

4.2. Seasonal forecasts bias assessment for impact models#
Production date: 08/03/2024
Produced by: Sandro Calmanti (ENEA)
🌍 Use case: Risk assessment in agriculture using seasonal forecasts as an input for climate impact models.#
❓ Quality assessment questions#
Do I have to correct systematic errors in temperature and precipitation before using seasonal forecasts as an input for my crop model?
Can I assume that climate models always produce the same systematic error for seasonal forecasts over a certain area?
Seasonal forecasts can be used as an input to crop models for agricultural risk assessment [1] [2] [3]. However, the presence of systematic errors can undermine the performance of crop models in a number of ways, particularly when critical thresholds in the plant growth process are considered. Similar problems can arise in other sectoral applications, such as the management of renewable energy facilities [4], or the alerting of national health services for the occurrence of summer heat waves [5]. In addition to temperature and precipitation, the most commonly used climate variables for risk assessment in all sectoral applications, the notebook also considers wind speed and dew point temperature. While these variables are commonly used in agricultural applications to calculate potential evapotranspiration, the results of the assessment are also valuable for several other sectors.
📢 Quality assessment statement#
These are the key outcomes of this assessment
Seasonal forecasts should be bias-corrected before being used as input to climate impact models. Depending on the impact model, it might be advisable to bias-correct the resulting impact indicator [6]
Model drifts and bias tend to be a complex function of both the start time of the forecast and of its valid time, with a slightly stronger dependence on the valid time for the case of temperature and precipitation. Therefore, the most appropriate approach to produce unbiased forecasts for use in impact models must be selected on a case-by-case basis.[7] [8]
For the implementation of bias correction procedures, it is recommended that reference climatologies are computed for time scales no longer than one month, since the typical model bias changes on a monthly basis. Instead, the correction of model biases on a seasonal (i.e. three months) timescale may lead to a loss of quality.
