

Exploring Total Column Water Vapour information in the COMBI dataset#
This notebook-tutorial provides an introduction to the use of the combined global near-infrared (NIR) and microwave (MW) imager total column water vapour (TCWV) data record (COMBI) for climate studies.
The Water Vapour (WV) Essential Climate Variable (ECV) and the COMBI TCWV product are described in introduction. Then, a first use case provides an analysis of the time averaged global and seasonal climatological distributions of the total column water vapour as well as the monthly mean climatology. The second use case presents the time series and trend analysis of TCWV. Step-by-step instructions are provided on data preparation; the use cases are extensively documented and each line of code is explained.
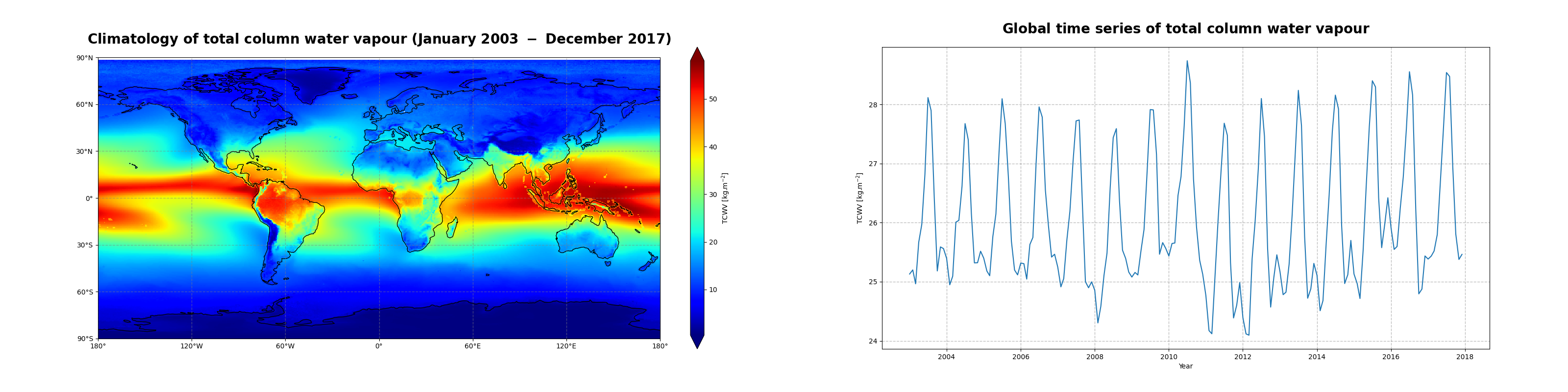
The two figures below show some results from both of the use cases and illustrate the successful run of the code.
This tutorial is in the form of a Jupyter notebook, written in Python 3.9.4. You will not need to install any software for the training as there are a number of free cloud-based services to create, edit, run and export Jupyter notebooks such as this. Here are some suggestions (simply click on one of the links below to run the notebook):
| Run the tutorial via free cloud platforms: |
|
|
|---|
Introduction#
Anthropogenic activities and natural variations from years to decades shape the Earth’s climate. Water vapour has been recognised as an Essential Climate Variable (ECV) as it provides the basis for all cloud formation, cloud physics, and furthermore influences the Earth’s heat budget due to its high absorbance of long and short-wave radiation. It is a natural greenhouse gas with a global warming potential much higher than carbon dioxide. An increase in temperature will lead to an increase in water vapour and due to this coupling mechanism to the acceleration of global warming. Total column water vapour (TCWV) is a measure of the integrated water vapour content of the atmosphere.
In the Copernicus Climate Data Store (CDS), the EUMETSAT Satellite Application Facility on Climate Monitoring has brokered the COMBI product. It combines the Special Sensor Microwave - Imager/Sensor (SSMI/S) TCWV retrievals in the microwave (MW) spectrum over ocean surfaces with the Medium Resolution Imaging Spectrometer (MERIS) retrievals, the Moderate-resolution Imaging Spectro-radiometer (MODIS) retrievals and the Ocean and Land Colour Imager (OLCI) retrievals in the near-infrared (NIR) domain over land surfaces. The COMBI product also covers sea-ice and coastal regions, but with a reduced quality. The TCWV dataset covers the time period July 2002 to December 2017.
In this Jupyter notebook tutorial, we present examples, based on monthly mean TCWV products, to illustrate the philosophy on the usage, visualisation, and analysis of the TCWV dataset. First you get to sort out data access and retrieval, and get all the right libraries in place for the computations. Then we take you through a short process of inspecting the retrieved data to see if it’s all ok for analysis. You then have a chance to visualise your data, before we take you through some climatology analyses that you could use in your work.
Dataset description#
You will find further information about the dataset in the Climate Data Store catalogue entry total column water vapour (see link to the entry below), sections “Overview”, “Download data” and “Documentation”:
The “Overview” section provides you with a general introduction to water vapour and its role in the atmosphere. In addition, the available datasets are described by an overview text and a table containing information about the coverage, resolution, etc.
The “Download data” section provides you with the download form and access to the data.
In the “Documentation” you will find useful documents like the Product User Guide and Specification (PUGS) with general information on TCWV, the Validation Report, or the Algorithm Theoretical Basis Document (ATBD) that describes the retrieval algorithms.
Search, download and view data#
Before we begin we must prepare our environment. This includes installing the Application Programming Interface (API) of the Climate Data Store (CDS), setting up our CDS API credentials and importing the various Python libraries that we will need.
# Ensure that the cdsapi package is installed
!pip install -q cdsapi
Import libraries#
The data have been stored in files written in NetCDF format. To best handle these, we will import the library Xarray which is specifically designed for manipulating multidimensional arrays in the field of geosciences. The libraries Matplotlib and Cartopy will also be imported for plotting and visualising the analysed data. We will also import the libraries zipfile to work with zip-archives, OS to use OS-functions and pattern expansion, and urllib3 for disabling warnings for data download via CDS API.
%matplotlib inline
# Libraries to work with zip-archives, OS functions and pattern expansion
import zipfile
import os
# Disable warnings for data download via API
import urllib3
urllib3.disable_warnings()
# CDS API library
import cdsapi
# Libraries for working with multidimensional arrays
import xarray as xr
import numpy as np
import pandas as pd
# Import a sublibrary method for the seasonal decomposition of the time series
from statsmodels.tsa.seasonal import seasonal_decompose
# Libraries for plotting and visualising the data
import matplotlib.pyplot as plt
import cartopy.crs as ccrs
from cartopy.mpl.ticker import (LongitudeFormatter, LatitudeFormatter)
Download Data Using CDS API#
Set up CDS API credentials#
To set up your CDS API credentials, please login/register on the CDS, then follow the instructions here to obtain your API key.
You can add this API key to your current session by uncommenting the code below and replacing ######### with your API key.
