

5.1.10. Testing the capability of CMIP6 GCMs to represent precipitation inter-annual variability#
Production date: 19-01-2025
Produced by: CMCC foundation - Euro-Mediterranean Center on Climate Change. Albert Martinez Boti.
🌍 Use case: Assessing the potential impacts of climate change on precipitation inter-annual variability over India for water management#
❓ Quality assessment question#
How well do CMIP6 projections represent historic inter-annual variability of precipitation across the Indian sub-continent? Are there trends affecting precipitation inter-annual variability?
Most research has focused on projected long-term changes in mean climate and extremes, while changes in variability have received less attention. However, understanding the evolution of precipitation variability is crucial for accurately modelling climate phenomena and quantify climate change impacts, particularly on water resources and related socioeconomic factors [1],[2]. This notebook evaluates the capability of a subset of 16 CMIP6 Global Climate Models (GCMs) to represent inter-annual variability in seasonal mean precipitation over the Indian subcontinent, employing variance and the coefficient of variation (standard deviation divided by the mean) as measures of variability.
Systematic errors are assessed by comparing model outputs against the ERA5 reanalysis, which serves as the reference dataset. The analysis focuses on JJAS (June, July, August and September), traditionally regarded as the Indian Summer Monsoon period, though the methodology is adaptable for annual or other seasonal analyses. Spatial patterns of the variance and the coefficient of variation are examined for JJAS mean precipitation over the historical period from 1940 to 2014. Additionally, the temporal evolution of the spatially-averaged variance and coefficient of variation, including trends, is analysed using a 30-year moving window and presented as time series.
The analyses presented in this notebook provide valuable insights into the reliability of a subset of CMIP6 models in capturing precipitation inter-annual variability. Understanding the performance of these models can help the water management sector to make more informed decisions and supports the use of CMIP6 Global Climate Models (GCMs) in designing strategies to adapt to projected changes in variability.
📢 Quality assessment statement#
These are the key outcomes of this assessment
The choice of variability formulation is crucial when describing inter-annual variability during the summer Monsoon. The two formulations considered within this assessment reveal distinct spatial patterns.
Variance analyses reveal model-dependent differences in bias magnitude, sign, and spatial distribution. Despite these variations, all models show strong links to orography and high-precipitation regions, where biases remain significant due to high precipitation, even though they are not necessarily large relative to the mean. The coefficient of variation removes this effect by normalising the standard deviation (i.e., the square root of the variance) by the mean.
Model differences are less pronounced for the coefficient of variation than for variance. Most models underestimate it in the inland north-west, where seasonal mean precipitation is very low or near zero.
The 30-year time series of spatially averaged variance and coefficient of variation show a decreasing trend for ERA5, suggesting a decline in inter-annual variability over the historical period. This is evident from both variance magnitude—potentially influenced by the mean’s decline [3]—and the coefficient of variation, which removes the effect of the mean. However, the CMIP6 ensemble median for the subset of considered models shows the opposite trend.
Understanding and correcting the biases of CMIP6 projections of precipitation variability may increase confidence when analysing projections assessing the future inter-annual variability which can help on planning for water resource allocation, flood mitigation, and agricultural management, ensuring resilience against the challenges posed by a changing climate.
