

Calculation of global climatology and annual cycles of Cloud Fractional Cover from EUMETSAT’s CM SAF CLARA-A3 dataset#
This notebook provides you with an introduction to one variable of the EUMETSAT’s CM SAF CLARA-A3 dataset available at the Climate Data Store (CDS). The overall dataset contains data for Essential Climate Variables (ECVs) Cloud Properties as well as Surface - and Earth Radiation Budget, while this notebook focuses on Cloud Fractional Cover as part of the ECV Cloud Properties available here: Cloud properties global gridded monthly and daily data from 1979 to present derived from satellite observations.
In addition, the tutorial is about the Surface downwelling longwave/shortwave flux (as part of the ECV Surface Radiation Budget) to demonstrate the relation between clouds and radiation. The data is also available at the CDS: Surface radiation budget from 1979 to present derived from satellite observations.
The tutorial covers the full process from scratch to end and starts with a short introdution to the dataset and how to access the data from the Climate Data Store of the Copernicus Climate Change Service (C3S). This is followed by a step-by-step guide on how to process and visualize the data. Once you feel comfortable with the python code, you are invited to adjust or extend the code according to your interests! After a short introduction about how to use a Jupyter notebook the analysis starts!

Figure 1: Summary of following options for analysis of a cloud and radiation dataset: Climatology of cloud fractional cover (a), annual cycle of cloud fractional cover for three selected cities (b) and climatology of surface downwelling longwave radiation (c); each based on the CLARA-A3 dataset and data from 1979 - 2020.
Introduction#
This tutorial is about cloud and radiation parameters of EUMETSAT’s CM SAF CLARA-A3 dataset. It covers step by step the process from retrieving the data to the processing and finally the visualisation of the results.
The CLARA-A3 dataset provides information of various Cloud Properties parameters as well as Surface Radiation Budget (SRB) and Earth Radiation Budget (ERB) parameters. Each ECV is covered by an own Jupyter Notebook (please also take a look at CLARA-A3 SRB and CLARA-A3 ERB).
This notebook focuses on the Cloud Fractional Cover (CFC) as well as Surface Downwelling Longwave and Surface Incoming Shortwave Radiation (SDL and SIS, respectively) as an extra feature to demonstrate the connection between clouds and radiation. A first Use Case provides a general idea how clouds are distributed all over the globe (averaged for the time period of 1979-2020). A second Use Case provides a closer look on three selected locations and their corresponding annual cycles in terms of cloud coverage. Those locations are defined by their geographical coordinates. Feel free to change the code and investigate the cloud coverage at more locations of your interest! To sum it up and link to the connection between clouds and radiation, a third Use Case covers two radiation parameters and focuses on climatologies of Surface Downwelling Longwave and Surface Incoming Shortwave Radiation.
The CLARA-A3 dataset is the successor of CLARA-A2.1 and comprises more than 44 years (Latest status: 02/2024) of continuous observations of clouds from space, thereby monitoring their spatial and temporal variability on Earth. CLARA-A3 comes not just with a temporal extension, but also with significant algorithm, calibration and product improvements.
As measurements cover the entire globe and time-coverage has reached climatological timescales by now, the dataset is first and foremost well suited to analyse long-term characteristics and climatological trends of clouds.
Questions about the cloud distribution and trends are crucial as clouds play a decisive role in the Earth’s climate system: They produce precipitation and strongly interact with radiation, thereby define the Earth’s temperature. Therefore, the CLARA-A3 climatology might be useful to e.g. determine the radiative effects of clouds on climate and to study to what extent changes in the Earth’s radiation budget can be attributed to changes in clouds. Furthermore it can be used as reference to assess e.g. the prediction of clouds by climate and forecast models.
As clouds strongly shield sunlight from the Earth’s surface, the above mentioned points might also concern, among others, the solar energy industry as well as tourism. Some regions are more suited for allocating photovoltaic power plants or spending holidays with nice weather conditions.
In the following, some simple illustrations are presented to prompt ideas on the usage, visualisation and analysis of the CLARA-A3 dataset. It comprises several variables to capture various cloud and radiation characteristics.
How to access the notebook#
This tutorial is in the form of a Jupyter notebook. It can be run on a cloud environment, or on your own computer. You will not need to install any software for the training as there are a number of free cloud-based services to create, edit, run and export Jupyter notebooks such as this. Here are some suggestions (simply click on one of the links below to run the notebook):
| Run the tutorial via free cloud platforms: |
|
|
|---|
If you would like to run this notebook in your own environment, we suggest you install Anaconda, which contains most of the libraries you will need. You will also need to install Xarray for working with multidimensional data in netcdf files, and the CDS API (pip install cdsapi) for downloading data programatically from the CDS.
Dataset description#
Please find further information about the datasets as well as the data in the Climate Data Store sections “Overview”, “Download data” and “Documentation”:
Cloud Properties: Cloud properties global gridded monthly and daily data from 1979 to present derived from satellite observations
In addition:
Surface Radiation Budget: Surface radiation budget from 1979 to present derived from satellite observations
Earth Radiation Budget: Earth’s radiation budget from 1979 to present derived from satellite observations
The Overview section provides you with a general introduction to clouds and their role in the atmosphere. In addition, information on the available datasets are provided in the form of overview texts as well as general facts about coverage, resolution, etc. in a table.
The Download data section provides you with the download form and access to the data.
The Documentation section contains useful documents e.g. description of retrieval algorithms, validation and user manual.
Search and download data#
Import libraries#
Processing (climate) data with python requires some libraries. Libraries contain different functions for e.g. reading, processing and visualisation of large amounts of data and make it easier to work with it.
