

4.4. Assessing the impact of spatial scale and temporal trends on seasonal forecast quality#
Production date: 30.04.2025
Produced by: Johannes Langvatn (METNorway), Johanna Tjernström (METNorway)
🌍 Use case: Using seasonal forecasts for regional climate monitoring and prediction#
❓ Quality assessment question#
How does the quality of seasonal forecasts change when looking at different sized areas? What are the associated limitations?
How do long term temporal trends impact the quality of seasonal forecasts?
The effectiveness of seasonal forecasts in predicting the development of key climate variables—such as temperature, precipitation and sea surface temperatures (SSTs)—varies considerably by variable, region, season, lead time and the state of large-scale climate drivers like ENSO (El Niño–Southern Oscillation). This notebook investigates how a potential trend in the data (e.g. as discussed in Greuell et al. (2019) [1]) along with selection of regions at various spatial scales (e.g. as discussed in Prodhomme et al. (2021) [2], Gubler et al. (2020) [3] Quaglia et al. (2021) [4]) affect forecasting quality. For the purpose of this assessment, seasonal forecast quality is measured by the temporal correlation of the ensemble mean with ERA5 reanalysis.
📢 Quality assessment statement#
These are the key outcomes of this assessment
The forecast quality (ensemble mean correlation) of t2m varies depending on the selected spatial scale and the choice of the regions or locations.
There is a clear drop in forecast quality when moving from the global scale to continental scale (Europe), to a national scale (Germany), and finally to a city scale (Bonn).
This is not the case when comparing the global scale, to the Pacific and NINO region, where the forecast quality remains largely constant, or even better, the smaller the selected region.
The regional mean for NINO3.4 is better correlated to the reanalysis than the global mean.
The nearest grid cell to Bonn (an example city in Germany) has low correlation and most of the quality can be attributed to the underlying trend in the dataset.
In contrast, the nearest grid cell to Addis Ababa (an example city in Eastern Africa) has some correlation which is retained even after detrending.
For regions and locations which have a visible trend in t2m, the trend inflates the correlation of t2m compared to reanalysis.
For Europe, most of the visible correlation can be attributed to the underlying trend.
This contrasts with the region of greater horn of Africa, where less of the visible correlation can be attributed to the underlying trend.
Users are generally advised to avoid selecting small regions or single grid cells when using seasonal forecasts as they are only expected to be skillful in predicting large scale variations in monthly or seasonal deviations. Selecting larger regions based on a common climatology generally results in increased robustness and signal to noise.
📋 Methodology#
This notebook provides an assessment of the quality of seasonal monthly forecast temperature anomalies derived from the monthly means (https://cds.climate.copernicus.eu/datasets/seasonal-monthly-single-levels) through comparison with the ERA5 reanalysis (https://cds.climate.copernicus.eu/datasets/reanalysis-era5-single-levels-monthly-means). The hindcast anomalies are calculated from the monthly means as the anomalies catalogue entry only provides the real time forecasts. Data were accessed from the CDS.
Using this data the anomaly was calculated for the two meter temperature (t2m), against the period 1993-2024, and was detrended assuming a linear trend. Note that this period contains both hindcast and forecast, which are not entirely equivalent with respect to initialization, and contain 25 and 51 ensemble members respectively. A dataset was then generated containing both the original anomaly and the detrended. The analysis was then carried out globally and for three regions chosen based on effects of trend on the correlation.
First, the global case was considered both including and excluding trend, plotting anomaly for the ensemble members, ensemble mean, and ERA5. The correlation was also calculated.
To further consider the correlation, maps were generated to more clearly view the spatial variations of correlation in anomaly (as can seen on the C3S verification page) between the seasonal forecast and ERA5. Based on these maps, a set of regions were selected for further study, based on the magnitude of the correlation. Plots were then generated for nested domains. Three spatial scales were considered, a larger, continental scale, a smaller country scale and a much smaller city scale (a single grid box in the 1x1 degree grid). Data were selected for each domain based on a lat/lon box.
The resulting plots, displaying the ensemble members, ensemble mean, and ERA5, aim to visualise the variation in quality based on the selected regions of interest. This was also done for the detrended anomaly, and correlation was also calculated for each of the domains.
