

4.5. Assessing possible outcomes of seasonal temperature forecast#
Production date: 02-05-2024
Produced by: Johannes Langvatn (METNorway)
🌍 Use case: Providing seasonal forecast to the public#
❓ Quality assessment questions#
How can I assess the forecast temperatures for two months time?
Do the different forecast systems provide a consistent outlook?
Seasonal forecast in C3S provides a prediction of the near future. For two months prediction time, emphasis should be put on a probabilistic approach and understanding the uncertainty in the prediction [1]. To this end, here we assess important characteristics of seasonal forecasts, how they can be compared, interpreted and used.
📢 Quality assessment statement#
These are the key outcomes of this assessment
This notebook shows one way to visualise the range of outcomes covered by the ensemble members in seasonal forecast systems from C3S and compare it with the forecast system climatology as a reference.
The resulting plots show the uncertainty in the forecast (range of outcomes for each forecast system and between forecast systems), how the seasonal forecast differs from the model climatology, and how likely it is that the coming months will be in the lower, middle or upper terciles of the climatology.
For the specific example provided, forecasts issued in June 2023 and valid for 2m air temperature for a region over Southern Norway in July 2023 shows that:
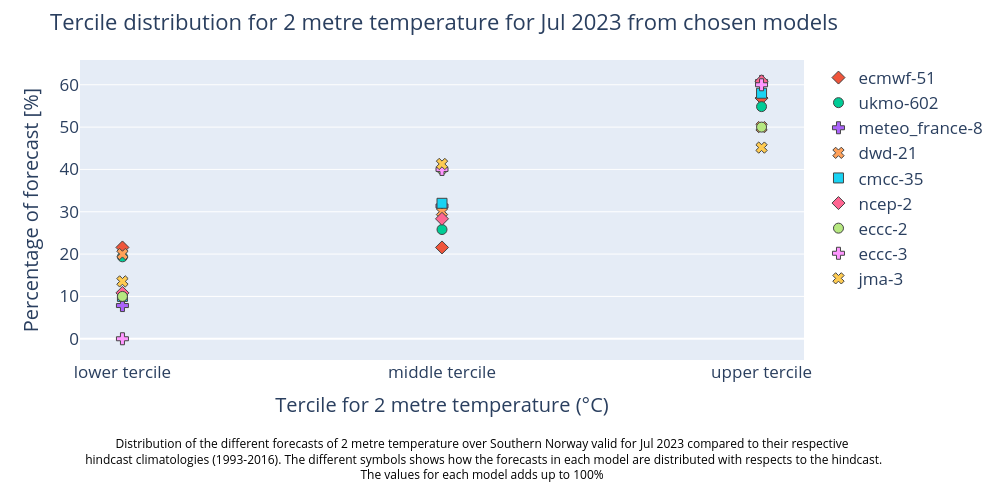
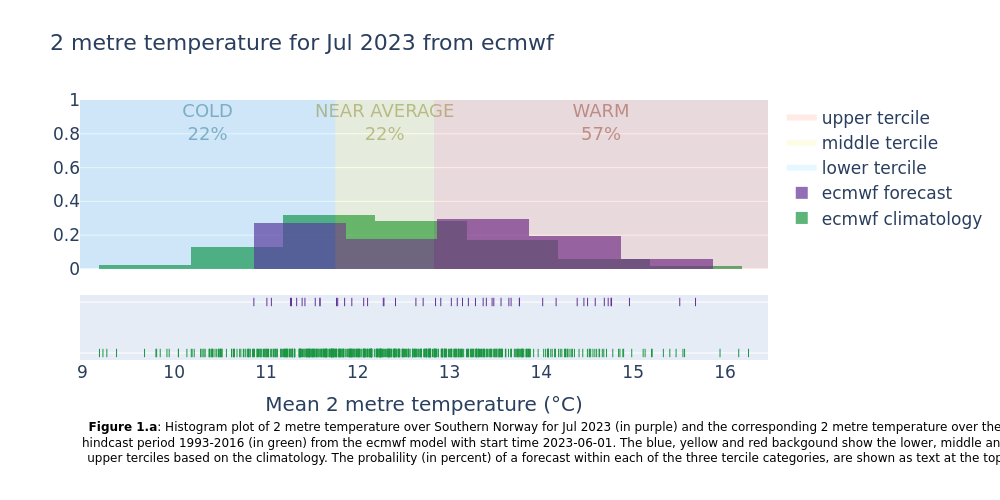
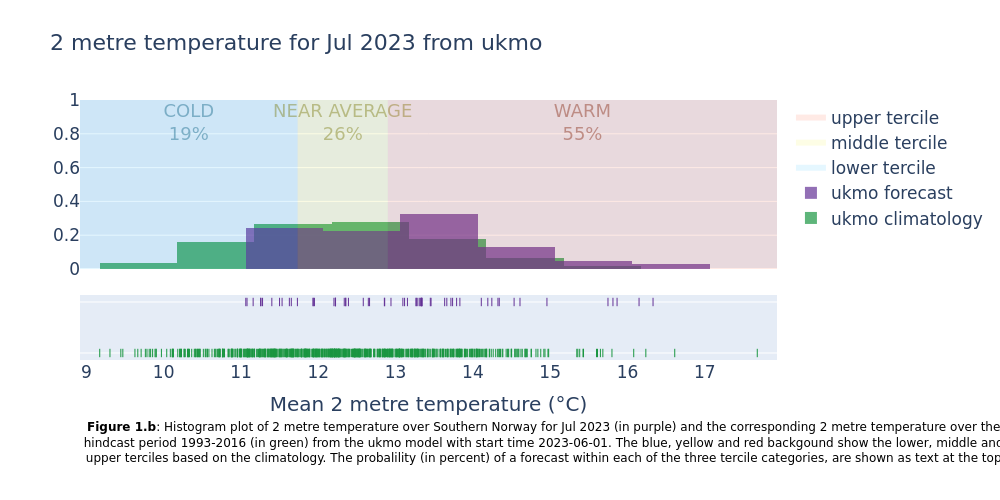
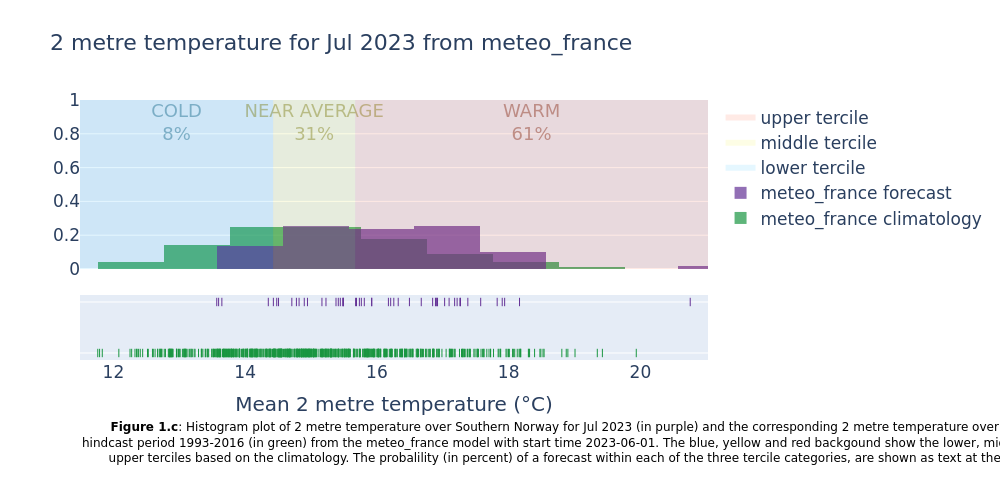
All forecast systems provide a consistent outlook that the month will end up in the upper tercile of the climatology (probabilities between 45 and 61% for the different systems).
The climatology of the different forecast systems are quite different, hence they need to be bias adjusted before their face-value can be combined in a multi-model forecast. This emphasises the need for always comparing the forecasts with the hindcast climatology.