Similarly, the calculation of multi-model statistics requires a recalibration of the model output in order to align all models around the same climatological distribution. [9]
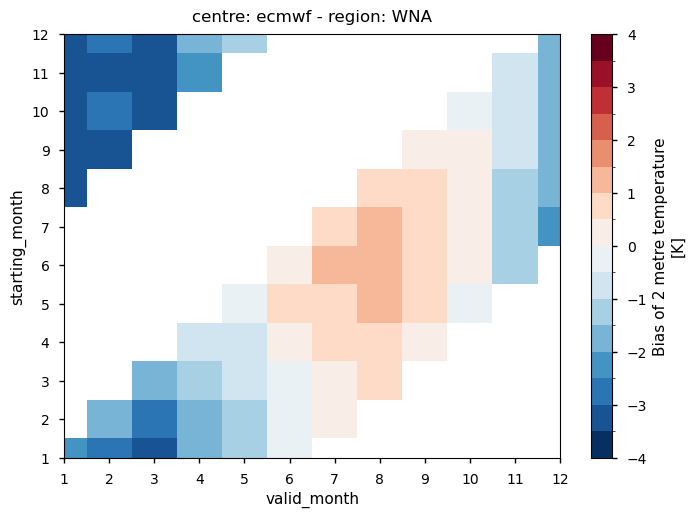
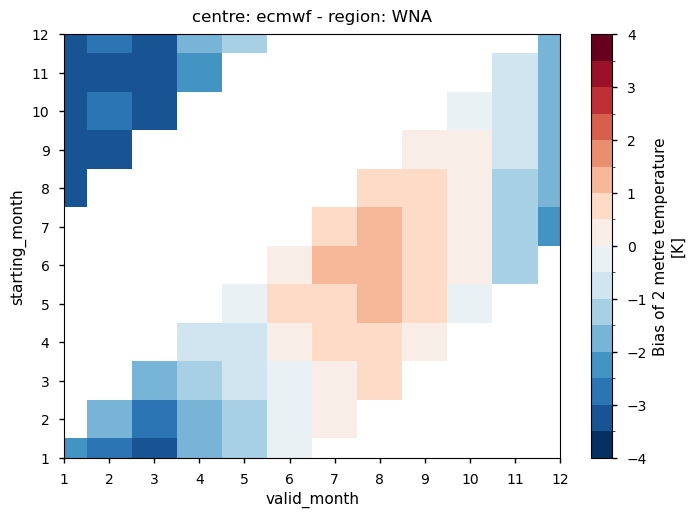
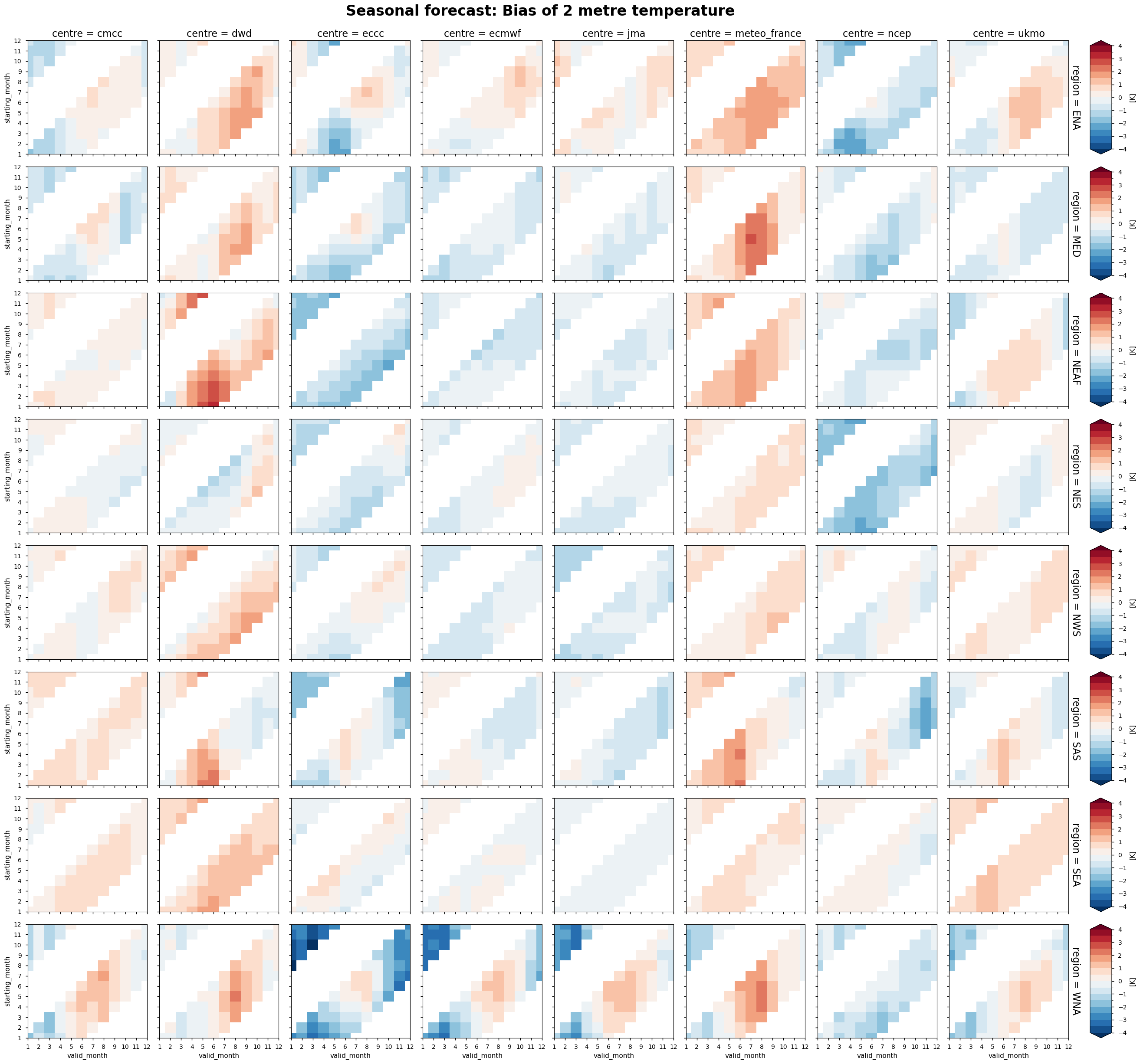
Fig. 4.2.1 The figure shows a sample of the ECMWF monthly temperature bias for Western North America as a function of the starting month and of the valid month of the forecast. More details on how to interpret the results are available below in the notebook.#
📋 Methodology#
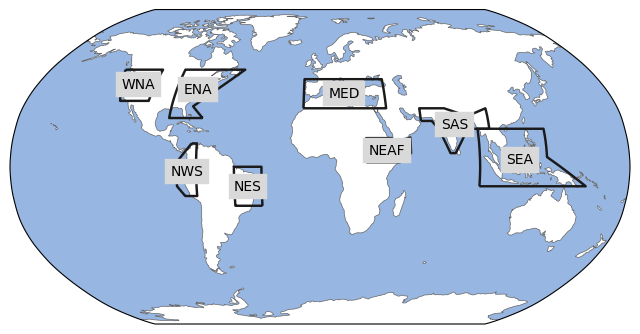
This notebook provides a comprehensive assessment of the systematic errors of the forecast systems by comparing the model predictions with the ERA5 reanalysis. The analysis is carried out for eight regions selected from those used in the IPCC-AR6 (see figure below), which capture the spatial scale of the main systematic errors already analysed in previous studies [10]
The analysis and results are organised in the following steps, which are detailed in the sections below:
1. Choose the data to use and setup the code:
Import required packages
Define parameters describing regions, variables, and data
Plot the chosen regions
Define required functions
Show a sample global map of temperature biases
2. ERA5 data retrieval and area average:
Retrieve monthly ERA5 data and compute the regional mean climatology, i.e. 12 values for each area
Compute area averages
3. Seasonal hindcast data retrieval and area average:
Retrieve monthly seasonal forecast data from all available centres and for all starting dates, compute the monthly mean climatology (i.e. 6 values, since each forecast is valid for 6 months) and subtract the corresponding ERA5 climatology.
Compute area averages
Plot a sample map
Plots are shown in a comprehensive set of panels that provide an overview of the multimodel performance
The results are summarised and discussed
Note that crop models and other sectoral applications tend to use daily values rather than the monthly statistics considered in this notebook, and they focus on smaller areas compared to the regions considered below. However, the analysis of monthly data over the IPCC-AR6 regions provides a useful overview of the overall characteristics of the dataset.
Note that for ECCC, only one of the two systems has been analysed (system 3). This is different from the approach taken in the C3S charts, and CanSIPSv2.1, where both systems are combined (system 2 and system 3).