The basic data format for climate data is NetCDF. This is also the case for CLARA-A3 and to handle this well we use a library to work with multidimensional arrays, named Xarray. For the calculations we use Numpy, which provides various mathmatical operations. We also need libraries for plotting and viewing the data, in this case we will use Matplotlib and Cartopy.
Before we start analysing the data we need to take advantage of one of the two options to get the data:
Fill in the download form on the CDS page and simply download the data to the download folder of your computer - not preferred
Use the API (Application Programming Interface) for programmatic access to the CDS data - preferred, check [Chapter 2.3 Enter CDS API key]
For this we import the cdsapi-library and a library to unzip the downloaded zip files.
# Download data from CDS via cdsapi
import cdsapi
# Library to work with zip-archives and os (operating system)-functions
import zipfile
import os
# Libraries for data reading and processing
import xarray as xr
import numpy as np
# Libraries for visualisation in form of maps or graphs
from matplotlib import pyplot as plt
import cartopy.crs as ccrs
Download Data using CDS API#
To set up your CDS API credentials, please login/register on the CDS, then follow the instructions here to obtain your API key.
You can add this API key to your current session by uncommenting the code below and replacing ######### with your API key.
URL = 'https://cds.climate.copernicus.eu/api'
KEY = '######################################'
Set up directories for the data#
Next, we specify a data directory (datadir) in which we create a Download and Data folder to save the downloaded zip-file and store the unzipped files. Data is separated for CLD and SRB.
# Definition of the path, datadir is defined as the current directory (./)
datadir = './'
# Definition of path, we aim to create a folder named "Download" in the current directory
download = './Download'
# Creation of the above-defined path
os.makedirs(download, exist_ok=True)
# Same steps for Data and subdirectories CLD and SRB
data = './Data'
os.makedirs(data, exist_ok=True)
CLD = './Data/CLD'
os.makedirs(CLD, exist_ok=True)
SRB = './Data/SRB'
os.makedirs(SRB, exist_ok=True)
Search for data#
For this tutorial we need data for Cloud Properties first, so please either click on “Datasets” in the CDS and search for “Cloud Properties” or simply click on: https://cds.climate.copernicus.eu/cdsapp#!/dataset/satellite-cloud-properties?tab=overview. The name of the Cloud Properties landing page is: Cloud properties global gridded monthly and daily data from 1979 to present derived from satellite observations.
Once you reached the landing page, feel free to have a look at the documentation and information provided.
The data can be found in the “Download data”-tab with a form to select certain variables, years etc. For our use case we select as follows:
Product family: CLARA-A3 (CM SAF cLoud, Albedo and surface RAdiation dataset from AVHRR data)
Origin: EUMETSAT (European Organisation for the Exploitation of Meteorological Satellites)
Variable: Cloud fraction
Climate data record type: Thematic Climate Data Record (TCDR)
Time aggregation: Monthly mean
Year: Every year from 1979-2020 (shortcut with “Select all” at the bottom right)
Month: Every month from January to December (shortcut with “Select all” at the bottom right)
Geographical area: Whole available region
Format: Zip file (.zip)
At the bottom left of the page, click on Show API request and copy & paste the text into the Jupyter notebook.
Download data#
… Having copied the API request into the cell below, running this will retrieve and download the data we requested into our local directory. However, before we run the cell below, the terms and conditions of this particular dataset need to have been accepted in the CDS. The option to view and accept these conditions is given at the end of the download form, just above the “Show API request” option.
Note: To make sure the zip-file will be saved in the correct place and with an appropriate name you can adjust the last line like below. The Download folder in the current directory was created before and the download file is named download_cld_tcdr.zip.
Note: The download may take a few minutes. Feel free to have a look at the various information on the Cloud Properties page in the CDS or already get familiar with the next steps.
c = cdsapi.Client(
url=URL,
key=KEY
)
c.retrieve(
'satellite-cloud-properties',
{
"product_family": "clara_a3",
"origin": "eumetsat",
"variable": ["cloud_fraction"],
"climate_data_record_type": "thematic_climate_data_record",
"time_aggregation": "monthly_mean",
"year": [
"1979", "1980", "1981",
"1982", "1983", "1984",
"1985", "1986", "1987",
"1988", "1989", "1990",
"1991", "1992", "1993",
"1994", "1995", "1996",
"1997", "1998", "1999",
"2000", "2001", "2002",
"2003", "2004", "2005",
"2006", "2007", "2008",
"2009", "2010", "2011",
"2012", "2013", "2014",
"2015", "2016", "2017",
"2018", "2019", "2020"
],
"month": [
"01", "02", "03",
"04", "05", "06",
"07", "08", "09",
"10", "11", "12"
]
},
f'{datadir}Download/download_cld.zip')
2024-12-11 14:30:12,939 WARNING [2024-12-11T14:30:12.942097] You are using a deprecated API endpoint. If you are using cdsapi, please upgrade to the latest version.
2024-12-11 14:30:12,940 INFO Request ID is 3b6d9c49-bf69-419e-a407-a1ea03f652ef
2024-12-11 14:30:13,093 INFO status has been updated to accepted
2024-12-11 14:30:14,686 INFO status has been updated to running
2024-12-11 14:30:17,187 INFO status has been updated to successful
'./Download/download_cld.zip'
The zip-file should be downloaded and saved at the correct place.
The following lines unzip the data. datadir + ‘Download/download_cld.zip is the path to the zip-file. The first line constructs a ZipFile() object, the second line applies the function extractall to extract the content.
datadir + ‘/Data/CLD/’ is the path we want to store the files.
with zipfile.ZipFile(datadir + '/Download/download_cld.zip', 'r') as zip_ref:
zip_ref.extractall(datadir + 'Data/CLD/')
With the zip-file unziped and files at the right place we can start reading and processing the data.