If the forecast systems yield inconsistent outlooks, a multi system summary (see below) can be employed to determine whether there’s a broad consensus with only a few models deviating, or if there’s a complete disagreement in forecasted probabilities. In the former scenario, the divergent model systems might be seen as outliers highlighting the possibility of different outcome than the majority. While in the latter, the reliability of the forecast is reduced.
Seasonal forecasts are inherently probabilistic and must be interpreted considering the chaotic nature of the system and the forecast systems’ capabilities and limitations. In general, multi-model system forecasts often provide better estimates of the uncertainty than applying a single system. Due to the long lead times involved and associated uncertainty, forecast skill can only be expected for large-scale features in space and time and using e.g. probabilities for terciles can be useful in decision-making.
📋 Methodology#
This code in this notebook enables an assessment of the range of possible outcomes for two months prediction time of seasonal forecast systems, in the case of near surface temperature. For reference, the forecasts are presented together with the expected (normal) range of temperatures for the month and region of interest. The normal range is based on so-called hindcasts of past weather from the same forecasting system.
This quality assessment does not assess the historical quality of the seasonal forecast, as the forecasts (e.g. hindcasts) are not compared with historical outcomes (e.g. observations or re-analyses like ERA5). This will be done in another notebook, and is also done here, in verification plots for the C3S graphical products.
1. Choose data to use and setup code
Choose a selection of forecast systems and versions, forecast start time (year and month), hindcast period (normally 1993-2016), region (latitude-longitude box).
Define a weighting function for the gridded data, and if needed conversions for the variables used.
2. Seasonal forecast and hindcast data retrieval and area average
Retrieve data for monthly means of all ensemble members for the selected parameters above, from the data catalogue ”Seasonal forecast monthly statistics on single levels”, for both forecasts and hindcasts
Compute the spatial mean of 2 m temperature.
3. Make histogram plots for each forecast system
Showing the normal range of each forecast system (hindcast distribution) together with the forecast outcomes. Included in the plots are probabilities of near surface temperature forecast within the lower, middle and upper terciles of the normal range.
4. Summarise the probabilities for each system
The forecast probabilities are combined and visualised at the end in a multi-model plot.
📈 Analysis and results#
1. Choose data to use and setup code#
In this section, the customisable options of the notebook are set. These variables consists of:
Model forecast system
forecast centre
system version
Time
forecast year
first year of the model hindcast
last year of the model hindcast
forecast month
Region of interest
name of the region (only used in figure-captions)
latitudes given as slice(maxlat, minlat) in degrees (north is positive values)
longitudes given as slice(minlon, maxlon) in degrees (east is positive values)
Weather parameters
name of variable in grib-file
name of variable in CADS-api
name of the three tercile categories (lower, middle and upper tercile)
Download parameters
chunk size of the data
number of concurrent request for parallel download
Combination of originating centre and model system (Operational forecast model systems per March 2024):
centre = “ecmwf”, system = “51”
centre = “ukmo”, system = “602”
centre = “meteo_france”, system = “8”
centre = “dwd”, system = “21”
centre = “cmcc”, system = “35”
centre = “ncep”, system = “2”
centre = “jma”, system = “3”
centre = “eccc”, system = “2”
centre = “eccc”, system = “3”
To see the different alternatives see the API-request at the bottom of this page
Note: if you want to change parameter you might also want to add conversion functions in this section. For example for precipitation you might want to convert from precipitation rate to total precipitation amount
The data is downloaded to a 1 degree lat/lon grid from 89.5 N to 89.5 S and 179.5 W to 179.5 E which is the grid for the latest model versions of all models except for JMA. The JMA data, which is on a 1.25 x 1.25 grid, is therefore interpolated. This is as a convencience to ensure that the lat-lon slices return the same grids for the different systems, and that we can use similar requests to cds. Otherwise the interpolation would not be needed since we are doing an area average. Also, the ‘weights’ flag will be set to ‘True’ in the next section, which means the area average is carried out taking into account the variation of the cell areas with cosine of latitude in the regular lat-lon grid.