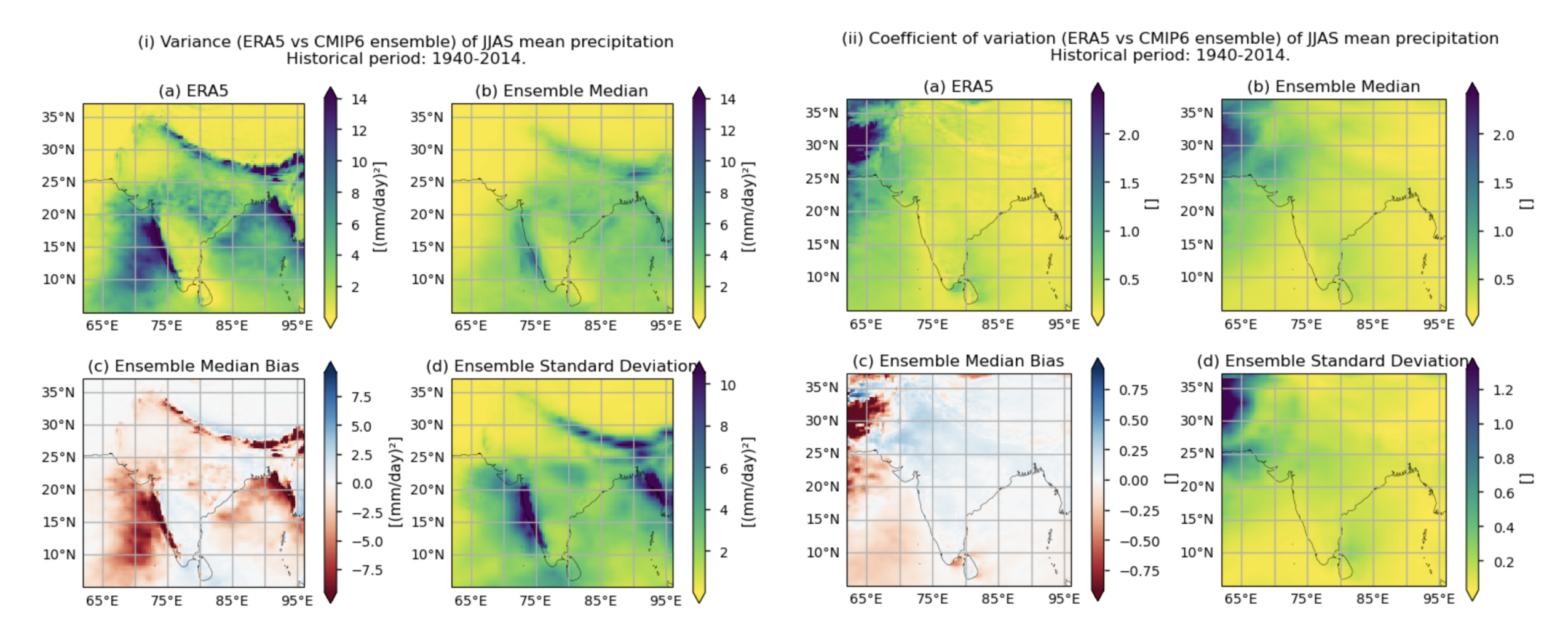
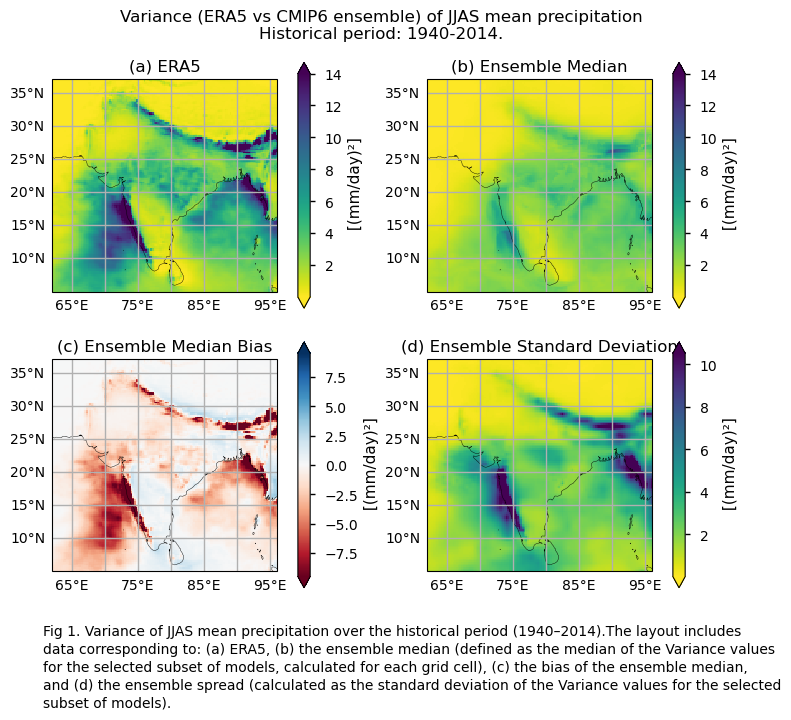
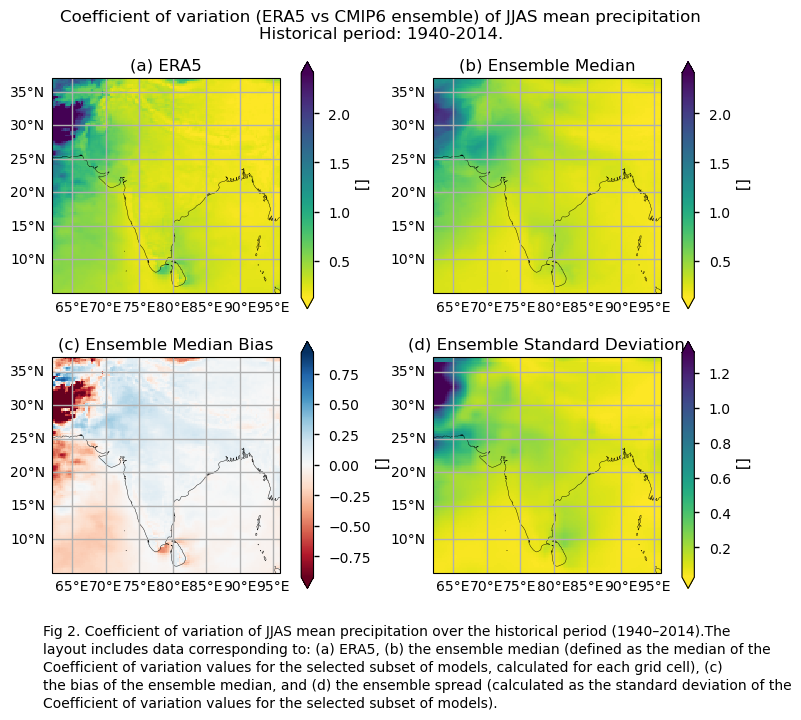
Fig. 5.1.10.1 Fig A. i. Variance of JJAS mean precipitation over the historical period (1940–2014). The layout includes data corresponding to: (a) ERA5, (b) the ensemble median (defined as the median of the variance values for the selected subset of models, calculated for each grid cell), (c) the bias of the ensemble median, and (d) the ensemble spread (calculated as the standard deviation of the variance values for the selected subset of models). Fig A.ii. Same as Fig. A.i. but for the coefficient of variation.#
📋 Methodology#
A subset of 16 models from the CMIP6 project is used to calculate the variance and the coefficient of variation (standard deviation divided by the mean), which serve as formulations to characterise precipitation inter-annual variability in this notebook. Spatial patterns of variance and the coefficient of variation for seasonal mean precipitation, along with their associated biases (using ERA5 as reference), are displayed for each model and the ensemble median (per grid cell). Additionally, the spatially averaged temporal evolution of the variance and coefficient of variation, including trends, is analysed using a 30-year moving window and presented as time series, following a methodology similar to [4].
The analysis focuses on the Indian subcontinent during the historical period from 1940 to 2014 and examines the JJAS period, traditionally regarded as the Indian Summer Monsoon (or rainy) season, although the methodology can be adapted for other seasonal or annual periods.
The analysis and results follow the next outline:
1. Parameters, requests and functions definition
📈 Analysis and results#
1. Parameters, requests and functions definition#
1.1. Import packages#
1.2. Define Parameters#