The following line starting with “file” considers only files in the given directory starting the “CFCmm” and ending with “.nc” and creates a list with all matching files. The * means “everything” and takes every file into account. This is quite useful since year and month are part of the file names.
The second line reads the defined file list with the xarray function “open_mfdataset” (mf - multiple file) and concatenates them according to the time dimension.
file = datadir + '/Data/CLD/CFCmm*.nc'
dataset_cfc = xr.open_mfdataset(file, combine='nested', concat_dim='time')
Please find below the xarray dataset of the Cloud Properties exemplary:
It provides information about the:
Dimensions: Lat and Lon with 0.25°x0.25° resolution and a lenght of 720/1440 and 504 months (42 years * 12 months)
Coordinates: Spatial coordinates for Latitude and Longitude, temporal coordinates for time
Data variables: List of different variables (in our case “cfc” is relevant)
Attributes: Various important information about the dataset
dataset_cfc
<xarray.Dataset> Size: 59GB
Dimensions: (time: 504, lat: 720, bndsize: 2, lon: 1440)
Coordinates:
* lat (lat) float32 3kB -89.88 -89.62 -89.38 ... 89.38 89.62 89.88
* lon (lon) float32 6kB -179.9 -179.6 -179.4 ... 179.4 179.6 179.9
* time (time) datetime64[ns] 4kB 1979-01-01 ... 2020-12-01
Dimensions without coordinates: bndsize
Data variables: (12/18)
lat_bnds (time, lat, bndsize) float32 3MB dask.array<chunksize=(1, 720, 2), meta=np.ndarray>
lon_bnds (time, lon, bndsize) float32 6MB dask.array<chunksize=(1, 1440, 2), meta=np.ndarray>
time_bnds (time, bndsize) datetime64[ns] 8kB dask.array<chunksize=(1, 2), meta=np.ndarray>
record_status (time) int8 504B dask.array<chunksize=(1,), meta=np.ndarray>
nobs (time, lat, lon) float64 4GB dask.array<chunksize=(1, 720, 1440), meta=np.ndarray>
nobs_day (time, lat, lon) float64 4GB dask.array<chunksize=(1, 720, 1440), meta=np.ndarray>
... ...
cfc_day (time, lat, lon) float64 4GB dask.array<chunksize=(1, 720, 1440), meta=np.ndarray>
cfc_night (time, lat, lon) float64 4GB dask.array<chunksize=(1, 720, 1440), meta=np.ndarray>
cma_prob (time, lat, lon) float64 4GB dask.array<chunksize=(1, 720, 1440), meta=np.ndarray>
cma_prob_day (time, lat, lon) float64 4GB dask.array<chunksize=(1, 720, 1440), meta=np.ndarray>
cma_prob_night (time, lat, lon) float64 4GB dask.array<chunksize=(1, 720, 1440), meta=np.ndarray>
cfc_unc_mean (time, lat, lon) float64 4GB dask.array<chunksize=(1, 720, 1440), meta=np.ndarray>
Attributes: (12/37)
title: CM SAF cLoud, Albedo and RAdiation dataset, ...
summary: This file contains AVHRR-based Thematic Clim...
id: DOI:10.5676/EUM_SAF_CM/CLARA_AVHRR/V003
product_version: 3.0
creator_name: DE/DWD
creator_email: contact.cmsaf@dwd.de
... ...
CMSAF_included_Daily_Means: 31.0
CMSAF_L1_processor: PyGAC, level1c4pps
CMSAF_L2_processor: PPSv2018-patch5
CMSAF_L3_processor: CMSAFGACL3_V3.0
variable_id: cfc
license: The CM SAF data are owned by EUMETSAT and ar...In advance of the following processing and visualisation part we create a directory where to save the figures.
The following lines create the directory Figures and define the path as figpath.
figures = './Figures'
os.makedirs(figures, exist_ok=True)
figpath = datadir + 'Figures/'
Use Case 1: Visualisation of mean global cloud distribution#
Use Case #1 aims to give a general overview about the global distribution of clouds. We therefore use the recently downloaded dataset and plot a map with a temporal average (1979-2020) of the cloud fractional cover (cfc) variable from the CLARA-A3 dataset.
Calculation of the temporal average of cloud fractional cover#
We therefore calculate the temporal average with the function np.nanmean. np is short for numpy and a library for mathmatical working with arrays. nanmean averages the data and ignores nan’s. This operation is applied to dataset_cfc and the variable “cfc”. axis=0 averages over the first axis, which is “time” in this case. This leads to a two-dimensional result with an average over time.
# Calculate temporal average
average = dataset_cfc['cfc'].mean(dim="time")
# Get longitude and latitude coordinates. Both are variables of the dataset and available with
# the ".variables['lat/lon']" function; [:] usually means ["from":"till"] but
# without numbers it means "everything"
lon = dataset_cfc.variables['lon']
lat = dataset_cfc.variables['lat']
Plot of the temporal average of cloud fractional cover#
With the caluculation done the data is ready for a plot. Please find the plot and settings in the next section.
Some further notes:
Matplotlib provides a wide range of colorbars: https://matplotlib.org/stable/users/explain/colors/colormaps.html; the addition _r reverses the colorbar
The “add_subplot” part provides the option to plot more than one figure (e.g. a 2x2 matrix with four plots together). In this case (1,1,1) means that the panel is a 1x1 matrix and the following plot is the first subplot.