2. Seasonal forecast and hindcast data retrieval and area average#
In this section the seasonal data are downloaded and transformed into regionalised means. The time is transformed into two variables ‘time/indexing_time’ and ‘forecast month’. For burst ensemble models ‘time’ is the time when all ensembles are initialised. For lagged ensemble models (JMA, NCEP and UK MetOffice) the ‘indexing_time’ must be used instead of ‘time’ in order to get the same variable, since ensemble members have different initialisation time (See more on this confluence-page). The ‘forecast month’ is the lead time month from month 1 to 6.
100%|██████████| 24/24 [00:00<00:00, 34.70it/s]
100%|██████████| 1/1 [00:00<00:00, 47.55it/s]
100%|██████████| 24/24 [00:00<00:00, 48.03it/s]
100%|██████████| 1/1 [00:00<00:00, 54.61it/s]
100%|██████████| 24/24 [00:00<00:00, 63.89it/s]
100%|██████████| 1/1 [00:00<00:00, 43.95it/s]
100%|██████████| 24/24 [00:00<00:00, 39.22it/s]
100%|██████████| 1/1 [00:00<00:00, 51.80it/s]
100%|██████████| 24/24 [00:00<00:00, 50.26it/s]
100%|██████████| 1/1 [00:00<00:00, 32.12it/s]
100%|██████████| 24/24 [00:00<00:00, 33.74it/s]
100%|██████████| 1/1 [00:00<00:00, 45.89it/s]
100%|██████████| 24/24 [00:01<00:00, 20.87it/s]
100%|██████████| 1/1 [00:00<00:00, 3.85it/s]
100%|██████████| 24/24 [00:00<00:00, 33.76it/s]
100%|██████████| 1/1 [00:00<00:00, 43.51it/s]
100%|██████████| 24/24 [00:00<00:00, 47.80it/s]
100%|██████████| 1/1 [00:00<00:00, 46.99it/s]
3. Make histogram plots for each forecast system#
This section extracts data for the selected region from the monthly data on single levels and compute the spatial mean of the chosen variable. Then density plots are created for each lead time month. The resulting plots show the uncertainty in the forecast (range of