In the “Define Parameters” section, various customisable options for the notebook are specified:
The initial and ending year used for the historical period can be specified by changing the parameters
year_startandyear_stop(1940-2014 is chosen).The
timeseriesset the temporal period. For instance, selecting “JJAS” implies considering only the June, July, August, September season.areaallows specifying the geographical domain of interest. A domain including the Indian sub-continent has been selected.The
interpolation_methodparameter allows selecting the interpolation method when regridding is performed.The
chunkselection allows the user to define if dividing into chunks when downloading the data on their local machine. Although it does not significantly affect the analysis, it is recommended to keep the default value for optimal performance.variableandcollection_idare not customisable for this assessment and are set to ‘precipitation’ and ‘CMIP6’. Expert users can use this notebook as a guide to create similar analyses for other variables or model sets (such as CORDEX).
1.3. Define models#
The following climate analyses are performed considering a subset of GCMs from CMIP6.
The selected CMIP6 models have available both the historical and SSP5-8.5 experiments.
1.4. Define ERA5 request#
Within this notebook, ERA5 serves as the reference product. In this section, we set the required parameters for the cds-api data-request of ERA5.
1.5. Define model requests#
In this section we set the required parameters for the cds-api data-request.
1.6. Functions to cache#
In this section, functions that will be executed in the caching phase are defined. Caching is the process of storing copies of files in a temporary storage location, so that they can be accessed more quickly. This process also checks if the user has already downloaded a file, avoiding redundant downloads.