📈 Analysis and results#
1. Choose the data to use and setup the code#
Import required packages#
We use the regionmask package to extract climatologies for a few selected regiones that have already e been adopted in several climate studies, including the analysis presented in the latest IPCC report.
A description of the regions adopted for climate assesements in the scientific literature is available here.
Define parameters describing regions, variables, and data#
In this notebook the analysis of the model bias is done for 5 variables from all 8 originating centres. The SREX regions selected for the analysis are:
NEAF: Northern-East Africa
ENA: Eastern North America
MED: Southern Europe/Mediterranean
NEB: North-eastern Brazil
SAS: Southern Asia
SEA: South-Eastern Asia
WNA: Western North America
NWS: Western Coast of South America
A common_request is defined in order to cover the entire global domain and the entire hindcast period from 1993 to 2016. Specific data requests are then defined for the reanalysis and for the seasonal forecasts, so that all available months and lead times are retrieved for the analysis.
Plot the chosen regions#
For the bias analysis we use 8 out of the 45 regions defined in the regionmask package in order to assess the systematic errors of the modelling systems under different climatic regimes (tropical, extratropical, continental, maritime) with a number of cases maneageable within the notebook.
Define the required functions#
The
regionalised_spatial_weighted_meanfunction extracts the regional means over the selected domains. It uses spatial weighting to account for the latitudinal dependence of the grid size in the lon-lat grids used for the reanalysis and for the forecast models. The bias is then calculated later in the notebook by simply subtracting the regional means.The
postprocess_dataarrayfunction performs two important postprocessings operations required to align the arrays containing the reanalsysis and the forecast data.The time dimensions are renamed to allow the broadcasting of the dimension
valid_time, which is used to compute the bias, independently of the correspondinglead_timesin the forecast.Furthermore, the cumulative variables have to be rescaled in order to make ERA5 data and seasonal forecast data comparable on a monthly timescale. A conversion table for accumulated variables is available in the Copernicus Knowledge Base repository.