1. Choose data to use and setup code
Choose a selection of forecast systems and model versions, hindcast period (normally 1993-2016 to align with the C3S common hindcast period), forecast and leadtime months
Ensure that the ERA5 and Seasonal forecast data are regridded to the same grid by using the grid-keyword to the cdsapi.
Compute the anomaly of the forecast and reanalysis data
The data is detrended assuming a linear trend in the data from start year to end year
Both the original and detrended data is saved for the following analysis
2. Comparing global correlation
Compute the ensemble mean of the forecasted anomaly
Plot the correlation of forecast and reanalysis data, before and after performing the detrending
3. Map of correlation for detrended data
Correlation is plotted for each grid point on a map
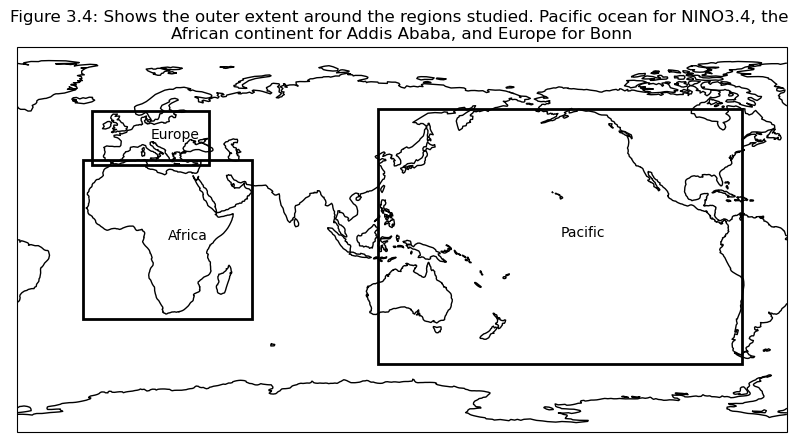
Based on this, regions are selected to investigate further; Addis Ababa, Bonn, NINO3.4
Plots are generated for the regions chosen in the previous section
Key limitations:
This assessment primarily considers the correlation between the ensemble mean and ERA5, while the full ensemble spread is visualized in some of the plots, the maps of correlation only use the ensemble mean.
The method used to detrend the data is very simple, and thus may impact the quality of the detrended data.
The usage of ERA5 as ground truth, while convenient, may be considered a limitation as it is a reanalysis and not observation.
The region plots use data at scales that may consider only one or a few grid cells, this is generally not a large enough domain to expect skillful prediction of large scale variations in monthly or seasonal deviations.
The assessment in this notebook only makes use of one forecasting system, considering one lead time. While the code should work for other models, and lead times this has not been shown explicitly in this assessment. Therefore, the results outlined here are specific to this forecasting system, period and lead time, further study would need to be conducted to see if the conclusions are general.
📈 Analysis and results#
1. Choose data to use and setup code#
This section contains the setup and data processing needed for performing the analysis.
Import external code libraries needed.
Define functions to be used throughout the notebook.
This notebook uses the t2m monthly means from one forecasting system, in this case from ECMWF (system code 51), for a forecast produced in May for leadtime months June, July and August. This was requested for both forecast and hindcast periods, thus there is a difference in the number of ensemble members before and after 2016.
2. Comparing global correlation#
Compute the ensemble mean of the seasonal forecast anomaly data.
Plot the original anomaly data for each ensemble member, the ensemble mean, and the reanalysis anomaly. Please note that the ensemble member points are coloured by number to highlight the switch from the hindcast configuration (25 members) to the forecasts (51 members).