URL = 'https://cds.climate.copernicus.eu/api'
KEY = '######################################'
Here we specify a data directory in which we will download our data and all output files that we will generate:
DATADIR = './'
# Filename for the zip file downloaded from the CDS
download_zip_file = os.path.join(DATADIR, 'combi-tcwv-monthly.zip')
Search for data#
To search for data, we will visit the CDS website: https://cds.climate.copernicus.eu/cdsapp#!/home. Here we can search for COMBI data using the search bar. The data we need for this use case is the Global monthly and daily high-spatial resolution of total column water vapour from 2002 to 2017 derived from satellite observations. This catalogue entry provides data from various sources: C3S MERIS & SSMI product and Near-infrared & HOAPS combined product.
After selecting the correct catalogue entry, we will specify the product family, the horizontal aggregation, the vertical aggregation and the temporal coverage we are interested in. These can all be selected in the “Download data” tab. In this tab a form appears in which we will select the following parameters to download:
Product:
Near-infrared & HOAPS combinedHorizontal aggregation:
0.5Temporal aggregation:
MonthlyYear:
all(use “Select all” button)Month:
all(use “Select all” button)Format:
Compressed zip file (.zip)
If you have not already done so, you will need to accept the “terms & conditions” of the data before you can download it.
At the end of the download form, select “Show API request”. This will reveal a block of code, which you can simply copy and paste into a cell of your Jupyter Notebook (see cell below) …
Download data#
… Having copied the API request into the cell below, running this will retrieve and download the data we requested into our local directory. However, before we run the cell below, the terms and conditions of this particular dataset need to have been accepted in the CDS. The option to view and accept these conditions is given at the end of the download form, just above the “Show API request” option.
c = cdsapi.Client(url=URL, key=KEY)
c.retrieve(
'satellite-total-column-water-vapour-land-ocean',
{
'variable': 'all',
'format': 'zip',
'product': 'near_infrared_hoaps_combined',
'horizontal_aggregation': '0_5_x_0_5',
'temporal_aggregation': 'monthly',
'year': ['%04d' % (year) for year in range(2002, 2018)],
'month': ['%02d' % (month) for month in range(1, 13)],
'variable': 'all',
},
download_zip_file
)
2024-11-22 08:24:03,270 WARNING [2024-11-22T08:24:03.281457] You are using a deprecated API endpoint. If you are using cdsapi, please upgrade to the latest version.
2024-11-22 08:24:03,271 INFO Request ID is 1409a25c-689e-4cc4-a8f2-ffbd20fd5f25
2024-11-22 08:24:03,331 INFO status has been updated to accepted
2024-11-22 08:24:07,683 INFO status has been updated to successful
'./combi-tcwv-monthly.zip'
View data#
Inspect data#
The data have been downloaded. We can now unzip the archive and merge all files into one NetCDF file to inspect them. NetCDF is a commonly used format for array-oriented scientifc data. We use the Xarray library to read and process these data. Xarray is an open source project and Python package that makes working with labelled multi-dimensional arrays simple and efficient. We will read the data from our NetCDF file into an Xarray Dataset.
# Unzip the data. The dataset is split in monthly files.
with zipfile.ZipFile(download_zip_file, 'r') as zip_ref:
filelist = [os.path.join(DATADIR, f) for f in zip_ref.namelist()]
zip_ref.extractall(DATADIR)
# Ensure the filelist is in the correct order
filelist = sorted(filelist)
# Merge all unpacked files into one.
ds_combi = xr.open_mfdataset(filelist)
Now we can query our newly created Xarray…
ds_combi
<xarray.Dataset> Size: 1GB
Dimensions: (time: 186, nv: 2, lat: 360, lon: 720)
Coordinates:
* time (time) datetime64[ns] 1kB 2002-07-01 ... 2017-12-01
* lat (lat) float32 1kB 89.75 89.25 88.75 ... -89.25 -89.75
* lon (lon) float32 3kB -179.8 -179.2 -178.8 ... 179.2 179.8
Dimensions without coordinates: nv
Data variables:
record_status (time) int8 186B dask.array<chunksize=(1,), meta=np.ndarray>
time_bnds (time, nv) datetime64[ns] 3kB dask.array<chunksize=(1, 2), meta=np.ndarray>
lat_bnds (time, lat, nv) float32 536kB dask.array<chunksize=(1, 360, 2), meta=np.ndarray>
lon_bnds (time, lon, nv) float32 1MB dask.array<chunksize=(1, 720, 2), meta=np.ndarray>
surface_type_flag (time, lat, lon) int8 48MB dask.array<chunksize=(1, 360, 720), meta=np.ndarray>
num_days_tcwv (time, lat, lon) float64 386MB dask.array<chunksize=(1, 360, 720), meta=np.ndarray>
tcwv (time, lat, lon) float32 193MB dask.array<chunksize=(1, 360, 720), meta=np.ndarray>
num_obs (time, lat, lon) float32 193MB dask.array<chunksize=(1, 360, 720), meta=np.ndarray>
stdv (time, lat, lon) float32 193MB dask.array<chunksize=(1, 360, 720), meta=np.ndarray>
tcwv_err (time, lat, lon) float32 193MB dask.array<chunksize=(1, 360, 720), meta=np.ndarray>
tcwv_ran (time, lat, lon) float32 193MB dask.array<chunksize=(1, 360, 720), meta=np.ndarray>
crs (time) int32 744B 1178880137 1178880137 ... 1178880137
Attributes: (12/50)
title: Global Total Column of Water Vapour Product f...
institution: EUMETSAT/CMSAF
publisher_name: EUMETSAT/CMSAF
publisher_email: contact.cmsaf@dwd.de
publisher_url: http://www.cmsaf.eu/
source: Near-infrared Level 3 data (land, sea-ice and...
... ...
platform_vocabulary: GCMD Platforms, Version 8.6
instrument_vocabulary: GCMD Instruments, Version 8.6
variable_id: tcwv
platform: ENVISAT > Environmental Satellite,"AQUA > Ear...
sensor: MERIS > Medium Resolution Imaging Spectromete...
instrument: MERIS > Medium Resolution Imaging Spectromete...We see that the dataset has twelve variables among which “tcwv”, which stands for “total column water vapour”, and three dimension coordinates of lon, lat and time.