# Create figure and size
fig = plt.figure(figsize=(15, 8))
# Create the figure panel and define the Cartopy map projection (PlateCarree)
ax = fig.add_subplot(1, 1, 1, projection=ccrs.PlateCarree())
# Plot the data and set colorbar, minimum and maximum values
im = plt.pcolormesh(lon, lat, average, cmap='Blues_r', vmin=0, vmax=100)
# Set title and size
ax.set_title('Mean Cloud Fractional Cover from CLARA-A3 for 1979-2020', fontsize=16)
# Define gridlines with linewidth, color, opacity and style
gl = ax.gridlines(linewidth=1, color='gray', alpha=0.5, linestyle='--')
# Set x- and y-axis labels to True or False
gl.bottom_labels = True
gl.left_labels = True
# Set coastlines
ax.coastlines()
# Set colorbar and adjust size, location and text
cbar = plt.colorbar(im, fraction=0.05, pad=0.05, orientation='horizontal')
cbar.set_label('Cloud Fractional Cover (%)')
# Save figure in defined path and name
plt.savefig(figpath + 'Cloud_mean.png')
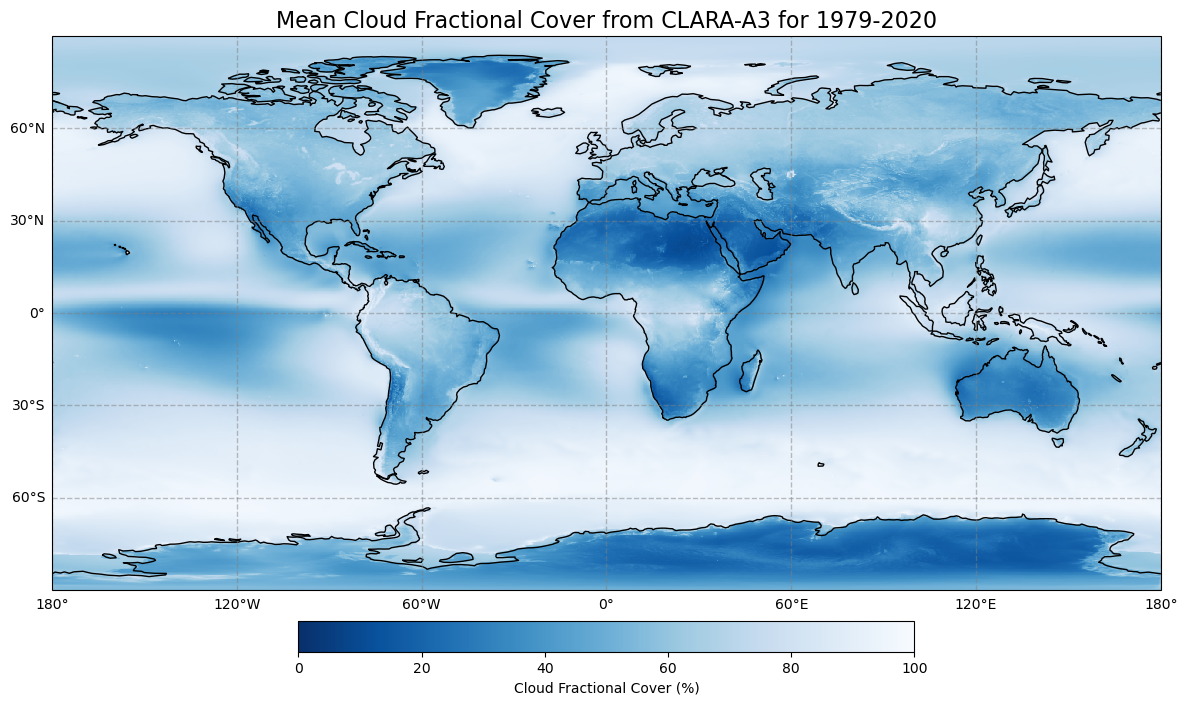
Figure 4: Global climatology of cloud fractional cover from 1979 - 2020 based on EUMETSAT’s CM SAF CLARA-A3 dataset.
Figure 4 shows the time-averaged global distribution of clouds on Earth. It has been calculated as a time average over the monthly mean cloud fractional cover data from 1979-2020 based on the CLARA-A3 dataset. As shown here, especially cloudy regions can be found along the storm tracks of the midlatitudes, which are known for the frequent occurence of cyclones. They typically result in vertical motion of air, a prerequisite for the formation of clouds. High concentrations of clouds also appear in the tropics near the equator, where strong insolation triggers intense convection, thus cloud formation (compare with Inter-Tropical Convergence Zone, ITCZ). The smallest amount are mainly present in the subtropics in Australia, North Africa, Southern Africa, and Soutwest South America, where large-scale downwelling motion generally prevails.
Use case 2: Visualisation of seasonal variations of clouds#
Use Case #2 shows three annual cycles of cloud fractional cover for different locations. As insolation and flow patterns vary significantly over the year in many parts of the Earth, the mean presence of clouds also exhibits seasonal differences. As one example that neatly demonstrates steady variations throughout the year, Use Case #2 shows the mean monthly evolution of the fractional cloud cover for Frankfurt (Germany), Mumbai (India) and Darwin (Australia).