Functions description:
get_grid_outandadd_boundsensure the regrid is performed properly.The
select_timeseriesfunction subsets the dataset based on the chosentimeseriesparameter.The
compute_rolling_variancefunction calculates the rolling variance and coefficient of variation using a 30-year window (which are needed when displaying the time series afterwards). It also computes the variance and coefficient of variation for the entire period.The
compute_interannual_variancefunction selects the season using theselect_timeseriesfunction. It then computes the rolling variance (and coefficient of variation) over the historical period (1940–2014) by callingcompute_rolling_variance. The window width is 30 years, with a step size of one year. The variance and coefficient of variation is also calculated for the whole historical period.
2. Downloading and processing#
2.1. Download and transform ERA5#
In this section, the download.download_and_transform function from the ‘c3s_eqc_automatic_quality_control’ package is used to download ERA5 reference monthly data, select the season (e.g., “JJAS” in this case) and compute the variance and coefficient of variation for the entire historical period, as well as for a 30-year rolling window. The results are then cached to prevent redundant downloads and processing.
2.2. Download and transform models#
In this section, the download.download_and_transform function from the ‘c3s_eqc_automatic_quality_control’ package is employed to download daily data from the CMIP6 models, select the season (“JJAS” in this example), compute the variance and coefficient of variation for the entire historical period, as well as for a 30-year rolling windows, interpolate to the ERA5 grid (only when specified; otherwise, the original model grid is maintained), and cache the results to avoid redundant downloads and processing.
model='access_cm2'
model='bcc_csm2_mr'
model='cmcc_esm2'
model='cnrm_cm6_1_hr'
model='cnrm_esm2_1'
model='ec_earth3_cc'
model='gfdl_esm4'
model='inm_cm4_8'
model='inm_cm5_0'
model='mpi_esm1_2_lr'
model='miroc6'
model='miroc_es2l'
model='mri_esm2_0'
model='noresm2_mm'
model='nesm3'
model='ukesm1_0_ll'
2.3. Change some attributes#
3. Plot and describe results#
This section will display the following results:
Maps showing the spatial distribution of the variance of JJAS mean precipitation calculated for the whole historical period 1940-2014 comparing ERA5 and the ensemble median (defined as the median of the variance values for the selected subset of models, calculated for each grid cell). The layout include ERA5, the ensemble median, the ensemble median bias and the ensemble spread (derived as the standard deviation of the variance for the selected subset of models). The same exact layout of maps is displayed for the coefficient of variation.
Maps showing the spatial distribution of the variance of JJAS mean precipitation calculated for the whole historical period 1940-2014 for each model. The same exact layout of maps is displayed for the coefficient of variation.
Bias maps of the variance and coefficient of variation of JJAS mean precipitation calculated for the whole historical period 1940–2014 for each model.
Timeseries showing the evolution of the 30-year variance and coefficient of variation (standard deviation divided by the mean) of JJAS mean precipitation over the historical period, including trends and inter-model spread.
3.1. Define plotting functions#
The functions presented here are used to plot layouts of the variance and coefficient of variation of seasonal mean precipitation over the whole historical period.
Three layout types can be displayed, depending on the chosen function:
Layout including the reference ERA5 product, the ensemble median, the bias of the ensemble median, and the ensemble spread:
plot_ensemble()is used.Layout including every model:
plot_models()is employed.Layout including the bias of every model:
plot_models()is used again.
3.2. Plot ensemble maps#
In this section, we invoke the plot_ensemble() function to visualise the variance values for JJAS mean precipitation over the period 1940–2014 for: (a) the reference ERA5 product, (b) the ensemble median (defined as the median of the variance values for the selected subset of models, calculated for each grid cell), (c) the bias of the ensemble median, and (d) the ensemble spread (calculated as the standard deviation of the variance for the selected subset of models). The same exact layout of maps is displayed for the coefficient of variation.