While an Xarray Dataset may contain multiple variables, an Xarray DataArray holds a single multi-dimensional variable and its coordinates. We convert the tcwv data into an Xarray DataArray to make the processing easier.
da_tcwv = ds_combi['tcwv']
Let us view these data:
da_tcwv
<xarray.DataArray 'tcwv' (time: 186, lat: 360, lon: 720)> Size: 193MB
dask.array<concatenate, shape=(186, 360, 720), dtype=float32, chunksize=(1, 360, 720), chunktype=numpy.ndarray>
Coordinates:
* time (time) datetime64[ns] 1kB 2002-07-01 2002-08-01 ... 2017-12-01
* lat (lat) float32 1kB 89.75 89.25 88.75 88.25 ... -88.75 -89.25 -89.75
* lon (lon) float32 3kB -179.8 -179.2 -178.8 -178.2 ... 178.8 179.2 179.8
Attributes:
long_name: Total Column of Water
units: kg/m2
standard_name: atmosphere_water_vapor_content
ancillary_variables: stdv num_obs
valid_range: [ 0. 70.]
actual_range: [ 0.7819019 68.77021 ]Plot data#
We can visualize one time step to figure out what the data look like. Xarray offers built-in matplotlib functions that allow us to plot a DataArray. With the function plot(), we can easily plot e.g. the first time step of the loaded array.
da_tcwv[0, :, :].plot()
<matplotlib.collections.QuadMesh at 0x316782450>
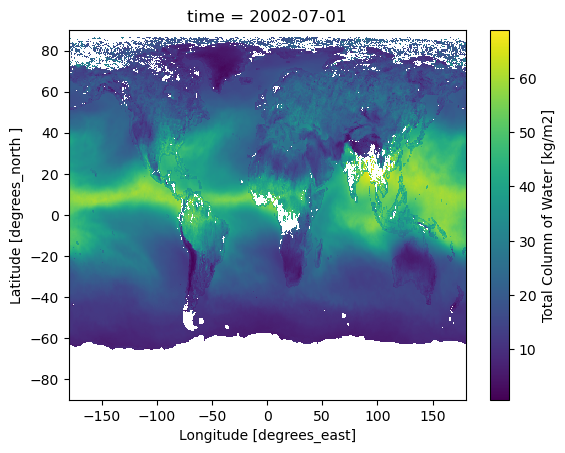
An alternative to the built-in Xarray plotting functions is to make use of a combination of the plotting libraries matplotlib and Cartopy. One of Cartopy’s key features is its ability to transform array data into different geographic projections. In combination with matplotlib, it is a very powerful way to create high-quality visualisations and animations. In later plots, we will make use of these libraries to produce more customised visualisations.
Climatology of the total column water vapour#
In this section we will analyse the time averaged global and seasonal climatological distributions of the total column water vapour as well as the monthly mean climatology.
Time averaged global climatological distribution of TCWV#
Let us calculate the mean climatology of total column water vapour for the time period January 2003 to December 2017.
First, to select the specific time range, we can use the Xarray method sel that indexes the data and dimensions by the appropriate indexers.
Then, we apply the method mean to calculate the mean along the time dimension.
# Select the tcwv data for the whole time period
tcwv = da_tcwv.sel(time=slice('2003-01-01', '2017-12-31'))
# Calculate the mean along the time dimension
tcwv_mean = tcwv.mean(dim='time')
We can now visualize the global mean climatological distribution of the total column water vapour for the period January 2003 - December 2017. This time, we will make use of a combination of the plotting libraries Matplotlib and Cartopy to create a more customised figure.
# Create the figure panel and the map using the Cartopy PlateCarree projection
fig1, ax1 = plt.subplots(1, 1, figsize=(16, 8), subplot_kw={'projection': ccrs.PlateCarree()})
# Plot the data
im = plt.pcolormesh(tcwv_mean.lon, tcwv_mean.lat, tcwv_mean, cmap='jet')
# Set the figure title, add lat/lon grid and coastlines
ax1.set_title(
'$\\bf{Climatology\ of\ TCWV\ (January\ 2003\ -\ December\ 2017)}$',
fontsize=20,
pad=20)
# Add coastlines
ax1.coastlines(color='black')
# Define gridlines and ticks
ax1.set_xticks(np.arange(-180, 181, 60), crs=ccrs.PlateCarree())
ax1.set_yticks(np.arange(-90, 91, 30), crs=ccrs.PlateCarree())
lon_formatter = LongitudeFormatter()
lat_formatter = LatitudeFormatter()
ax1.xaxis.set_major_formatter(lon_formatter)
ax1.yaxis.set_major_formatter(lat_formatter)
# Gridlines
gl = ax1.gridlines(linewidth=1, color='gray', alpha=0.5, linestyle='--')
# Specify the colorbar
cbar = plt.colorbar(im, fraction=0.025, pad=0.05, extend='both')
cbar.set_label('TCWV [kg.m$^{-2}$]')
# Save the figure
fig1.savefig(f'{DATADIR}combi_tcwv_climatology.png')
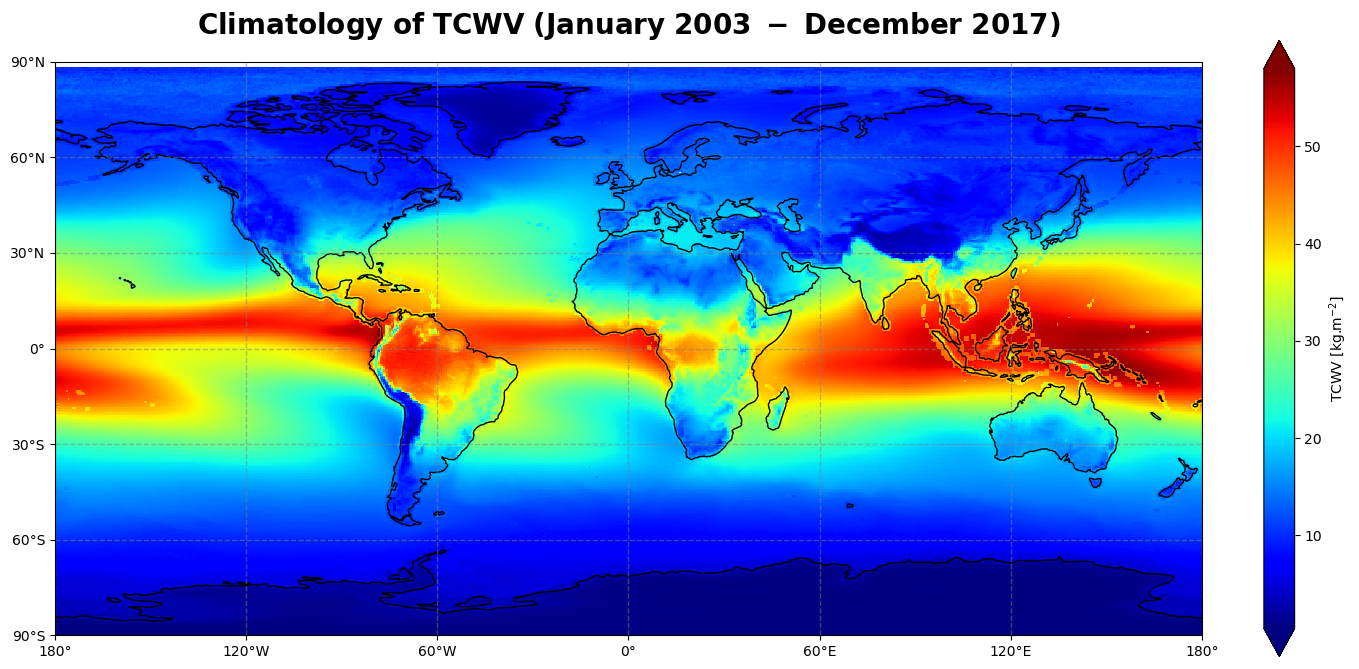
Figure 1 shows the global climatology of the total column water vapour for the time period of January 2003 - December 2017 over ocean and land, sea ice and coastal regions.