First we calculate the mean, minimum and maximum annual cycles using the Xarray.groupby method
# Group data by month and calculate the mean, maximum and minimum values
group_cfc = dataset_cfc.groupby('time.month')
annual_cycle_mean = group_cfc.mean(dim='time')
annual_cycle_max = group_cfc.max(dim='time')
annual_cycle_min = group_cfc.min(dim='time')
annual_cycle_mean
<xarray.Dataset> Size: 1GB
Dimensions: (month: 12, lat: 720, bndsize: 2, lon: 1440)
Coordinates:
* lat (lat) float32 3kB -89.88 -89.62 -89.38 ... 89.38 89.62 89.88
* lon (lon) float32 6kB -179.9 -179.6 -179.4 ... 179.4 179.6 179.9
* month (month) int64 96B 1 2 3 4 5 6 7 8 9 10 11 12
Dimensions without coordinates: bndsize
Data variables: (12/17)
lat_bnds (month, lat, bndsize) float32 69kB dask.array<chunksize=(1, 720, 2), meta=np.ndarray>
lon_bnds (month, lon, bndsize) float32 138kB dask.array<chunksize=(1, 1440, 2), meta=np.ndarray>
record_status (month) float64 96B dask.array<chunksize=(1,), meta=np.ndarray>
nobs (month, lat, lon) float64 100MB dask.array<chunksize=(1, 720, 1440), meta=np.ndarray>
nobs_day (month, lat, lon) float64 100MB dask.array<chunksize=(1, 720, 1440), meta=np.ndarray>
nobs_night (month, lat, lon) float64 100MB dask.array<chunksize=(1, 720, 1440), meta=np.ndarray>
... ...
cfc_day (month, lat, lon) float64 100MB dask.array<chunksize=(1, 720, 1440), meta=np.ndarray>
cfc_night (month, lat, lon) float64 100MB dask.array<chunksize=(1, 720, 1440), meta=np.ndarray>
cma_prob (month, lat, lon) float64 100MB dask.array<chunksize=(1, 720, 1440), meta=np.ndarray>
cma_prob_day (month, lat, lon) float64 100MB dask.array<chunksize=(1, 720, 1440), meta=np.ndarray>
cma_prob_night (month, lat, lon) float64 100MB dask.array<chunksize=(1, 720, 1440), meta=np.ndarray>
cfc_unc_mean (month, lat, lon) float64 100MB dask.array<chunksize=(1, 720, 1440), meta=np.ndarray>
Attributes: (12/37)
title: CM SAF cLoud, Albedo and RAdiation dataset, ...
summary: This file contains AVHRR-based Thematic Clim...
id: DOI:10.5676/EUM_SAF_CM/CLARA_AVHRR/V003
product_version: 3.0
creator_name: DE/DWD
creator_email: contact.cmsaf@dwd.de
... ...
CMSAF_included_Daily_Means: 31.0
CMSAF_L1_processor: PyGAC, level1c4pps
CMSAF_L2_processor: PPSv2018-patch5
CMSAF_L3_processor: CMSAFGACL3_V3.0
variable_id: cfc
license: The CM SAF data are owned by EUMETSAT and ar...Plot cloud coverage annual cycles for three different locations#
We define three locations of interest in terms of latitude and longitude coordinates. Feel free to discover different locations and change the coordinates according to your interests! The basic setup consists of Frankfurt (Germany) with a warm and temperate climate of central Europe, Mumbai (India) with its influence of the monsoon and Darwin (Australia) in the tropical savanna climate.
points = {
'Frankfurt, Germany': [50.11, 8.68],
'Mumbai, India': [19.08, 72.88],
'Darwin, Australia': [-12.46, 130.84]
}
# X-axis values to plot against
year = ['Jan', 'Feb', 'Mar', 'Apr', 'May', 'Jun', 'Jul', 'Aug', 'Sep', 'Oct', 'Nov', 'Dec']
Now the actual calculation and visualisation takes place. The for-loop defines that the steps will be runned three times (range(0,3) with indices 0, 1 and 2). The first run with index “0” takes the first element of a vector with the addition [i], e.g. point_lat[i] and therefore point_lat_1 (see above).
fig, ax = plt.subplots(nrows=1, ncols=3, figsize=(15, 8))
fig.suptitle('Annual cycle of Cloud Fractional Cover from CLARA-A3 for 1979-2020', fontsize=16)
# Loop over each point and plot the data
for i, label in enumerate(points):
(latitude, longitude) = points[label]
point_mean = annual_cycle_mean.cfc.sel(lat=latitude, lon=longitude, method='nearest')
point_max = annual_cycle_max.cfc.sel(lat=latitude, lon=longitude, method='nearest')
point_min = annual_cycle_min.cfc.sel(lat=latitude, lon=longitude, method='nearest')
# Plot data and adjust color, linewidth and label
ax[i].plot(year, point_mean, color='black', label=label[i], linewidth=2)
# Fill space between min and max values
ax[i].fill_between(year, point_min, point_max, color='darkblue')
# Set legend, axis-labels and ticks, the y-axis label is just defined for the left/first plot
ax[i].legend()
ax[0].set_ylabel('CFC in %', fontsize=14)
ax[i].set_ylim(0, 100)