outcomes), how the seasonal forecast differs from the model climatology, and how likely it is that the coming months will be in the lower, middle or upper terciles of the climatology.
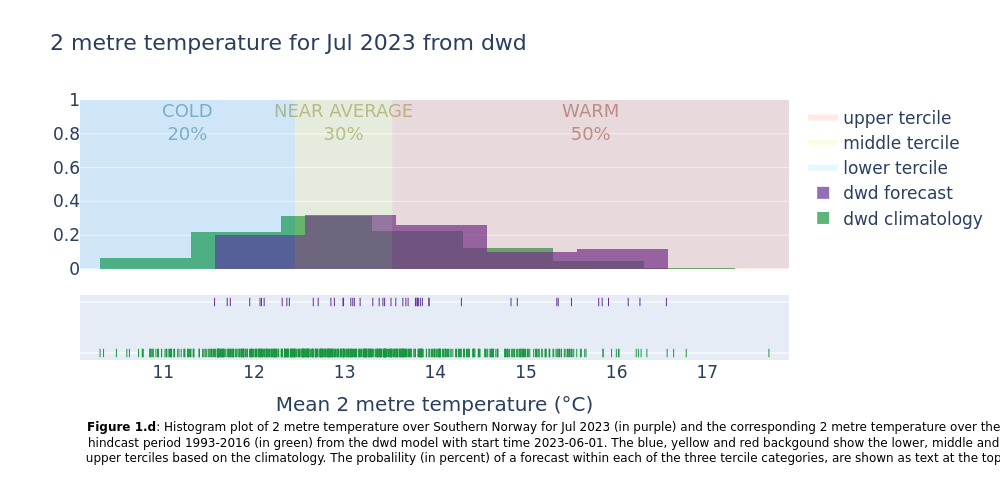
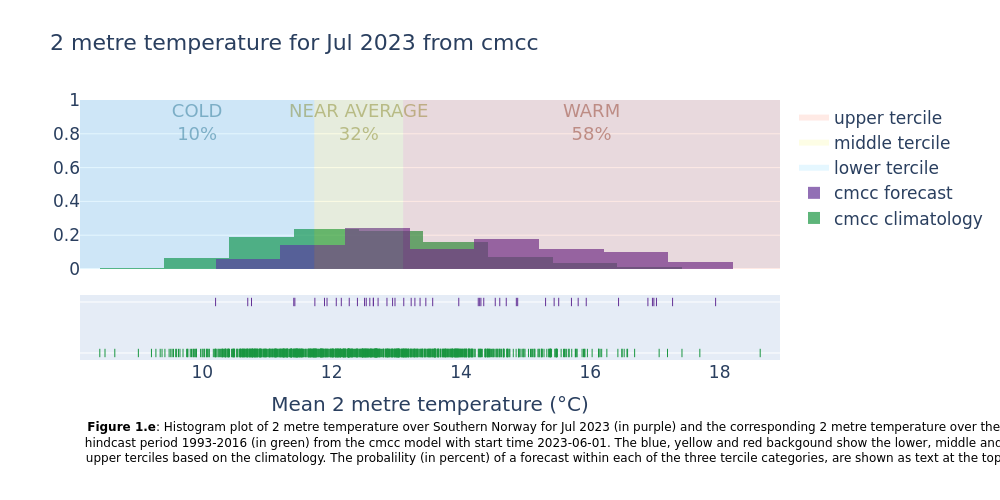
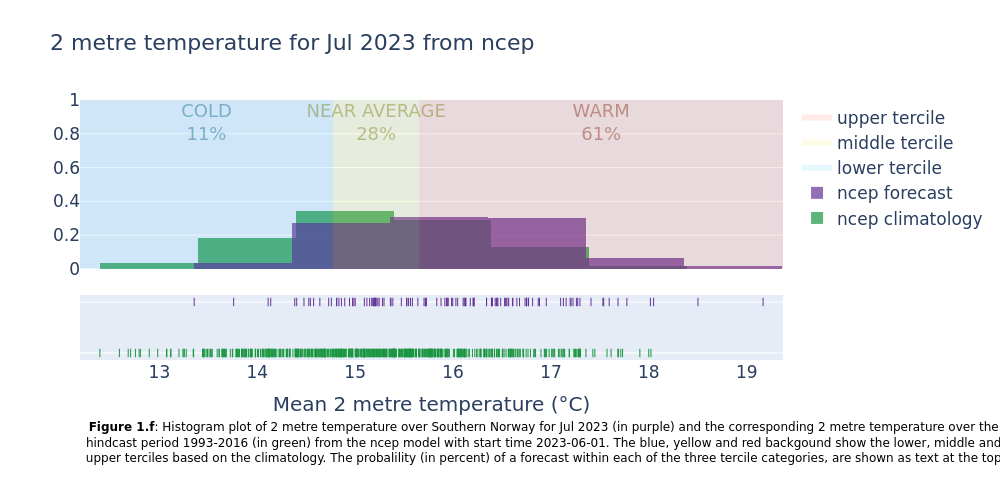
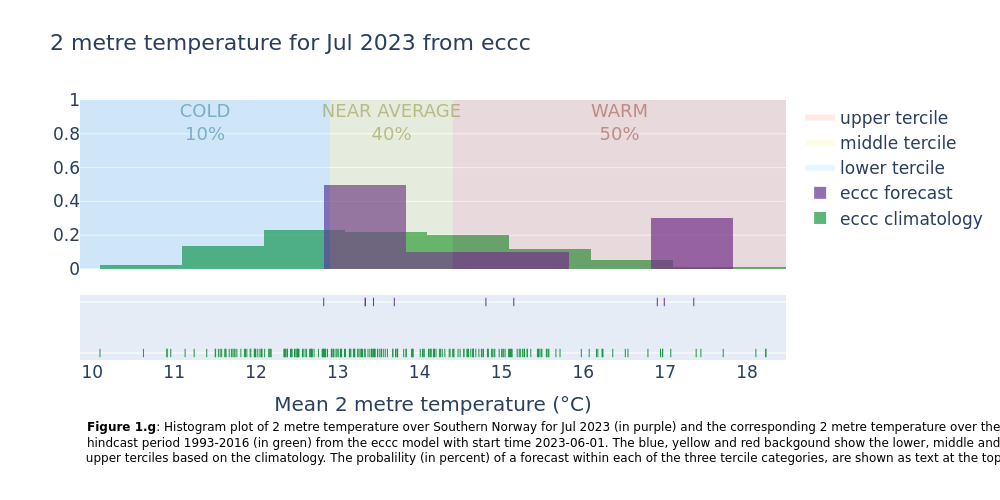
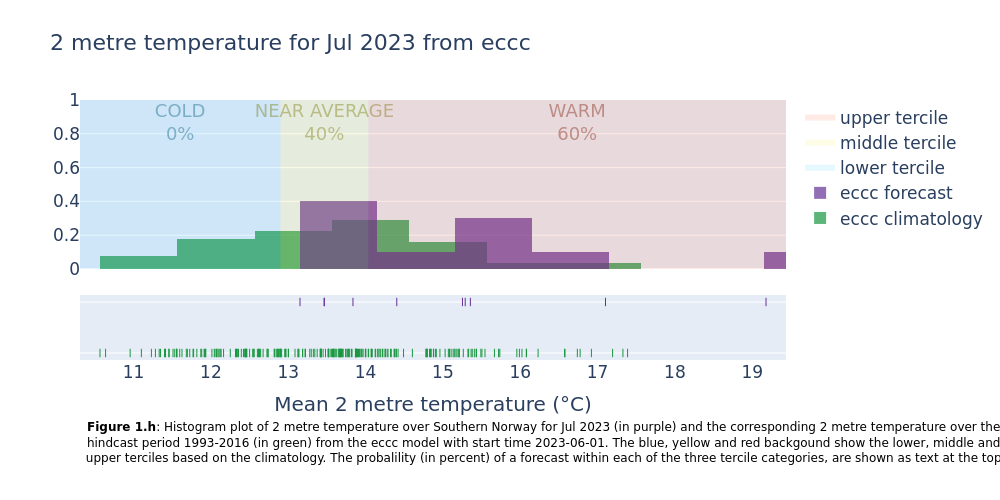
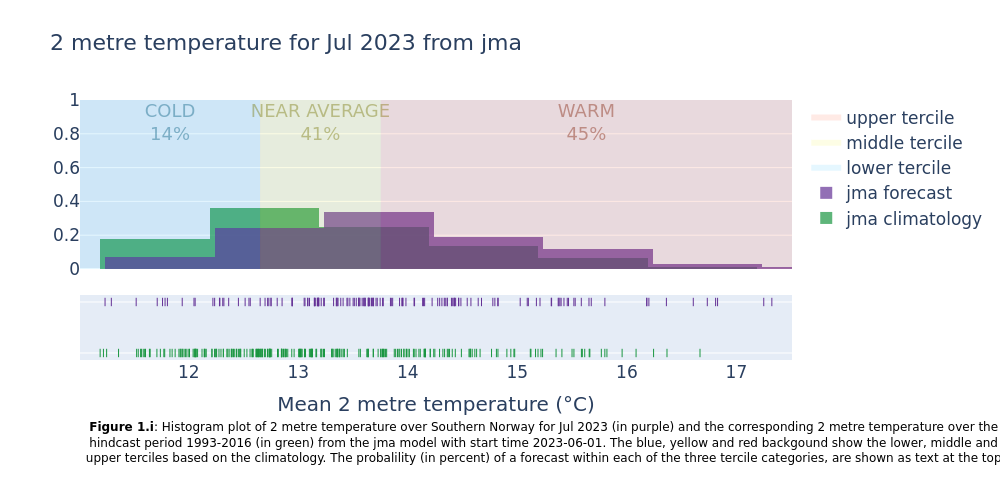
4. Summarise the probabilities for each system#
This section summarises the forecasted probabilites of the temperature being colder, near average or warmer than their respective hindcast climatologies for all systems. The figure produced reinforces the findings from the figures produced in the last section, that it is more likely to be warmer than usual, compared to the model hindcast climatology than it is to be average or colder compared to the hindcast.