The total column water vapour has a dominant structure along the equator and over water masses where most of the evaporation takes place, i.e. mainly in the tropics. Solar irradiance and its relative position on the Earth’s surface (solar zenith angle) controls evaporation, leading to the transition of water from the liquid phase to the gaseous phase, which is subsequently advected to higher altitudes. This is the main driver of the Inter-Tropical Convergence Zone (ITCZ) along the equator, visible as a band of high amount of total column water vapour from the East Pacific to the West Pacific, over Central America and Brazil, the Atlantic Ocean, Africa and the Indian Ocean.
Time averaged seasonal climatological distribution of TCWV#
Now, let us have a look at the seasonal climatological distribution of total column water vapour.
First, we will use the groupby() method, with 'time.season' as an argument, to split the data according to the seasons; then we will average them over the years.
Seasons are defined as follows:
NH spring: March, April, May
NH summer: June, July, August
NH autumn: September, October, November
NH winter: December, January, February
# Split data array tcwv by season
tcwv_seasonal_climatology = tcwv.groupby('time.season').mean('time')
tcwv_seasonal_climatology
<xarray.DataArray 'tcwv' (season: 4, lat: 360, lon: 720)> Size: 4MB
dask.array<stack, shape=(4, 360, 720), dtype=float32, chunksize=(1, 360, 720), chunktype=numpy.ndarray>
Coordinates:
* lat (lat) float32 1kB 89.75 89.25 88.75 88.25 ... -88.75 -89.25 -89.75
* lon (lon) float32 3kB -179.8 -179.2 -178.8 -178.2 ... 178.8 179.2 179.8
* season (season) object 32B 'DJF' 'JJA' 'MAM' 'SON'
Attributes:
long_name: Total Column of Water
units: kg/m2
standard_name: atmosphere_water_vapor_content
ancillary_variables: stdv num_obs
valid_range: [ 0. 70.]
actual_range: [ 0.7819019 68.77021 ]The Xarray DataArray “tcwv_seasonal_climatology” has four entries in the time dimension (one for each season). The nan values correspond to the extreme latitudes (see lat coordinates) of the polar regions where no measurements have been made. The climatology of the total column water vapour distribution can now be plotted for each season.
# Create a list of the seasons such as defined in the dataset tcwv_seasonal_climatology:
seasons = ['MAM', 'JJA', 'SON', 'DJF']
# We use the "subplots" to place multiple plots according to our needs.
# In this case, we want 4 plots in a 2x2 format.
# For this "nrows" = 2 and "ncols" = 2, the projection and size are defined as well
fig2, ax2 = plt.subplots(nrows=2,
ncols=2,
subplot_kw={'projection': ccrs.PlateCarree()},
figsize=(16,8))
# Define a dictionary of subtitles, each one corresponding to a season
subtitles = {'MAM': 'NH spring', 'JJA': 'NH summer', 'SON': 'NH autumn', 'DJF': 'NH winter'}
# Configure the axes and subplot titles
for i_season, c_season in enumerate(seasons):
# convert i_season index into (row, col) index
row = i_season // 2
col = i_season % 2
# Plot data (coordinates and data) and define colormap
im = ax2[row][col].pcolormesh(tcwv_seasonal_climatology.lon,
tcwv_seasonal_climatology.lat,
tcwv_seasonal_climatology.sel(season=c_season),
cmap='jet')
# Set title and size
ax2[row][col].set_title('Seasonal climatology of TCWV - ' + subtitles[c_season],
fontsize=16)
# Add coastlines
ax2[row][col].coastlines()
# Define grid lines and ticks (e.g. from -180 to 180 in an interval of 60)
ax2[row][col].set_xticks(np.arange(-180, 181, 60), crs=ccrs.PlateCarree())
ax2[row][col].set_yticks(np.arange(-90, 91, 30), crs=ccrs.PlateCarree())
lon_formatter = LongitudeFormatter()
lat_formatter = LatitudeFormatter()
ax2[row][col].xaxis.set_major_formatter(lon_formatter)
ax2[row][col].yaxis.set_major_formatter(lat_formatter)
# Gridline
gl = ax2[row][col].gridlines(linewidth=1, color='gray', alpha=0.5, linestyle='--')
# Place the subplots
fig2.subplots_adjust(bottom=0.0, top=0.9, left=0.05, right=0.95, wspace=0.1, hspace=0.5)