# Save figure in defined path and name
plt.savefig(figpath + 'Cycle_' + str(label[i]) + '.png')
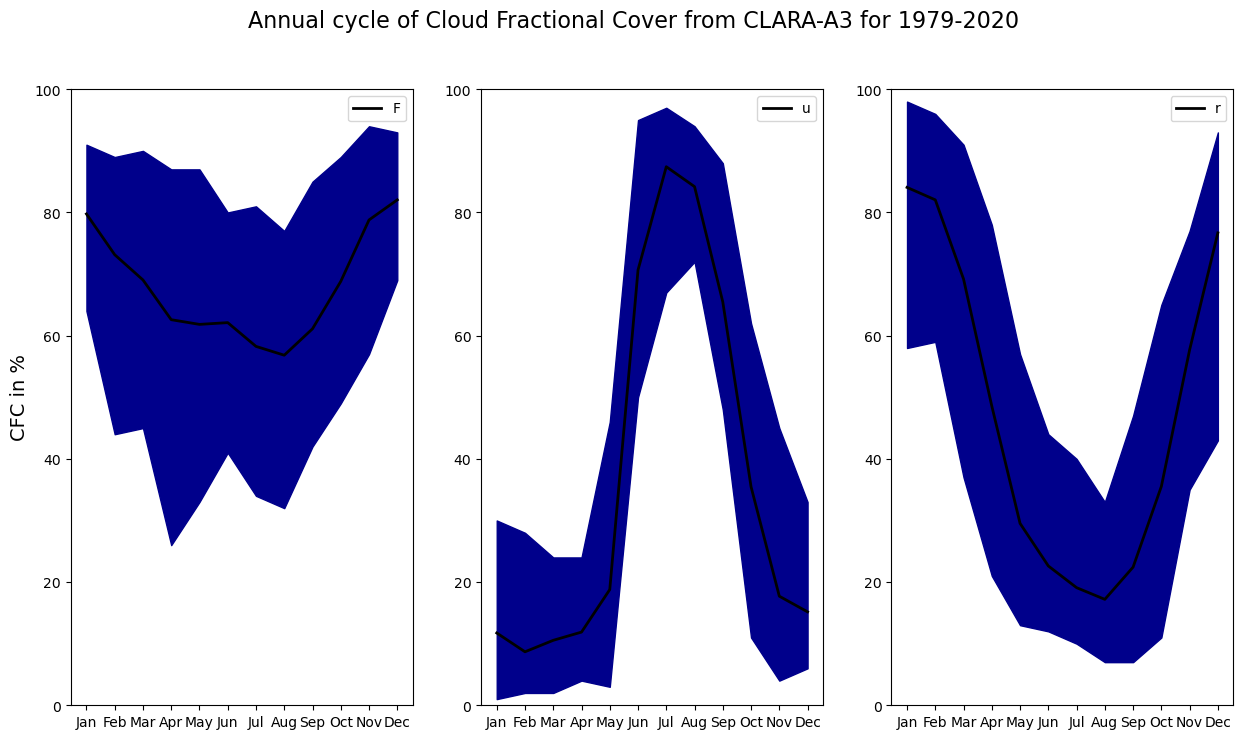
Figure 5: Averaged annual cycle of cloud fractional cover for three cites: (a) Frankfurt, Germany, (b) Mumbai, India and (c) Darwin, Australia. The calculation is based on CLARA-A3 data from 1979 - 2020.
Figure 5 shows the mean monthly annual cycle of the fractional cloud cover near to Mumbai, a city situated in the Southwest of India. Mumbai exhibits a very strong seasonal cycle in cloud coverage with averages reaching up to 90% in summer and less than 20% in winter. This is due to the Asian monsoon, advecting dry continental air in winter and moist oceanic air in summer to India. As counterpart to the Asian monsoon, a further figure shows the north Australian monsoon, showing fractional cloud cover data next to Darwin, Australia.
Annual cycles are not only observed in the subtropical monsoon regions, but also e.g. in midlatitudes, although much less pronounced. A further figure depicts the monthly mean cloudiness near to Frankfurt, Germany. The amplitude is considerably smaller, but a slightly larger amount of cloud cover is evident in winter. This can be ascribed to increased cyclonic activity in winter due to particulary large differences in temperatures between the equator and the poles.
The blue shaddow is defined by the minimum and maximum month out of all 42 years (e.g. the lower end of January for Frankfurt is the January from 1979 - 2020 with the least cloud coverage).
Use case 3: Visualisation of radiative effects of clouds#
To demonstrate the basic relation between clouds and radiation, which is why clouds are ascribed a crucial role in the Earth’s climate system, Figure 6 presents time-averaged data from the CLARA-A3 dataset on radiation. This dataset was simultaneously compiled with the CLARA-A3 dataset on clouds by EUMETSAT’s CM SAF.
Download and calculation of temporal average of surface downwelling longwave/shortwave radiation#
The calculation of the temporal-averaged radiation is similar to the first Use Case but with different variables.
Please click on “Datasets” in the bar at the top and either search for “Surface Radiation Budget” or click on https://cds.climate.copernicus.eu/cdsapp#!/dataset/satellite-surface-radiation-budget?tab=overview. The name of the landing page is Surface radiation budget from 1979 to present derived from satellite observations.
Please select in the “Download data” tab the following:
Product family: CLARA-A3 (CM SAF cLoud, Albedo and surface RAdiation dataset from AVHRR data)
Origin: EUMETSAT (European Organisation for the Exploitation of Meteorological Satellites)
Variable: Surface downwelling shortwave flux and Surface downwelling longwave flux
Climate data record type: Thematic Climate Data Record (TCDR)
Time aggregation: Monthly mean
Year: Every year from 1979-2020 (shortcut with “Select all” at the bottom right)
Month: Every month from January to December (shortcut with “Select all” at the bottom right)
Geographical area: Whole available region
Format: Zip file (.zip)
Please click on Show API request. Copy & paste the code to your Jupyter Notebook and adjust the last line accordingly. Watch out to accept the Terms of use.
c = cdsapi.Client(
url=URL,
key=KEY
)
c.retrieve(
'satellite-surface-radiation-budget',
{
'product_family': 'clara_a3',
'origin': 'eumetsat',
'variable': [
'surface_downwelling_longwave_flux', 'surface_downwelling_shortwave_flux',
],
'climate_data_record_type': 'thematic_climate_data_record',
'time_aggregation': 'monthly_mean',
'year': [
'1979', '1980', '1981',
'1982', '1983', '1984',
'1985', '1986', '1987',
'1988', '1989', '1990',
'1991', '1992', '1993',
'1994', '1995', '1996',
'1997', '1998', '1999',
'2000', '2001', '2002',
'2003', '2004', '2005',
'2006', '2007', '2008',
'2009', '2010', '2011',
'2012', '2013', '2014',
'2015', '2016', '2017',
'2018', '2019', '2020',
],
'month': [
'01', '02', '03',
'04', '05', '06',
'07', '08', '09',
'10', '11', '12',
],
'format': 'zip',
},
f'{datadir}Download/download_srb.zip')
2024-12-11 15:22:09,062 WARNING [2024-12-11T15:22:09.069956] You are using a deprecated API endpoint. If you are using cdsapi, please upgrade to the latest version.