The function
get_seasonal_mapsis used to derive a sample bias map to illustrate how the analysis is performed.The
monthly_meanfunction will be used to derive the monthly values at the appropriatemonthly_meanbefore calculating the bias.
2. ERA5 data retrieval and area average#
The regionalised_spatial_weighted_mean is applied for all regions and all variables selected for download. All time series of the regionalised means are collected in the same xarray ds_reanalysis.
3. Seasonal hindcast data retrieval and area average#
The regionalised_spatial_weighted_mean is applied for all centres, regions and all variables selected for download. Missing variables are handled, so the download and transform process is not interrupted. All time series of the regionalised means are collected in the same xarray ds_seasonal.
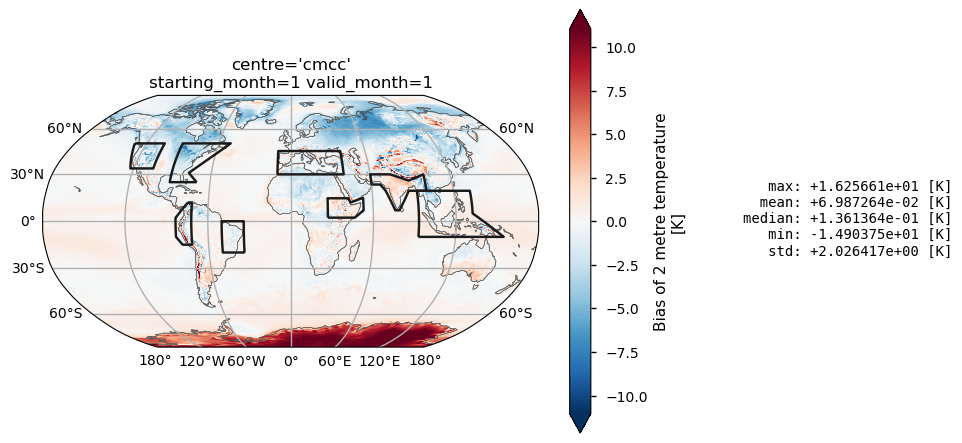
Show a sample global map of temperature biases#
To reduce computation, this notebook simplifies the bias analysis by focusing on mean values of surface variables across the chosen regions. The goal is to offer a broad overview of the bias evolution over lead times. Thus, it is crucial that the selected regions exhibit sufficient homogeneity to minimize the compensation effects from systematic errors of varying sign.
This section of the notebook offers a simple tool for exploring sample bias maps and confirming that bias sign remain relatively constant within selected regions. Additionally, it serves as an insight on the behavior of individual models summarized in the comprehensive tables provided later in the notebook.
4. Compute the hindcast bias#
The the seasonal hindcast data are arranged in a four-dimensional array ds_seasonal[i,j,n,k], where:
iis the reference start month of the forecast (from January to December)
jis the valid time of the forecast (from January to December)
nis the originating centre of the forecast (currently a maximum of 8)
kis the region (currently 8)
Correspondingly, ERA5 data are arranged in a three-dimensional array ds_seasonal[j,n,k], where:
jis the valid time of the forecast (from January to December)
nis the originating centre of the forecast (currently a maximum of 8)
kis the region (currently 8)
With such a shaping and setup of the datasets ds_seasonal and ds_reanalysis the computation of the bias is straightforward.