# Define and place a colorbar at the bottom
cbar_ax = fig2.add_axes([0.2, -0.1, 0.6, 0.02])
cbar = fig2.colorbar(im, cax=cbar_ax, orientation='horizontal', extend='both')
cbar.set_label('TCWV [kg.m$^{-2}$]',
fontsize=16)
# Define an overall title
fig2.suptitle('$\\bf{Seasonal\ climatology\ of\ TCWV\ (January\ 2003\ -\ December\ 2017)}$',
fontsize=20)
# Save the figure
fig2.savefig(f'{DATADIR}combi_tcwv_seasonal_climatology.png')
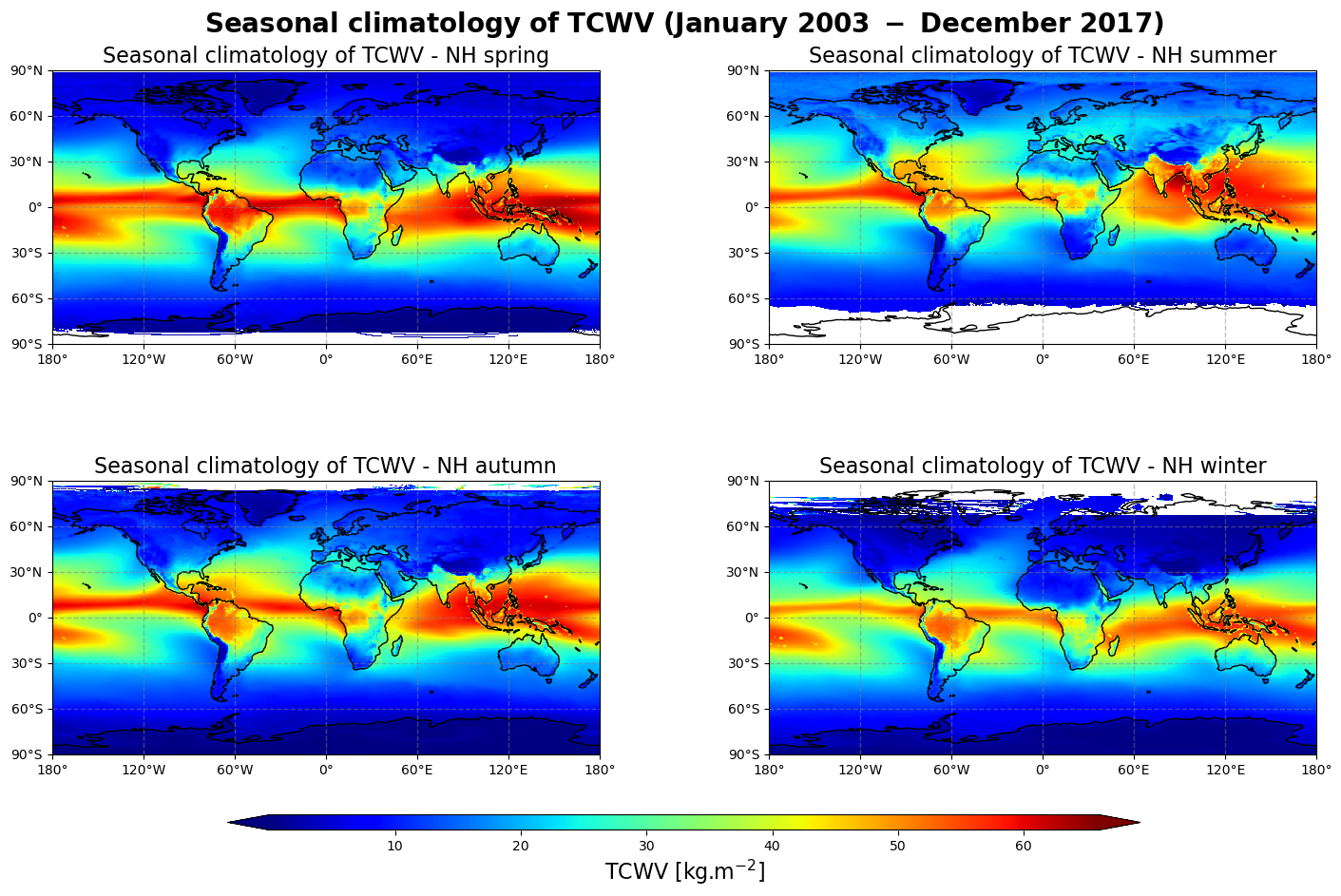
Figure 2 shows the seasonal mean climatology of the total column water vapour from Northern Hemisphere spring to winter (top left to bottom right panels) derived from the combined measurements of MERIS, MODIS, OLCI and SSMI/S.
The general pattern is overall the same as in Figure 1 with higher values in the tropics and lower values in the extra tropics. The band of high amount of TCWV (particularly noticeable between South-East Asia and North Australia) oscillates around the equator, reaching its highest values in the Summer Hemisphere. It confirms the dominant influence of the solar radiation over the course of the inter-tropical convergence zone.
Zonally averaged monthly mean climatology of TCWV#
Let us now calculate the zonally averaged monthly mean climatology of the total column water vapour over the time period January 2003 - December 2017, and visualise it in the form of a Hovmöller diagram.
A Hovmöller diagram is a common way of plotting meteorological or climatological data (such as the zonally averaged monthly mean TCWV) to depict their changes over time as a function of latitude or longitude. In our case, time will be recorded along the abscissa and latitude along the ordinate.
First, we will apply the groupby() method to group the “tcwv” DataArray by month, and then we will compute the average for each monthly group and longitude band.
The resulting data array is the zonally averaged monthly mean climatology for the total column water vapour based on reference January 2002 - December 2017.
# Compute the average for each monthly group
tcwv_clim_month = tcwv.groupby('time.month').mean("time")
tcwv_clim_month
<xarray.DataArray 'tcwv' (month: 12, lat: 360, lon: 720)> Size: 12MB
dask.array<stack, shape=(12, 360, 720), dtype=float32, chunksize=(1, 360, 720), chunktype=numpy.ndarray>
Coordinates:
* lat (lat) float32 1kB 89.75 89.25 88.75 88.25 ... -88.75 -89.25 -89.75
* lon (lon) float32 3kB -179.8 -179.2 -178.8 -178.2 ... 178.8 179.2 179.8
* month (month) int64 96B 1 2 3 4 5 6 7 8 9 10 11 12
Attributes:
long_name: Total Column of Water
units: kg/m2
standard_name: atmosphere_water_vapor_content
ancillary_variables: stdv num_obs
valid_range: [ 0. 70.]
actual_range: [ 0.7819019 68.77021 ]Let us view the zonal monthly climatology of the TCWV. To do this, we will average across the longitude bands with the mean() method, align the time dimension coordinate with the x axis and the lat dimension coordinate along the y axis using the method transpose()…
tcwv_zonal_clim_month = tcwv_clim_month.mean(dim="lon").transpose()
tcwv_zonal_clim_month
<xarray.DataArray 'tcwv' (lat: 360, month: 12)> Size: 17kB dask.array<transpose, shape=(360, 12), dtype=float32, chunksize=(360, 1), chunktype=numpy.ndarray> Coordinates: * lat (lat) float32 1kB 89.75 89.25 88.75 88.25 ... -88.75 -89.25 -89.75 * month (month) int64 96B 1 2 3 4 5 6 7 8 9 10 11 12
Now we can plot our data. Before we do this however, we define the min, max and step of contours that we will use in a contour plot.
vdiv = 1
vmin = 0
vmax = 50
clevs = np.arange(vmin, vmax, vdiv)
# Define the figure and specify size
fig3, ax3 = plt.subplots(1, 1, figsize=(16, 8))
# Configure the axes and figure title
ax3.set_xlabel('Month')
ax3.set_ylabel('Latitude [ $^o$ ]')
ax3.set_yticks(np.arange(-90, 91, 30))
ax3.set_title(
'$\\bf{Zonally\ averaged\ monthly\ climatology\ of\ TCWV\ (January\ 2003\ -\ December\ 2017)}$',
fontsize=20,
pad=20)