2024-12-11 15:22:09,063 INFO Request ID is c3d0b372-2c27-49c3-98e5-7083fb03b139
2024-12-11 15:22:09,197 INFO status has been updated to accepted
2024-12-11 15:22:10,820 INFO status has been updated to running
2024-12-11 15:32:27,623 INFO status has been updated to successful
'./Download/download_srb.zip'
The next steps are a repeat of the way the cloud fractional cover data was processed before:
Unzip the files
Create list with files
Read file list via “xr.open_mfdataset”
Temporal average of data
with zipfile.ZipFile(datadir + 'Download/download_srb.zip', 'r') as zip_ref:
zip_ref.extractall(datadir + 'Data/SRB/')
file = datadir + 'Data/SRB/SDLmm*.nc'
dataset_sdl = xr.open_mfdataset(file, combine='nested', concat_dim='time')
file = datadir + 'Data/SRB/SISmm*.nc'
dataset_sis = xr.open_mfdataset(file, combine='nested', concat_dim='time')
# Calculate temporal average of dataset_sdl/sis and corresponding variables, np.nanmean averages and
# ignores nan's
average_sdl = dataset_sdl['SDL'].mean(dim='time')
average_sis = dataset_sis['SIS'].mean(dim='time')
Plot of the temporal average of surface downwelling longwave/shortwave radiation#
Similar to Use Case 2 more than one figure will be created. This gives us the chance to use a loop with two runs. A set of vectors with two entries is created below, using the first entry for SDL and the second entry for SIS.
data = [average_sdl, average_sis]
title = ['Mean Surface Downwelling Longwave Radiation from CLARA-A3 for 1979-2020',
'Mean Surface Downwelling Shortwave Radiation from CLARA-A3 for 1979-2020']
var = ['SDL', 'SIS']
cbar_text = ['Surface Downwelling Longwave Radiation (W/m²)',
'Surface Incoming Shortwave Radiation (W/m²)']
lowerlimit = [50, 0]
upperlimit = [500, 320]
Following the visualisation takes place with a similar setup compared to Use Case 1. The loop makes sure everything happens twice for Surface Downwelling Longwave Radiation and Surface Downwelling Shortwave Radiation.
for i in range(0, 2):
# Create figure and size
fig = plt.figure(figsize=(15, 8))
# Create the figure panel and define the Cartopy map projection (PlateCarree)
ax = fig.add_subplot(1, 1, 1, projection=ccrs.PlateCarree())
# Plot the data and set colorbar, minimum and maximum values
im = plt.pcolormesh(lon, lat, data[i], cmap='hot_r', vmin=lowerlimit[i], vmax=upperlimit[i])
# Set title and size
ax.set_title(title[i], fontsize=16)
# Define gridlabels and lines
gl = ax.gridlines(linewidth=1, color='gray', alpha=0.5, linestyle='--')
gl.bottom_labels = True
gl.left_labels = True
gl.xlines = True
gl.ylines = True
