ds = xr.open_mfdataset(filelist, concat_dim='time', combine='nested')
ds.to_netcdf(merged_netcdf_file)
# Recursively delete unpacked data, using library glob,
# that enables Unix style pathname pattern expansion
for f in filelist:
os.remove(f)
3. Use Cases#
Use case 1: Climatology of the Outgoing Longwave Radiation (OLR)#
Firstly, we should get an overview of the parameter by plotting the time-averaged global distribution. The data are stored in NetCDF format, and we will use Xarray library to work with the data. We will then use Matplotlib and Catropy to visualise the data.
Load dataset, subselect and calculate temporal mean#
We load the NetCDF file with the library xarray and the function open_dataset(). We receive the xarray.Dataset that has one data variable (OLR) and three dimensions: time: 480 steps, latitude: 72, and longitude: 144. This data type has also a number of attributes with auxiliary information about the data.
Next, we want to select the specific time range for the plotting from January 1979 to December 2018. Xarray has a method sel that indexes the data and dimensions by the appropriate indexers.
We use the method mean to applying mean along the time dimension.
# Read data and calculate the global mean.
xdf = xr.open_dataset(merged_netcdf_file, decode_times=True, mask_and_scale=True)
xdf = xdf.sel(time=slice('1979-01-01', '2019-01-01'))
# calculate the mean along the time dimension
xdf_m = xdf.olr.mean(dim=['time'])
Calculate temporal mean and convert longitude to [-180, 180] grid#
The code below shifts the longitude dimension from [1.25 to 358.75] to [-178.75, 178.75]. We also sort the longitude values in ascending order.
xdf_m.coords['lon'] = ((xdf_m['lon'] + 180) % 360) - 180
xdf_m = xdf_m.loc[{'lon': sorted(xdf_m.coords['lon'].values)}]
Plot data#
First, we want to save objects figure and axes to use later. Cartopy can transform data arrays on different geographic projections. We use Cartopy in combination with Matplotlib to create a high-quality plot. Pcolormesh doesn’t work with data arrays with NaNs. Before plotting we convert DataArray to the numpy MaskedArray.
fig1 = plt.figure(figsize=(16, 8))
ax1 = plt.subplot(1, 1, 1, projection=ccrs.PlateCarree())
masked_average = xdf_m.to_masked_array() # mask the data because pcolormesh cannot plot nan-values
im = plt.pcolormesh(
xdf_m['lon'][:],
xdf_m['lat'][:],
masked_average,
cmap=plt.cm.get_cmap('YlOrRd'),
transform=ccrs.PlateCarree()
)
# Modify figure style; add lat/lon grid and labels
# NOTE: There is a known issue with the coastlines for the pip installation of cartopy,
# The following is a work-around, and not required if using cartopy
# ax1.coastlines(color='black')
ax1.add_feature(cfeature.LAND, edgecolor='black', facecolor="none", linewidth=1, zorder=3)
gl = ax1.gridlines(draw_labels=True, linewidth=1, color='gray', alpha=0.5, linestyle='--')
gl.top_labels = False # hide top and right labels
gl.right_labels = False
'''
Cartopy's matplotlib gridliner takes over the xlabel and ylabel and uses it to manage
grid lines and labels.
To add labels we need to add text to the Axes, such as:'''
ax1.text(
-0.07, 0.49, 'Latitude [ $^o$ ]', fontsize=17, va='bottom', ha='center',
rotation='vertical', rotation_mode='anchor', transform=ax1.transAxes)
ax1.text(
0.5, -0.12, 'Longitude [ $^o$ ]', fontsize=17, va='bottom', ha='center',
rotation='horizontal', rotation_mode='anchor', transform=ax1.transAxes)
# Add colorbar
cb = fig1.colorbar(im, ax=ax1, label='W m$^{-2}$', fraction=0.045, pad=0.07, extend='both')
# Add title text
ax1.set_title(
'$\\bf{Mean\ OLR\ from\ HIRS\ Ed:2.7\ (January\ 1979-December\ 2018)}$',
fontsize=20, pad=25)
# and save the figure
fig1.savefig('./Example_1_HIRS_olr_mean.png', dpi=500, bbox_inches='tight')
/var/folders/l2/529q7bzs665bnrn7_wjx1nsr0000gn/T/ipykernel_91833/955912512.py:9: MatplotlibDeprecationWarning: The get_cmap function was deprecated in Matplotlib 3.7 and will be removed two minor releases later. Use ``matplotlib.colormaps[name]`` or ``matplotlib.colormaps.get_cmap(obj)`` instead.