# As the months (12) are much less than the latitudes (180),
# we need to ensure the plot fits into the size of the figure.
ax3.set_aspect('auto')
# Plot the data as a contour plot
contour = ax3.contourf(tcwv_zonal_clim_month.month,
tcwv_zonal_clim_month.lat,
tcwv_zonal_clim_month,
levels=clevs,
cmap='jet',
extend='both')
# Specify the colorbar
cbar = plt.colorbar(contour, fraction=0.025, pad=0.05)
cbar.set_label(['TCWV [kg.m$^{-2}$]'])
# Save the figure
fig3.savefig(f'{DATADIR}combi_tcwv_monthly_climatology.png')
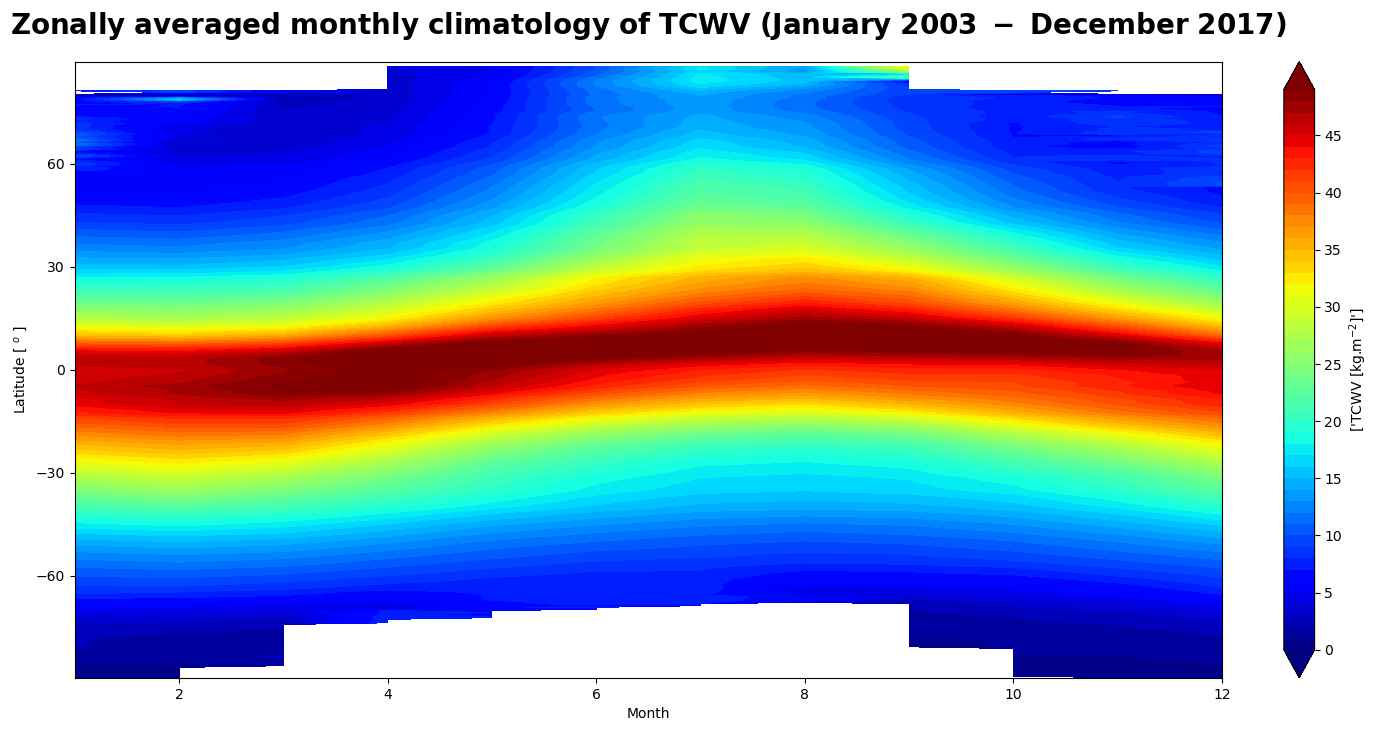
Figure 3 shows the seasonal motion of the water vapour band crossing the equator from boreal summer (July) to austral summer (December) associated with the Inter-Tropical Convergence Zone.
In the next use case, we will anlyse the temporal evolution of the total column water vapour and its annual seasonal variation.
Time series and trend analysis of the total column water vapour#
After looking at the time averaged global distribution of the total column water vapour, we further investigate the dataset. The COMBI product spans over 15 years of satellite observations, and another useful way of analysing and visualizing the temporal evolution of total column water vapour is using the time series. We will calculate the global time series, plot it, and discuss most important features.
Global time series of TCWV#
We first create a temporal subset for the period January 2003 to December 2017.
# Select time period
tcwv_combi = da_tcwv.sel(time=slice('2003-01-01', '2017-12-31'))
tcwv_combi
<xarray.DataArray 'tcwv' (time: 180, lat: 360, lon: 720)> Size: 187MB
dask.array<getitem, shape=(180, 360, 720), dtype=float32, chunksize=(1, 360, 720), chunktype=numpy.ndarray>
Coordinates:
* time (time) datetime64[ns] 1kB 2003-01-01 2003-02-01 ... 2017-12-01
* lat (lat) float32 1kB 89.75 89.25 88.75 88.25 ... -88.75 -89.25 -89.75
* lon (lon) float32 3kB -179.8 -179.2 -178.8 -178.2 ... 178.8 179.2 179.8
Attributes:
long_name: Total Column of Water
units: kg/m2
standard_name: atmosphere_water_vapor_content
ancillary_variables: stdv num_obs
valid_range: [ 0. 70.]
actual_range: [ 0.7819019 68.77021 ]Spatial aggregation#
We would like to visualise these data, not in maps but as one dimensional time series of global average values. To do this, we will first need to aggregate the data spatially to create a single global average at each time step. In order to aggregate over the latitudinal dimension, we need to take into account the variation in area as a function of latitude. We will do this by using the cosine of the latitude as a proxy:
weights = np.cos(np.deg2rad(tcwv_combi.lat))
weights.name = "weights"
tcwv_combi_weighted = tcwv_combi.weighted(weights)
The next step is to compute the mean across the latitude and longitude dimensions of the weighted data array with the mean() method.
tcwv_weighted_mean = tcwv_combi_weighted.mean(dim=("lat", "lon"))
Plot data#
Now we can plot the time series of globally averaged TCWV data over time using the plot() method.