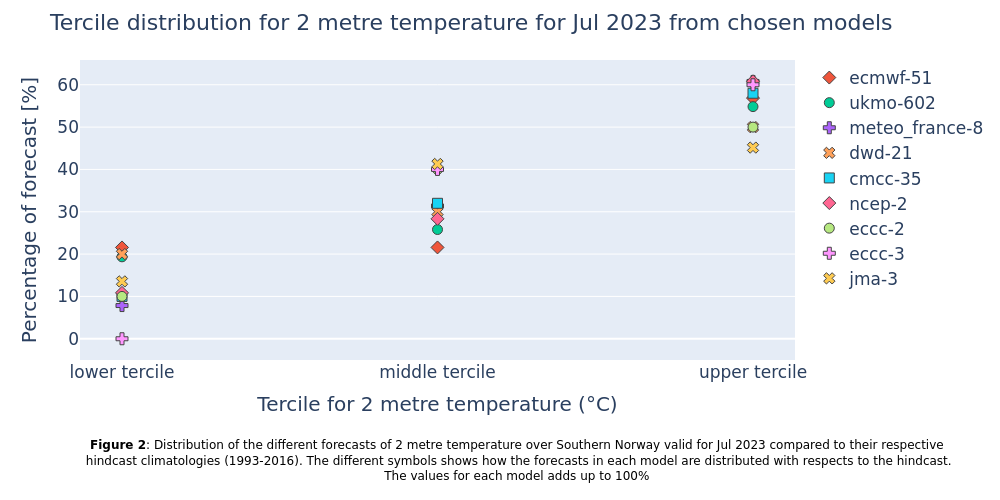
Figure 1 shows the uncertainty, the range of outcomes covered by the ensemble members in the different seasonal forecast systems separately, while Figure 2 shows the probabilities from all the individual forecast systems for the lower, middle, and upper tercile together. While all systems show the same tendency towards that the upper tercile has the highest probability, there is still a substantial chance for the lower and middle tercile to happen as well. In fact, the probability of not ending up in the upper tercile is still around 50%.
To answer to the questions stated initially; The generated plots assess the forecasted temperatures with a two months lead time and indicate that the most likely tercile is the upper tercile, but that it is almost equally likely that we will not end up in the upper tercile. In particular, Figure 2 shows that the different seasonal forecast systems provide a consistent outlook. In general, multi-model system forecasts often provide better forecasts and estimates of the uncertainty than applying a single model system (e.g. Doblas-Reyes et al., 2009 [2]).
There are multiple ways to visualize seasonal forecasts and their associated uncertainty as probabilistic forecasts. C3S provides more examples of this as in the graphical products: https://climate.copernicus.eu/charts/packages/c3s_seasonal/
ℹ️ If you want to know more#
Key resources#
Seasonal forecast single level anomalies: DOI: 10.24381/cds.7e37c951
Seasonal forecast monthly statistics single level: DOI: 10.24381/cds.68dd14c3
Code libraries used#
xarray
numpy
express and figure_factory from plotly
C3S EQC custom functions,
c3s_eqc_automatic_quality_control, prepared by B-Open
References#
[1] - Weisheimer A. and Palmer T. N.. 2014 On the reliability of seasonal climate forecasts J. R. Soc. Interface. 11: 20131162. https://doi.org/10.1098/rsif.2013.1162
[2] - Doblas-Reyes, F.J., Weisheimer, A., Déqué, M., Keenlyside, N., McVean, M., Murphy, J.M., Rogel, P., Smith, D. and Palmer, T.N. (2009), Addressing model uncertainty in seasonal and annual dynamical ensemble forecasts. Q.J.R. Meteorol. Soc., 135: 1538-1559. https://doi.org/10.1002/qj.464