5. Plot and describe results#
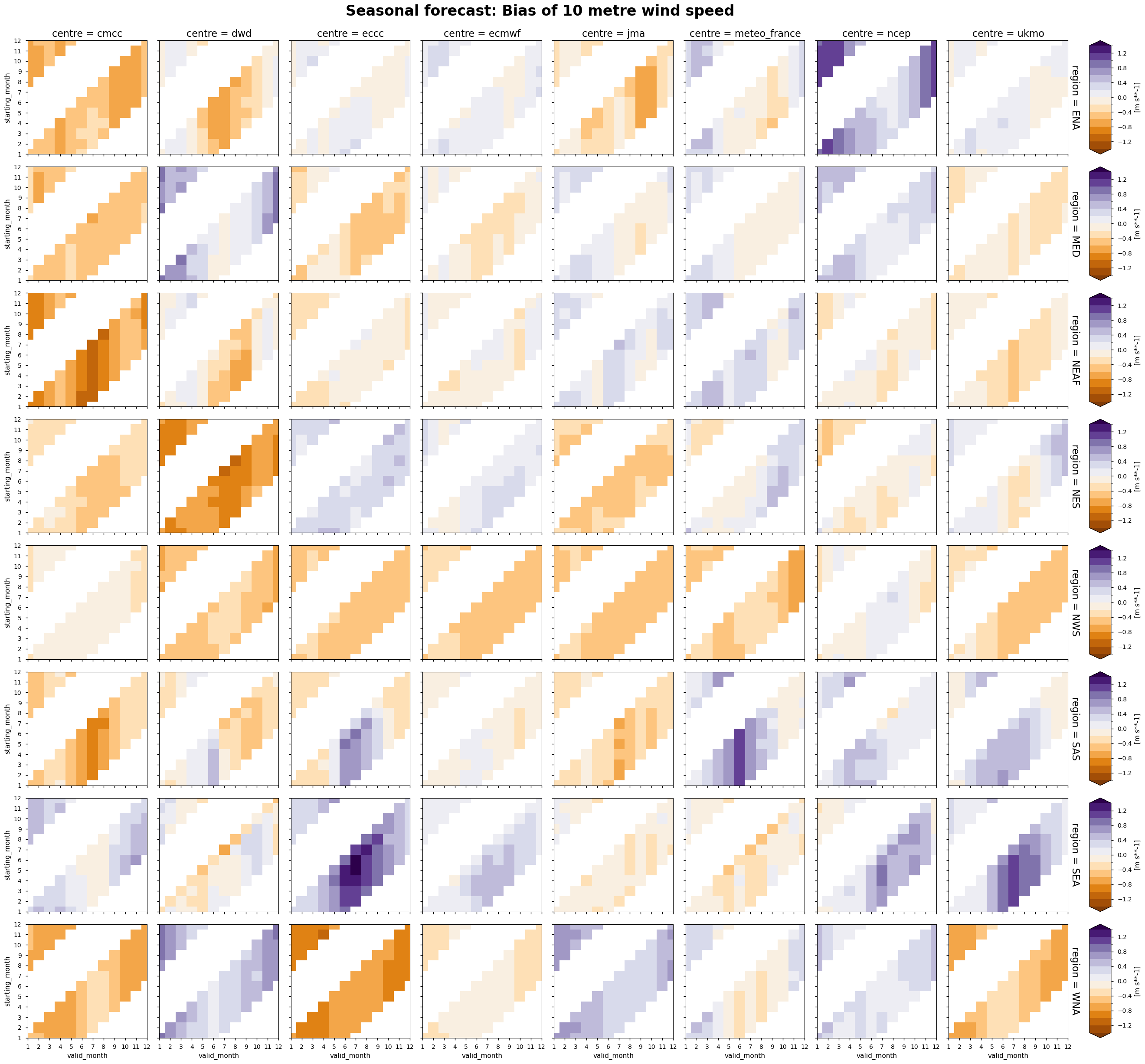
How to read the results#
The following tables summarise the monthly bias for chosen C3S seasonal systems (labelled by producing centre) and selected areas.
In each panel, the horizontal axis represents the validity period of the forecast, while the vertical axis shows the corresponding start dates. Thus, each horizontal strip of coloured tiles shows the evolution of the mean temperature bias over the six-month period of validity of each forecast.
Reading each panel from bottom to top, the strips of coloured tiles are progressively shifted by one month, corresponding to the same shift in the starting date of the forecast. The horizontal axis is periodic: forecasts starting after August have their last months on the left side of the panel.
Discussion#
The tables below summarise the monthly bias for all originating centres (columns) and for all selected areas (rows). Note that only one system (system 3) is shown from the ECCC contributions.
Temperature - All seasonal forecast models produce a significant temperature bias over most of the regions selected for analysis. Two centres, DWD and METEOFRANCE, produce a forecast with a predominant warm bias over most regions and in all seasons. The temperature bias is a function of both the start time and the valid time of the forecast, with a slightly stronger dependence on the valid time. Therefore, the bias does not increase with the lead time of the forecast. Instead, it tends to be a characteristic aspect of each model over the specific region and time of year. The seasonal cycle of the bias is particularly evident over western North America.