# Define the figure and specify size
fig4, ax4 = plt.subplots(1, 1, figsize=(16, 8))
# Configure the axes and figure title
ax4.set_xlabel('Year')
ax4.set_ylabel('TCWV [kg.m$^{-2}$]')
ax4.grid(linewidth=1, color='gray', alpha=0.5, linestyle='--')
ax4.set_title('$\\bf{Global\ time\ series\ of\ total\ column\ water\ vapour}$',
fontsize=20,
pad=20)
# Plot the data
ax4.plot(tcwv_weighted_mean.time, tcwv_weighted_mean)
# Save the figure
fig4.savefig(f'{DATADIR}combi_tcwv_global_timeseries.png')
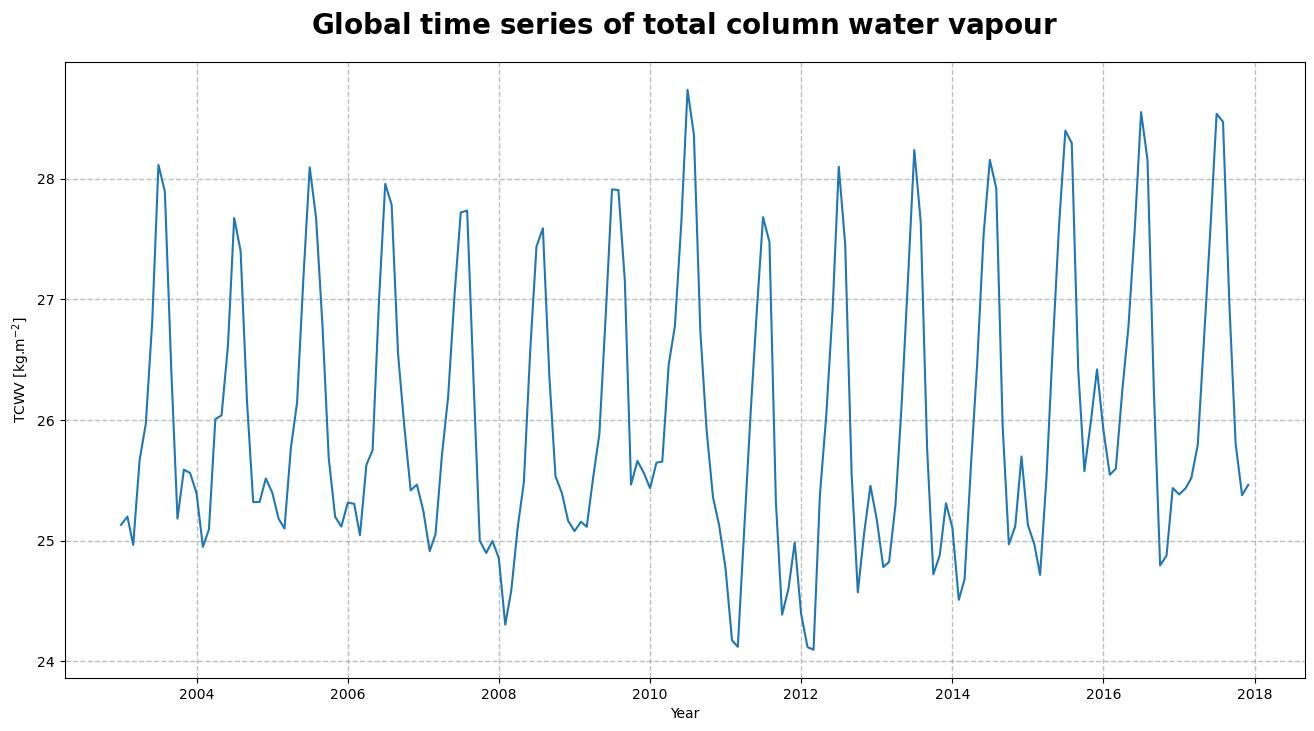
Figure 4, shows the time series of the monthly mean total column water vapour. From the time series, we can infer the seasonal pattern along with a trend in the global space and time averaged TCWV.
We can now calculate the monthly climatology of the total column water vapour for the period January 2003 to December 2017 to study more specifically the amplitude and the evolution of the seasonal cycle over the years.
Monthly climatology of TCWV#
Let us now study the monthly climatology of the total column water vapour over the time period covered by the COMBI product.
It corresponds to the mean and the associated standard deviation of the global time series of TCWV and is calculated for each month over the years 2003-2017.
First, we will apply the groupby() method to the Xarray DataArray “tcwv_weighted_mean” which we have defined in the previous section. Then, we will compute the mean and the associated standard deviation by using the mean() and std() methods respectively.
# Monthly climatology
# Compute the global monthly mean climatology of tcwv
tcwv_clim_month_mean = tcwv_weighted_mean.groupby('time.month').mean()
# Compute the associated standard deviation
tcwv_clim_month_std = tcwv_weighted_mean.groupby('time.month').std()
To have a first idea of the evolution of TCWV over the years, we can also create an Xarray DataArray with year and month as dimension coordinates. This will help us to identify which year was the “driest” (i.e. with the lowest seasonal envelope) and which one was the “wettest” (i.e. with the highest seasonal envelope).
# Creation of a new Xarray Data Array to determine the "driest" and "wettest" years
# Creation of a n_years x n_months climatological array
tcwv_clim = tcwv_weighted_mean.data.reshape(-1, 12)
# Initialization of the corresponding Xarray Data Array
year = ['%04d' % (year) for year in range(2003, 2018)]
month = ['%02d' % (month) for month in range(1, 13)]
da_tcwv_clim = xr.DataArray(data=tcwv_clim,
dims=["year", "month"],
coords=dict(year=year,
month=month),
name='tcwv_clim')
# Determine the years with highest and lowest seasonal values of TCWV
# Year of minimum TCWV values in average
tcwv_clim_min = da_tcwv_clim.mean(dim='month').min()
year_tcwv_clim_min = da_tcwv_clim.mean(dim='month').data.argmin()
year_min_tcwv = year[year_tcwv_clim_min]
# Year of maximum TCWV values in average
tcwv_clim_max = da_tcwv_clim.mean(dim='month').max()
year_tcwv_clim_max = da_tcwv_clim.mean(dim='month').data.argmax()
year_max_tcwv = year[year_tcwv_clim_max]
# Compute (and show) the mean difference between the "wettest" and "driest" year in average
peak_to_peak_tcwv_clim = tcwv_clim_max - tcwv_clim_min
peak_to_peak_tcwv_clim.data
|
||||||||||||||||
We will now plot the global monthly climatology over the years.