cmap=plt.cm.get_cmap('YlOrRd'),
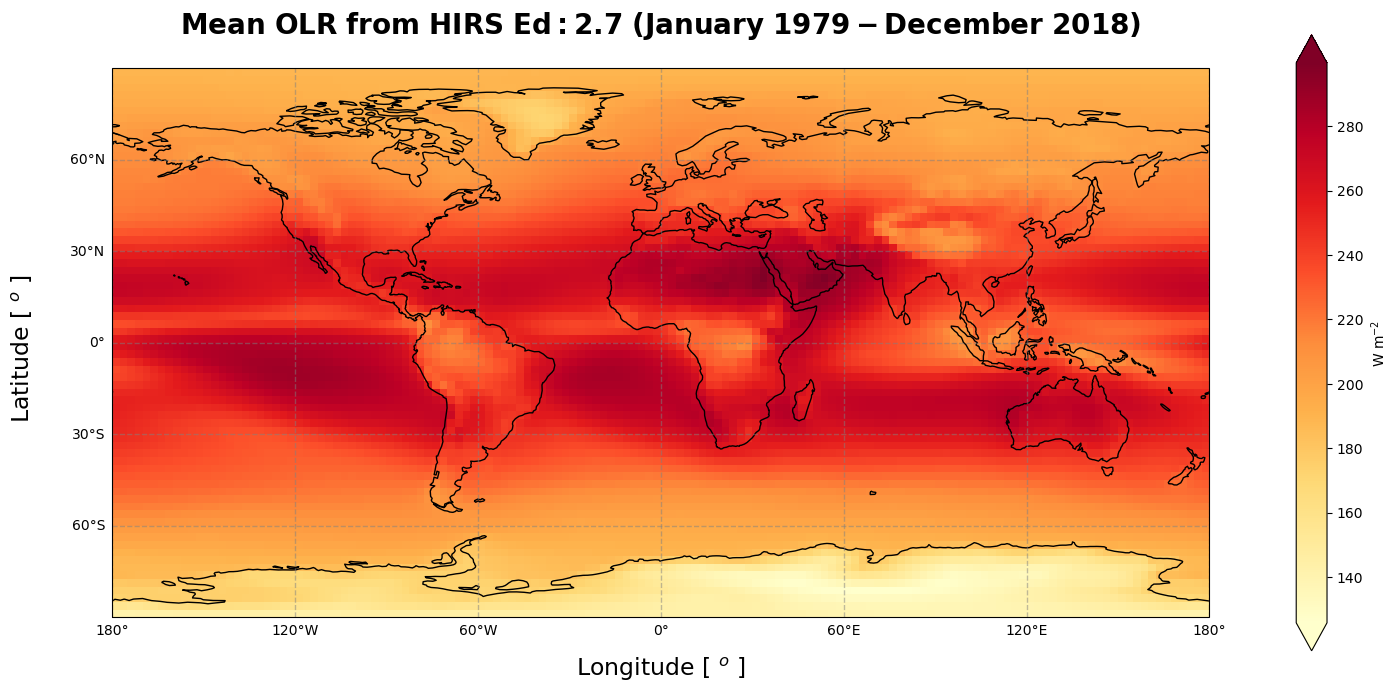
Figure 1 shows the time-averaged Outgoing Longwave Radiation over the period January 1979 - December 2018. The maximum values of the OLR are found in the tropics and it decreases toward the poles. The relative minimum near the equator, in yellow colour, corresponds to the ITCZ and the convection areas, where persistent and relatively high cloud cover reduces the LW radiation at the TOA. Antarctica is cooler than the corresponding northern latitudes (Harrison et al.).
Use case 2: Global time series of the OLR#
After looking at the time-averaged global distribution, in the next step, we further investigate the dataset. The OLR dataset is more than 40 years long, and another useful way of visualizing is the time series. We will calculate the global time series, plot it, and discuss the most important features.