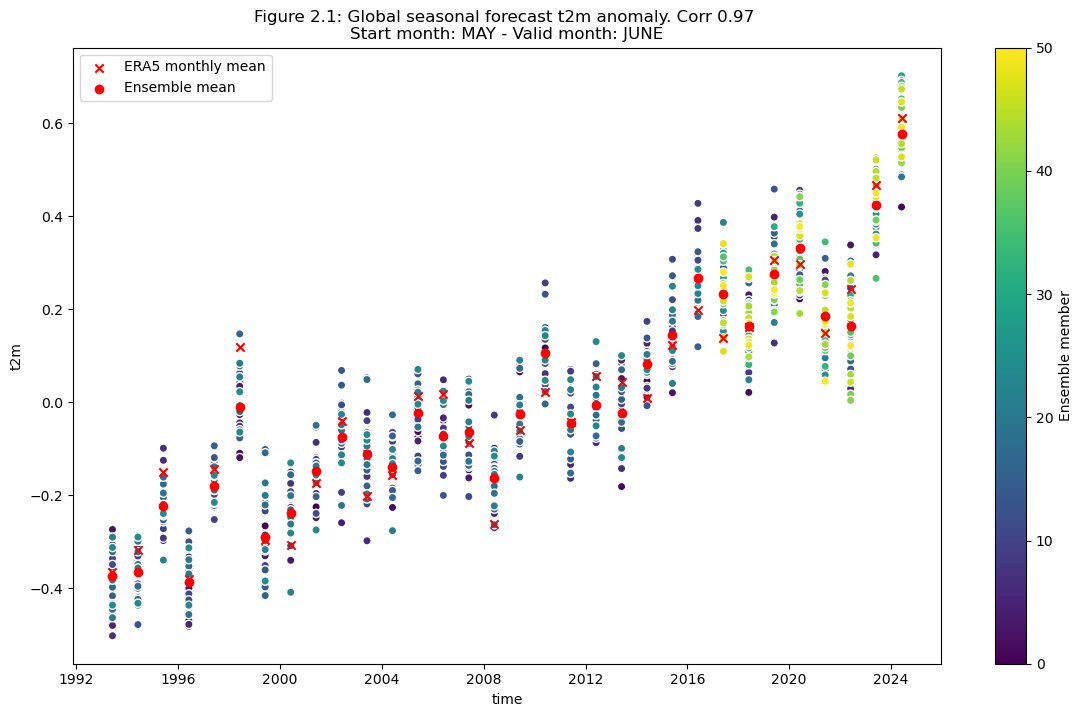
Plot after detrending#
Plot the detrended anomaly data for each ensemble member, the ensemble mean, and the reanalysis anomaly.
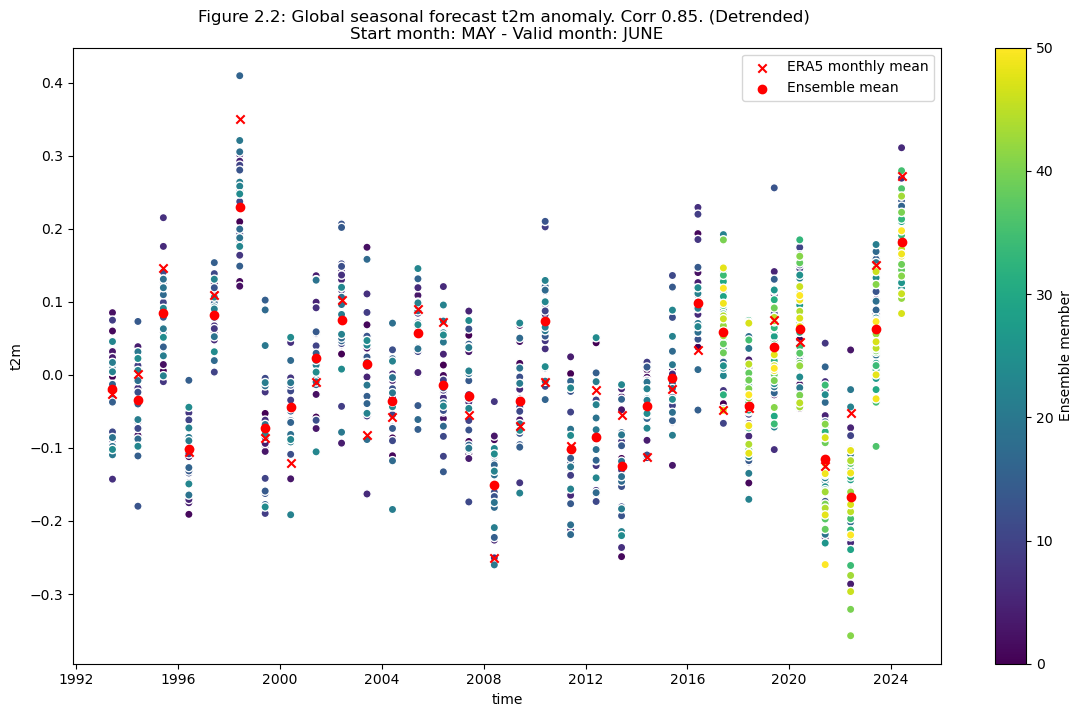
3. Map of correlation for detrended data#
The correlation of the detrended data is plotted compared to reanalysis data for each grid cell on a map.