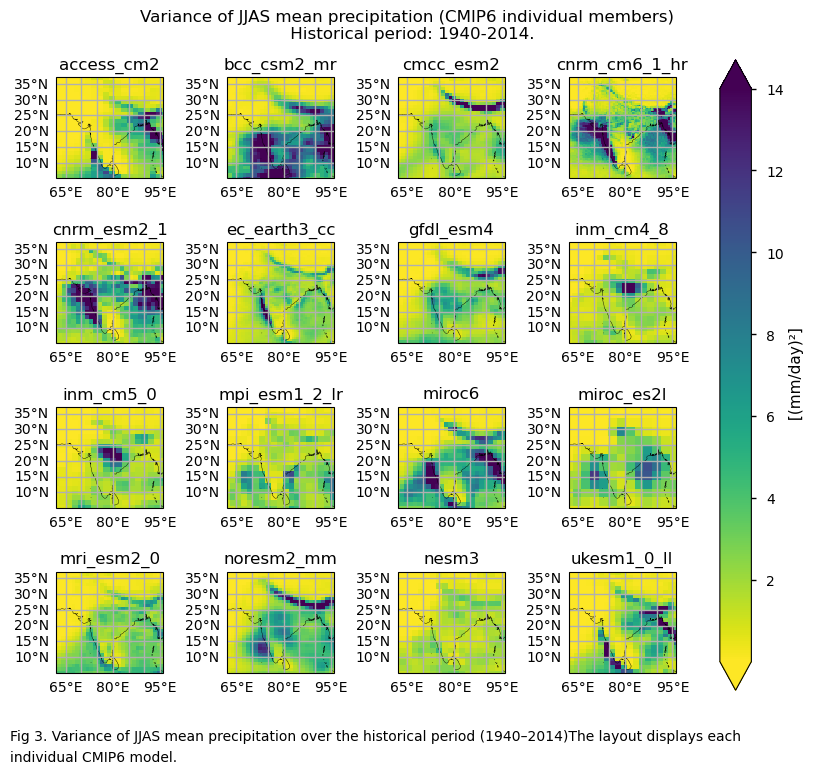
3.3. Plot model maps#
In this section, we invoke the plot_models() function to visualise the variance and the coefficient of variation of JJAS mean precipitation over the period 1940–2014 for every model individually. Note that the model data used in this section maintains its original grid.
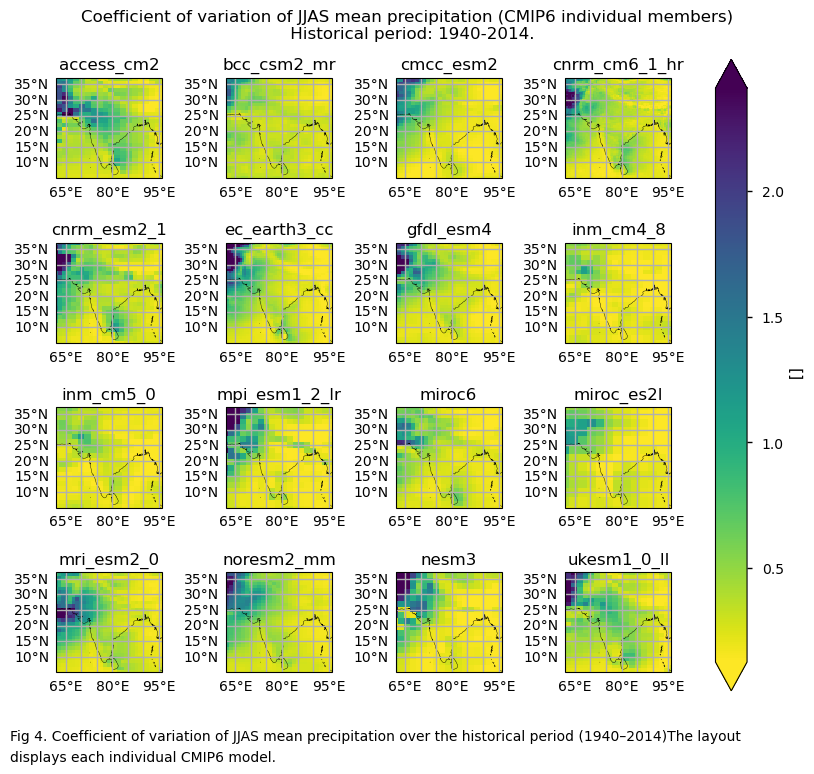
3.4. Plot bias maps#
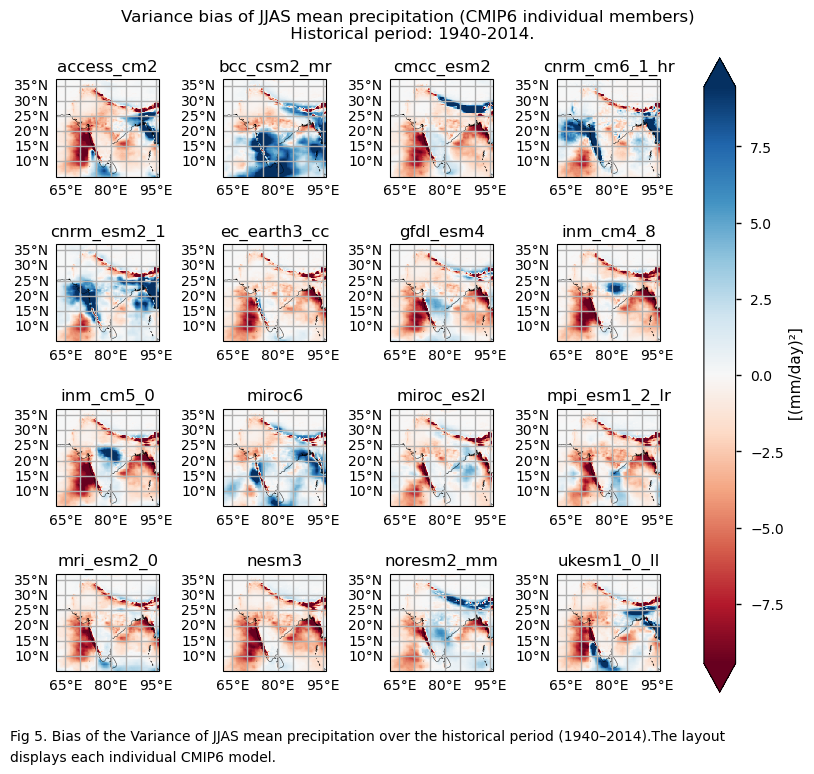
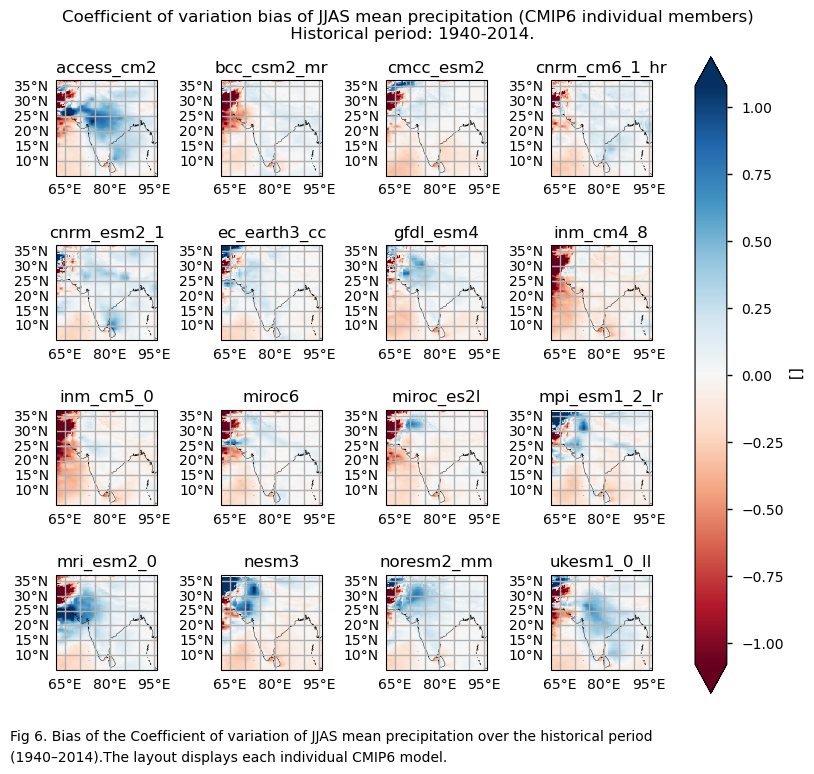
In this section, we invoke the plot_models() function to visualise the bias of the variance and the coefficient of variation of JJAS mean precipitation over the period 1940–2014 for every model individually. Note that the model data used in this section has previously been interpolated to the ERA5 grid.
3.5. Timeseries of the coefficient of variation#
This section examines the time series of spatially averaged variance and coefficient of variation, calculated from JJAS mean precipitation over the historical period using a 30-year window. The analysis compares the CMIP6 ensemble median, ERA5, and individual models, highlighting trends for both the CMIP6 ensemble median and ERA5. It also displays the ensemble spread, along with the slope values of the trends for ERA5 and the CMIP6 ensemble median.