We start by opening the combined data with Xarray open_dataset function
and subselect a time range from January 1979 to December 2018.
xdf = xr.open_dataset(merged_netcdf_file, decode_times=True, mask_and_scale=True)
xdf = xdf.sel(time=slice('1979-01-01', '2019-01-01'))
Apply weights and calculate the rolling mean#
Next, we need to to account for differences in area of grid cells for polar and equatorial regions. We give different weights for polar and equatorial regions, and the way to do this is to use the cosine of the latitude. We then calculate the global values by using sum method. And we calculate the 12-month rolling mean by using the rolling method.
# calculate normalized weights
_, lat_field = np.meshgrid(xdf.lon.values, xdf.lat.values)
weight = np.cos(np.pi * lat_field / 180)
data = np.ma.masked_invalid(xdf.olr)
weight[data.mask[0, :, :]] = np.nan
weight_normalized = weight / np.nansum(weight)
# Add weights as second Xarray Data variable and apply weights to the OLR
xdf['weight_normalized'] = xr.DataArray(
weight_normalized, coords=[xdf.lat.values, xdf.lon.values], dims=['lat', 'lon'])
xdf['olr_norma'] = xdf.olr * xdf.weight_normalized
# calculate the global values
xdf_m = xdf.olr_norma.sum(dim=['lat', 'lon'])
# calculate the 12-month rolling mean
xdf_mean_rolling = xdf_m.rolling(time=12, center=True).mean().dropna('time')
Plot data#
Now, let’s visualize the time series. Xarray offers built-in matplotlib methods to plot Data Arrays. We use the method plot to get the plot.
We also want to add custom xticks. Our x-axis is the time, and one of the ways to work with the time variable is to use library Pandas. This library can work with both date and time. We use method date_range to generate the ticks with frequency of two years.
# Plotting.
xdf_mean_rolling.plot(figsize=[16, 8])
# Add title, x- and y-labels
plt.title('$\\bf{HIRS\ OLR-Globe }$\nYearly rolling mean')
plt.ylabel("OLR [ W m$^{-2}$ ]", fontsize=17)
plt.xlabel("Year", fontsize=17)
# Custom x-ticks
dateStart = pd.to_datetime('1979-01-01', format='%Y-%m-%d')
date_End = pd.to_datetime('2019-01-01', format='%Y-%m-%d')
dates_rng = pd.date_range(dateStart, date_End, freq='2YS')