# Set coastlines
ax.coastlines()
# Set colorbar and adjust size, location and text
cbar = plt.colorbar(im, fraction=0.05, pad=0.05, orientation='horizontal')
cbar.set_label(cbar_text[i])
# Save figure in defined path and name
plt.savefig(figpath + 'Radiation_' + str(var[i]) + '.png')
# Show plot
plt.show()
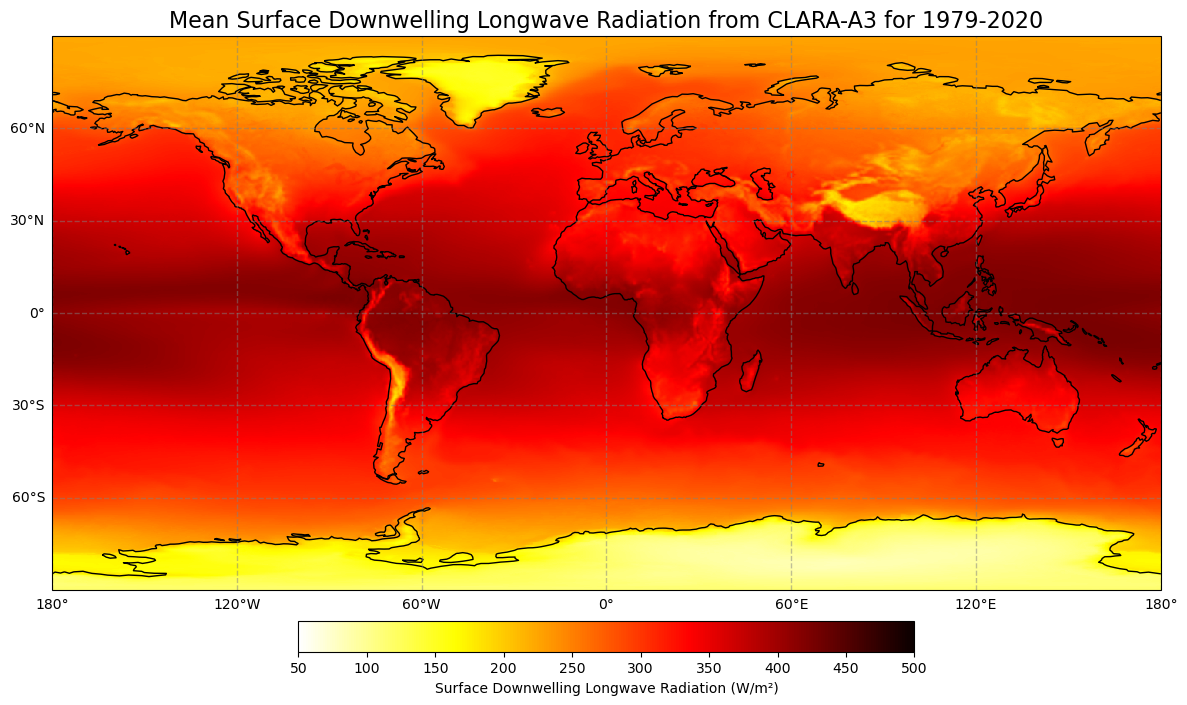
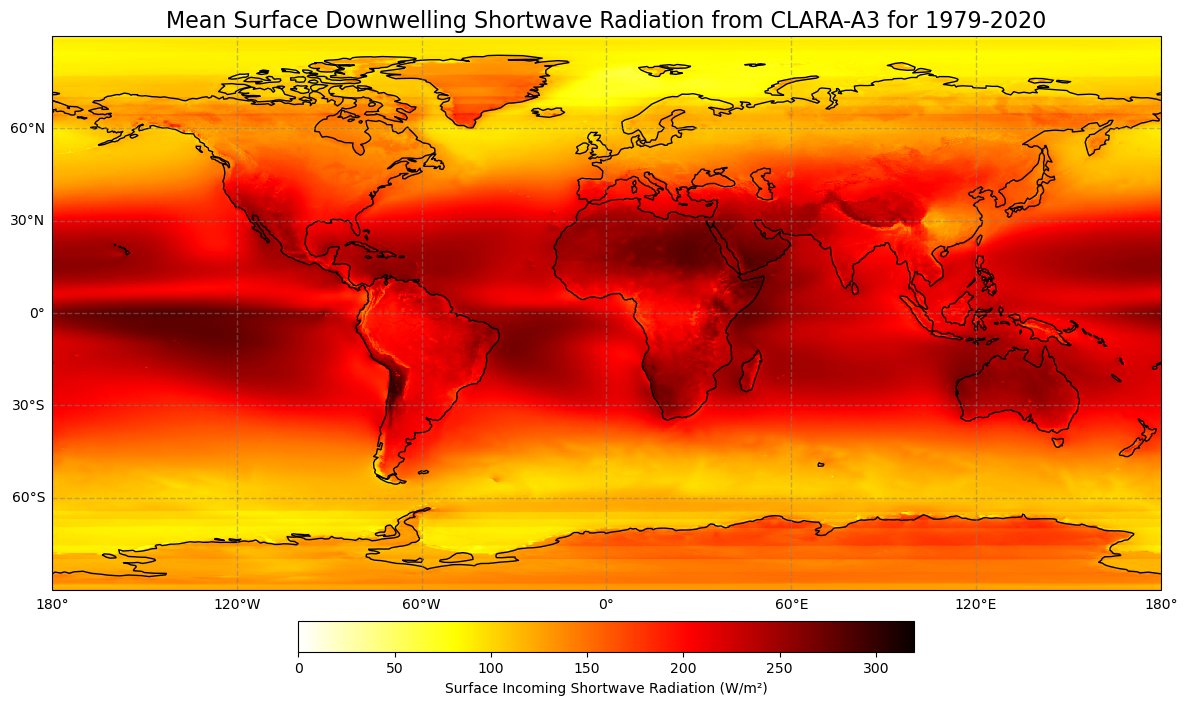
Figure 6: Global climatology of surface downwelling longwave (top) and surface incoming shortwave radiation (bottom) from 1979 - 2020 based on EUMETSAT’S CM SAF CLARA-A3 dataset.
Figure 6 shows the mean incoming long- and shortwave radiation at the Earth’s surface. It can nicely be linked to the mean fractional cloud cover in Figure 4, especially in regions where solar insolation is particulary high, mainly near the equator. As clouds reflect great parts of solar (shortwave) radiation, regions with low values of shortwave radiation at the surface correspond to regions with high fractional cloud cover in the mean. Clouds act as kind of mirrors, preventing solar radiation from reaching the Earth’s surface.
At the same time, clouds also prevent terrestrial (longwave) radiation, i.e. heat, from passing back into space. Thus, many spots of high cloud coverage correspond to high values of incomming longwave radiation, and vice versa. Clouds act like a blanket, trapping some of the energy the Earth emits. That is why starry nights usually become colder than cloudy ones.
Hence, clouds play a dual role for the Earth’s energy budget: They have both a cooling and a warming radiative impact. Their net effect strongly depends on the cloud’s physical properties and their height. Usually, high clouds tend to have a net warming effect on the earth, whereas mid- and low-level clouds rather cool it. Globally and annually, the shortwave effect of clouds overweights the longwave one, by abouth 20 W/m² at present (5th IPCC assessment report, chapter 7.2.1).
References#
5th IPCC assessment report, chapter 7:
Boucher, O., D. Randall, P. Artaxo, C. Bretherton, G. Feingold, P. Forster, V.-M. Kerminen, Y. Kondo, H. Liao, U. Lohmann, P. Rasch, S.K. Satheesh, S. Sherwood, B. Stevens and X.Y. Zhang, 2013: Clouds and Aerosols. In: Climate Change 2013: The Physical Science Basis. Contribution of Working Group I to the Fifth Assessment Report of the Intergovernmental Panel on Climate Change [Stocker, T.F., D. Qin, G.-K. Plattner, M. Tignor, S.K. Allen, J. Boschung, A. Nauels, Y. Xia, V. Bex and P.M. Midgley (eds.)]. Cambridge University Press, Cambridge, United Kingdom and New York, NY, USA