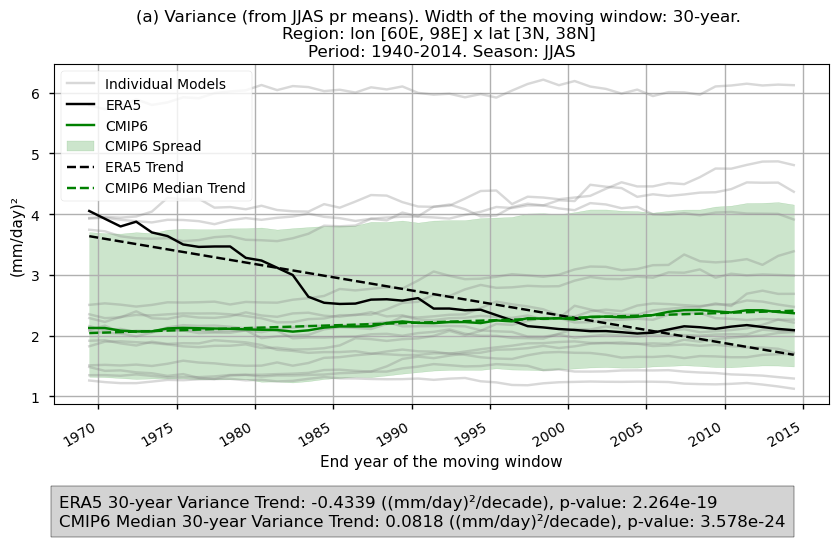
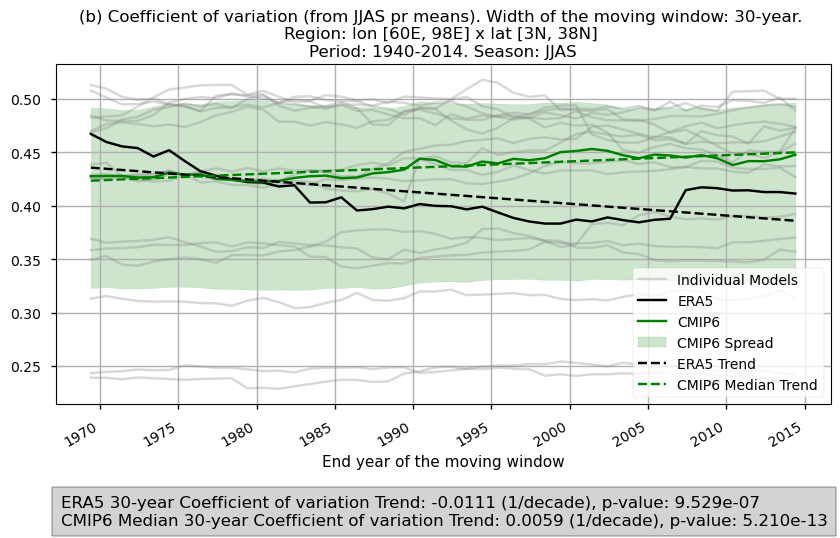
Fig 7. Time series of the spatially averaged values for the chosen variability formulations: (a) variance and (b) coefficient of variation for the JJAS mean precipitation over the period 1940–2014. The variance and coefficient of variation have been calculated using a 30-year window. Each time series displays the CMIP6 ensemble median (green), ERA5 (black), and individual models (grey), with dashed lines indicating the trend for the CMIP6 ensemble median and ERA5. The shaded area represents the ensemble spread. A grey box at the bottom displays the trend slope.
3.6. Results summary and discussion#
Substantial differences in spatial patterns can be observed depending on the formulation used to represent inter-annual variability during the Monsoon season (JJAS). This notebook uses two formulations: variance and the coefficient of variation (standard deviation divided by the mean).
Large differences in sign, magnitude, and spatial patterns of the biase are observed in the analyses using variance to represent inter-annual variability. Despite the differences across the subset of considered CMIP6 models, there is agreement in showing strong dependencies on orography and regions with high precipitation. These regions exhibit high biases due to elevated mean JJAS precipitation, although these biases are not necessarily large relative to the mean. Using the coefficient of variation eliminates this effect and may be more useful for assessing variability normalised to the mean amount of precipitation during the Monsoon period.
Generally, there are smaller differences depending on the model selection for the coefficient of variation, compared to the differences observed for the variance formulation. Inland north-western regions show large negative biases. These regions have, on average, near-zero or very low seasonal averages. One hypothesis to explain this may be that unusually wet seasons are underestimated in comparison to ERA5.
The time series displaying the evolution of variance and coefficient of variation (using a 30-year window) show a decline for ERA5 in the considered region. Based on the calculated trend, an approximate 50% reduction is estimated when comparing the start and end of the period for the variance formulation. This decrease is smaller when considering the coefficient of variation (11%). The ensemble median trend for the subset of considered CMIP6 models shows an increase of around 7% for the variance and 6% for the coefficient of variation over the same period, which differs from the trends observed in ERA5. It is important to note that the region studied is extensive. The time series represent spatially averaged values, and their results should be interpreted with care, as focusing on sub-regions within the domain may yield significantly different outcomes. Additionally, CMIP6 models exhibit notable inter-model spread, and a larger ensemble could also influence the results.