plt.xticks(dates_rng, [dtz.strftime('%Y') for dtz in dates_rng], rotation=45)
plt.savefig('./Example_2_olr_timeserie_Globe.png', dpi=500, bbox_inches='tight')
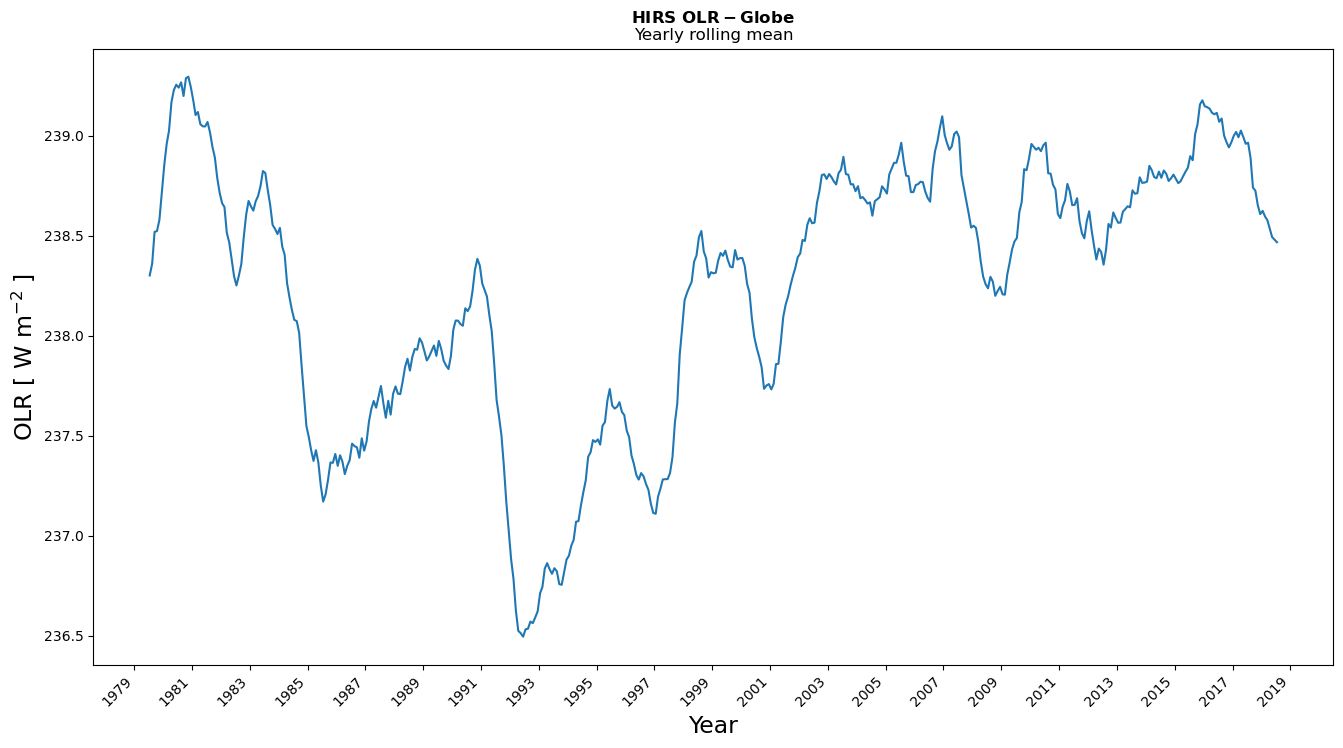
Figure 2, shows the evolution of the global mean of the OLR using a 12-month rolling mean. This long CDR shows some interesting features such as the drop of OLR due to a global radiative perturbation in response to volcanic eruptions, for instance, El Chichon in 1982 and Pinatubo in 1991. The main atmospheric thermal effects of these two eruptions persist for about two years after the eruption. The figure also shows some inter-annual variations that are suggested to be related to “El Niño” or “La Niña” Southern Oscillation.
Use case 3: OLR evolution in the Arctic#
In the final use case, we will calculate, plot and discuss the OLR time series in the Arctic region. We can re-use code from the previous use case, but we need to add one additional step: select the Arctic region from the original global dataset.
We start by reading the dataset with xarray open_dataset method. We have used sel method before to select the data based on time coordinate. This time, we will select the latitude coordinate label.
# Read the dataset
xdf = xr.open_dataset(merged_netcdf_file, decode_times=True, mask_and_scale=True)
# Select time and latitude range
xdf = xdf.sel(time=slice('1979-01-01', '2019-01-01'))
lat_slice = slice(70, 90)
xdf = xdf.sel(lat=lat_slice)
# Calculate normalized weights
_, lat_field = np.meshgrid(xdf.lon.values, xdf.lat.values)
weight = np.cos(np.pi*lat_field/180)
data = np.ma.masked_invalid(xdf.olr)
weight[data.mask[0, :, :]] = np.nan
weight_normalized = weight / np.nansum(weight)
# Add weights as second Xarray Data variable and apply weights to the OLR
xdf['weight_normalized'] = xr.DataArray(
weight_normalized, coords=[xdf.lat.values, xdf.lon.values], dims=['lat', 'lon'])
xdf['olr_norma'] = xdf.olr * xdf.weight_normalized
# calculate the global values
xdf_m = xdf.olr_norma.sum(dim=['lat', 'lon'])
# calculate the 12-month rolling mean
xdf_Arctic_mean_rolling = xdf_m.rolling(time=12, center=True).mean().dropna('time')