Precipitation - As in the case of temperature, the bias in precipitation tends to be more dependent on the validity period of the forecasts. The regions with the largest systematic bias are northeastern Brazil and southern Asia, where all models tend to overestimate the amplitude of the seasonal cycle.
Wind speed - Unlike temperature and precipitation, the bias of wind speed does not show a significant seasonal cycle over most of the selected regions. The only exceptions are northeastern Brazil and southern Asia, where some models (e.g. ECCC and NCEP) show a positive bias during the months of June to September.
Dew point temperature - As in the case of wind speed, the dew point temperature bias tends to have a weaker seasonal cycle than temperature and precipitation. However, some regions (southern Asia and western North America) show a slightly stronger seasonal dependence of the bias. NOTE: Dew point temperature is not available for ECCC.


ℹ️ If you want to know more#
Key resources#
Some key resources and further reading were linked throughout this assessment.
The CDS catalogue entries for the data used were:
Seasonal forecast monthly statistics on single levels: https://cds.climate.copernicus.eu/datasets/seasonal-monthly-single-levels?tab=overview
ERA5 monthly averaged data on single levels from 1940 to present: https://cds.climate.copernicus.eu/datasets/reanalysis-era5-single-levels-monthly-means?tab=overview
Code libraries used:
C3S EQC custom functions,
c3s_eqc_automatic_quality_control, prepared by B-Open
References#
[1] Rodriguez, D., De Voil, P., Hudson, D., Brown, J. N., Hayman, P., Marrou, H., & Meinke, H. (2018). Predicting optimum crop designs using crop models and seasonal climate forecasts. Scientific reports, 8(1), 2231.
[2] Jha, P. K., Athanasiadis, P., Gualdi, S., Trabucco, A., Mereu, V., Shelia, V., & Hoogenboom, G. (2019). Using daily data from seasonal forecasts in dynamic crop models for yield prediction: A case study for rice in Nepal’s Terai. Agricultural and forest meteorology, 265, 349-358.
[3] Dainelli, R., Calmanti, S., Pasqui, M., Rocchi, L., Di Giuseppe, E., Monotti, C., … & Toscano, P. (2022). Moving climate seasonal forecasts information from useful to usable for early within-season predictions of durum wheat yield. Climate Services, 28, 100324.
[4] Lledó, L., Torralba, V., Soret, A., Ramon, J., & Doblas-Reyes, F. J. (2019). Seasonal forecasts of wind power generation. Renewable Energy, 143, 91-100.
[5] Prodhomme, C., Materia, S., Ardilouze, C., White, R. H., Batté, L., Guemas, V., … & García-Serrano, J. (2021). Seasonal prediction of European summer heatwaves. Climate Dynamics, 1-18.
[6] Li, W., Chen, J. I. E., Li, L. U., Chen, H. U. A., Liu, B., Xu, C. Y., & Li, X. (2019). Evaluation and bias correction of S2S precipitation for hydrological extremes. Journal of Hydrometeorology, 20(9), 1887-1906.
[7] Manzanas, R. (2020). Assessment of model drifts in seasonal forecasting: Sensitivity to ensemble size and implications for bias correction. Journal of Advances in Modeling Earth Systems, 12(3), e2019MS001751.
[8] Hermanson, L., Ren, H. L., Vellinga, M., Dunstone, N. D., Hyder, P., Ineson, S., … & Williams, K. D. (2018). Different types of drifts in two seasonal forecast systems and their dependence on ENSO. Climate dynamics, 51, 1411-1426.
[9] Hemri, S., Bhend, J., Liniger, M. A., Manzanas, R., Siegert, S., Stephenson, D. B., … & Doblas-Reyes, F. J. (2020). How to create an operational multi-model of seasonal forecasts?. Climate Dynamics, 55, 1141-1157.
[10] Manzanas, R., Gutiérrez, J. M., Bhend, J., Hemri, S., Doblas-Reyes, F. J., Torralba, V., … & Brookshaw, A. (2019). Bias adjustment and ensemble recalibration methods for seasonal forecasting: a comprehensive intercomparison using the C3S dataset. Climate Dynamics, 53, 1287-1305.