The time series results suggest that year-to-year variability in monsoon precipitation has become less pronounced according to ERA5. This is evident not only from the variance magnitude, which can be influenced by the evolution of the mean (shown to decrease during this period [3]), but also from the coefficient of variation, which removes this dependency by normalising the standard deviation with the mean.
What do the results mean for users?
Importance of the selection of the variability formulation. The coefficient of variation has less dependency on orography because it is normalised by the mean. Moreover, the differences across the considered subset of models in the spatial pattern of the bias for the coefficient of variation appear to be smaller than in the case of variance. However, special attention needs to be given when using the coefficient of variation for the inland north-western region (where the seasonal mean precipitation is usually very low or near zero).
ERA5 has biases [5][6]. This assessment uses it because a longer period is available and allows a more robust analysis of the temporal evolution of the variability. However the user may consider using other reference climate products such as the GPCP. This could lead to different results.
ERA5 shows a decrease in inter-annual variability over the historical period for the considered region, while the CMIP6 ensemble median indicates a slight increase. It is important to consider a larger ensemble and note that the time series in this assessment represent spatially averaged values, which may yield different results when focusing on other sub-regions.
Given the challenges in replicating the spatial patterns for variance and the coefficient of variation, as well as the difficulties in representing its temporal evolution, bias correction of CMIP6 projections may be essential for effectively using future projections of inter-annual precipitation variability. This enhancement could encourage the water management sector to adopt CMIP6 future projections, which can be extremely useful when designing strategies to adapt to projected changes in precipitation.
Assessments using regional climate models (RCMs) may produce different results (not necessarily better) due to their higher spatial resolution, better representation of local processes, and more detailed treatment of orography and land-atmosphere interactions.
It is important to note that the results presented are specific to the 16 models chosen, and users should aim to assess as wide a range of models as possible before making a sub-selection.
ℹ️ If you want to know more#
Key resources#
Some key resources and further reading were linked throughout this assessment.
The CDS catalogue entries for the data used were:
CMIP6 climate projections (Monthly - Precipitation): https://cds.climate.copernicus.eu/datasets/projections-cmip6?tab=overview
ERA5 monthly averaged data on single levels from 1940 to present (mean total precipitation rate): https://cds.climate.copernicus.eu/datasets/reanalysis-era5-single-levels-monthly-means?tab=overview
Code libraries used:
C3S EQC custom functions,
c3s_eqc_automatic_quality_control, prepared by B-Open
References#
[1] Thornton, P. K., Ericksen, P. J., Herrero, M., and Challinor, A. J., 2014. Climate variability and vulnerability to climate change: A review. Global Change Biol. 20, https://doi.org/10.1111/gcb.12581
[2] Masroor, M., Rehman, S., Avtar, R., Sahana, M., Ahmed, R., Sajjad, H., 2020. Exploring climate variability and its impact on drought occurrence: evidence from Godavari Middle sub-basin, India. Weather and Climate Extremes. 30, 100277. https://doi.org/10.1016/j.wace.2020.100277
[3] Kulkarni, A. et al., 2020. Precipitation Changes in India. In: Krishnan, R., Sanjay, J., Gnanaseelan, C., Mujumdar, M., Kulkarni, A., Chakraborty, S. (eds) Assessment of Climate Change over the Indian Region. Springer, Singapore. https://doi.org/10.1007/978-981-15-4327-2_3
[4] Longobardi, A., Boulariah, O., 2022. Long-term regional changes in inter-annual precipitation variability in the Campania Region, Southern Italy. Theor Appl Climatol 148, 869–879. https://doi.org/10.1007/s00704-022-03972-2
[5] Ramon, J., Lledó L., Torralba, V., Soret, A., Doblas-Reyes, F.J., 2019. What global reanalysis best represents near-surface winds?. Q J R Meteorol Soc. 2019; 145: 3236–3251. https://doi.org/10.1002/qj.3616
[6] Hassler, B., and Lauer, A., 2021. Comparison of Reanalysis and Observational Precipitation Datasets Including ERA5 and WFDE5. Atmosphere, 12, 1462. https://doi.org/10.3390/atmos12111462