# Define the figure and specify size
fig5, ax5 = plt.subplots(1, 1, figsize=(16, 8))
# Plot the data
ax5.plot(tcwv_clim_month_mean.month, tcwv_clim_month_mean, color='blue', linewidth=3, label='mean')
ax5.fill_between(tcwv_clim_month_mean.month,
(tcwv_clim_month_mean - tcwv_clim_month_std),
(tcwv_clim_month_mean + tcwv_clim_month_std),
alpha=0.1,
color='green',
label='+/- 1 SD')
for year in [year_min_tcwv, year_max_tcwv]:
ax5.plot(tcwv_clim_month_mean.month,
da_tcwv_clim.sel(year=year),
label=year)
# Configure the axes and figure title
ax5.set_title('$\\bf{Global\ Monthly\ climatology\ of\ total\ column\ water\ vapour}$',
fontsize=20,
pad=20)
ax5.set_ylabel('TCWV [kg.m$^{-2}$]')
ax5.set_xlabel('Month')
handles, labels = ax5.get_legend_handles_labels()
ax5.legend(handles, labels)
ax5.grid(linewidth=1, color='gray', alpha=0.5, linestyle='--')
# Save the figure
fig5.savefig(f'{DATADIR}combi_tcwv_global_monthly_climatology.png')
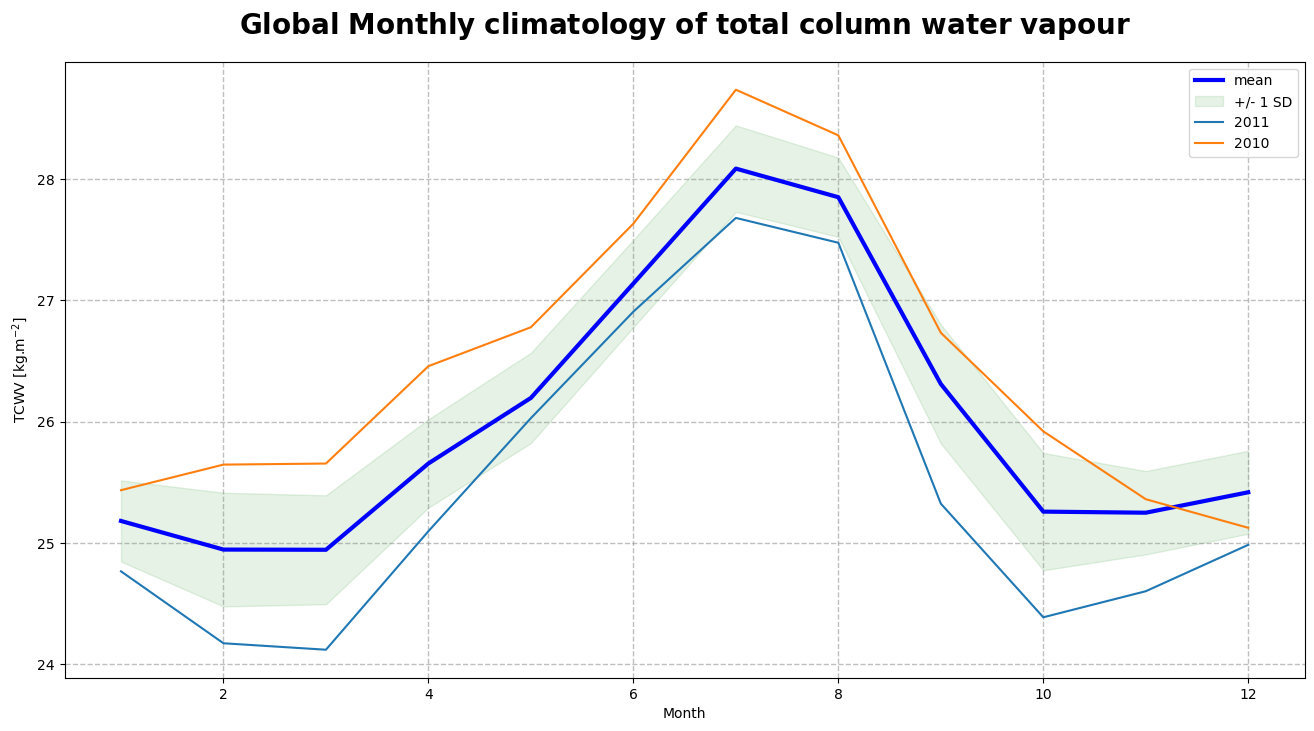
Figure 5 shows the monthly climatology of the total column water vapour represented by the mean and standard deviation (or spread) over the time period January 2003 - December 2017.
We observe a seasonal variation of TCWV with an amplitude of 3 kg/m\(^{2}\), reaching its highest values around July-August and its lowest values around December-January. The mean difference of 1.025 kg/m\(^{2}\) between the highest seasonal envelope corresponding to the year 2010 and the lowest seasonal envelope corresponding to the year 2011 is related to the 2010-2012 “La Niña” event, one of the strongest on record. We will now procede to the seasonal decomposition of the total column water vapour to study this trend in more details.
Trend analysis and seasonal cycle of TCWV#
The time series can be further analysed by extracting the trend, or the running annual mean, and the seasonal cycle.
To this end, we will convert the Xarray DataArray into a time series with the pandas library. Then we will decompose it into the trend, the seasonal cycle and the residuals by using the seasonal_decompose() method. Finally we will visualize the results.
# Convert the Xarray data array tcwv_weighted_mean into a time series
tcwv_weighted_mean_series = pd.Series(tcwv_weighted_mean)
# Define the time dimension of tcwv_weighted_mean as the index of the time series
tcwv_weighted_mean_series.index = tcwv_weighted_mean.time.to_dataframe().index
# Decomposition of the time series into the trend, the seasonal cycle and the residuals
tcwv_seasonal_decomposition = seasonal_decompose(tcwv_weighted_mean_series,
model='additive',
period=12)
# Plot the resulting seasonal decomposition
tcwv_seasonal_decomposition.plot()
plt.xlabel("Time")
plt.savefig(f'{DATADIR}combi_tcwv_timeseries_climatology.png')
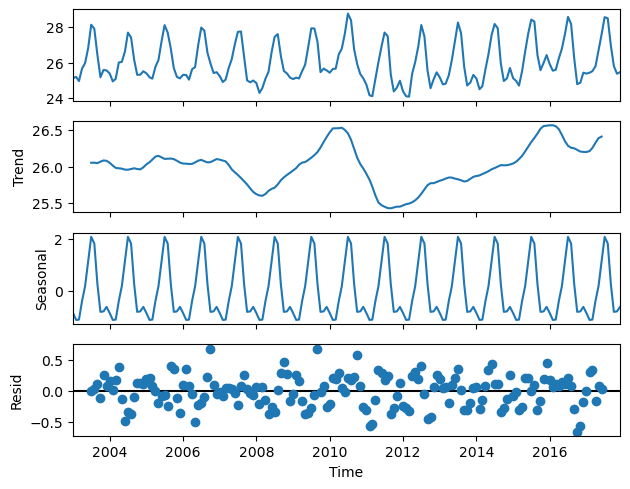
Figure 6 shows the decomposition of the TCWV time series into the trend (2nd panel) and the seasonal cycle with a confirmed amplitude of 3 kg/m\(^{2}\) (3rd panel). From the trend and the seasonal cycle, we can derive the anomalies or de-trended and de-seasonalised time series that have the characteristics of uncorrelated noise pattern (4th panel).
The anomaly index can be attributed to some exceptional time periods and can be used to calculate the autocorrelation for a given time lag, in order to derive the “memory effect” and its length, in the global water vapour system. The trend analysis presents two extremes (a maximum followed by a minimum) around the years 2010 and 2011/12, that are related to a moderate “El Niño” event followed by one of strongest “La Niña” events on record. The maximum of 2016 is associated to a strong “El Niño” event. The combination of strong “El Niño” events and higher overall trends might lead to extreme values in the total column water vapour in the future.
Conclusion#
In this notebook we have provided some use cases based on the COMBI TCWV data record to illustrate the way this dataset can be used to study, analyse and visualise this essential climate variable. The current dataset indicates a slight increase of total column water vapour between January 2003 and December 2017. Comparisons with other independent datasets can be made to further investigate the trends that can be attributed to global climate change, El-Niño events, etc.
Appendix#
Clean up your directory of the netCDF files you unzipped.
You can set the save_merged_netcdf flag to True (and choose a filename)
if you want to merge the data into a single netcdf before closing
# Flag to save the merged netCDF file
save_merged_netcdf = False
# Filename for the netCDF file which contains the merged contents of the monthly files.
merged_netcdf_file = os.path.join(DATADIR, 'combi-tcwv-monthly.nc')
if save_merged_netcdf:
ds_combi.to_netcdf(merged_netcdf_file)
# Recursively delete unpacked data
for f in filelist:
os.remove(f)