# Plotting.
xdf_Arctic_mean_rolling.plot(figsize=[16, 8])
# Add title, x- and y-labels
plt.title('$\\bf{HIRS\ OLR-Arctic\ [70°N, 90°N] }$\nYearly rolling mean')
plt.ylabel("OLR [ W m$^{-2}$ ]", fontsize=17)
plt.xlabel("Year", fontsize=17)
# Custom x ticks
dateStart = pd.to_datetime('1979-01-01', format='%Y-%m-%d')
date_End = pd.to_datetime('2019-01-01', format='%Y-%m-%d')
dates_rng = pd.date_range(dateStart, date_End, freq='2YS')
plt.xticks(dates_rng, [dtz.strftime('%Y') for dtz in dates_rng], rotation=45)
# Save figure to the disk
plt.savefig('./Example_3_olr_timeserie_Arctic.png', dpi=500, bbox_inches='tight')
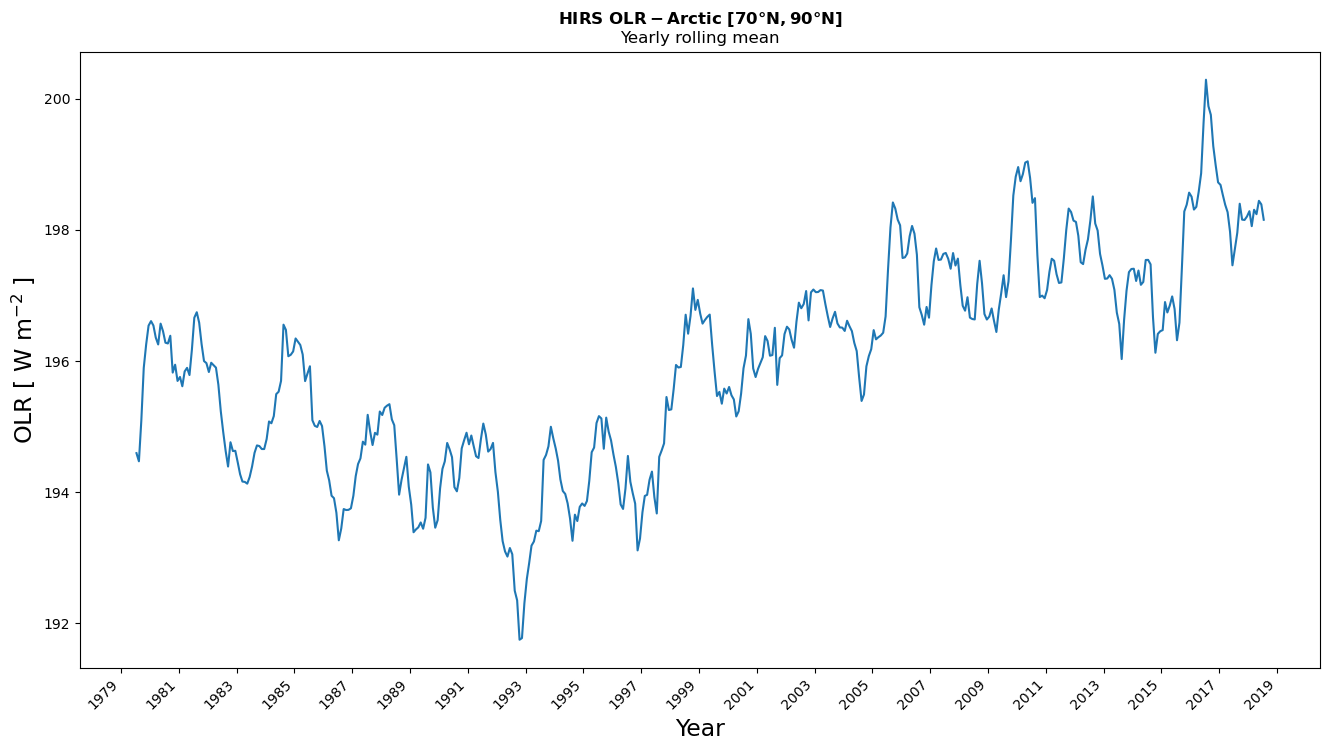
Figure 3, shows the evolution of the OLR in the Arctic region [70°N-90°N] for the period 1979-2019 also using a yearly rolling mean. From the image, we can infer an increase in the OLR in the Arctic region with time. This increase is strongly marked as from 1998 and in line with the increase of temperature in the Arctic (Hansen et al, 2010), while the relative stability of the first part of the time series is more difficult to interpret due to the major volcanic eruptions in this period.
Get more information about Earth Radiation Budget:#
References#
Hansen, J., Ruedy, R., Sato, M., & Lo, K., (2010). Global surface temperature change. Reviews of Geophysics, 48(4).
Harrison, E.F., Gurney, R. J., Foster, J. L., Gurney, R. J., & Parkinson, C. L. (1993). Atlas of satellite observations related to global change. Chapter: Radiation Budget at the top of the atmosphere. Cambridge University Press.
Back to top the Page