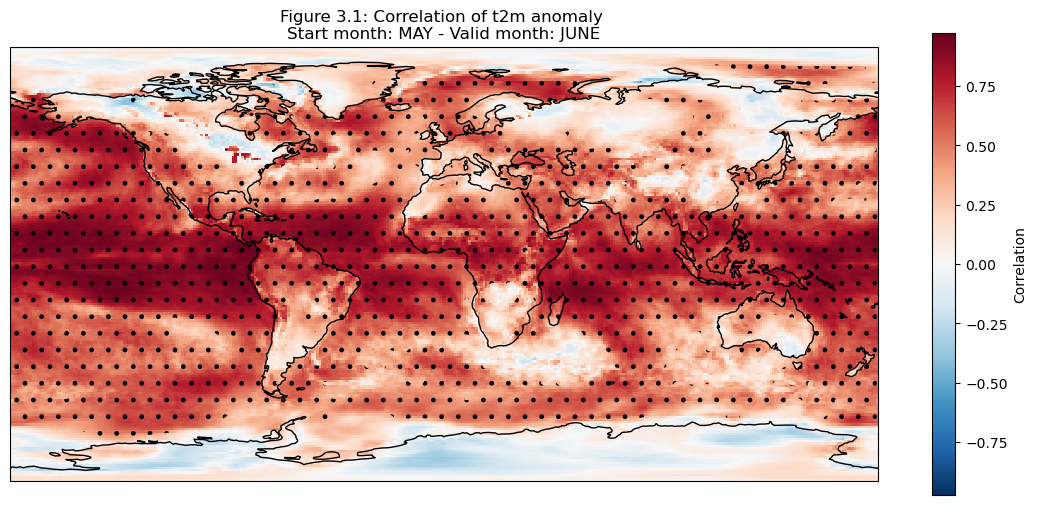
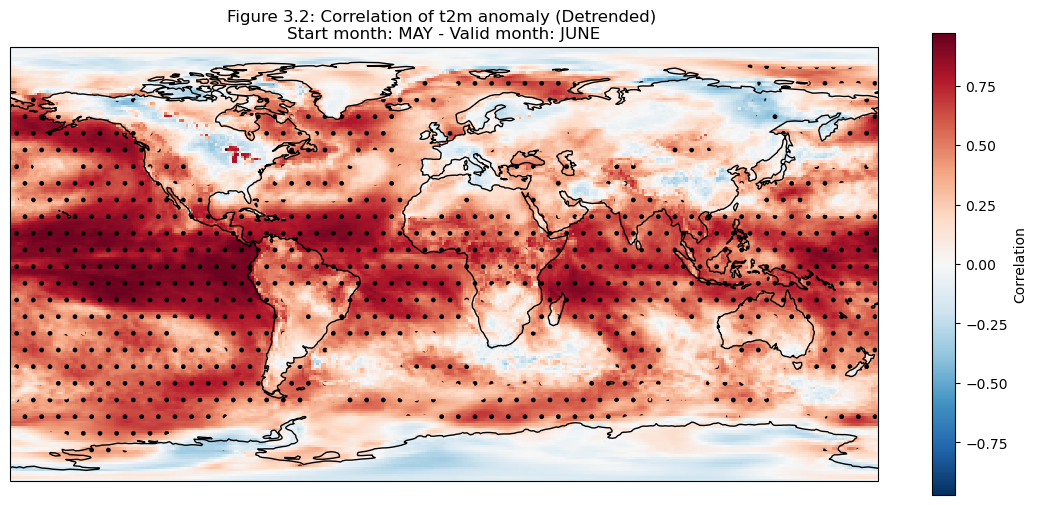
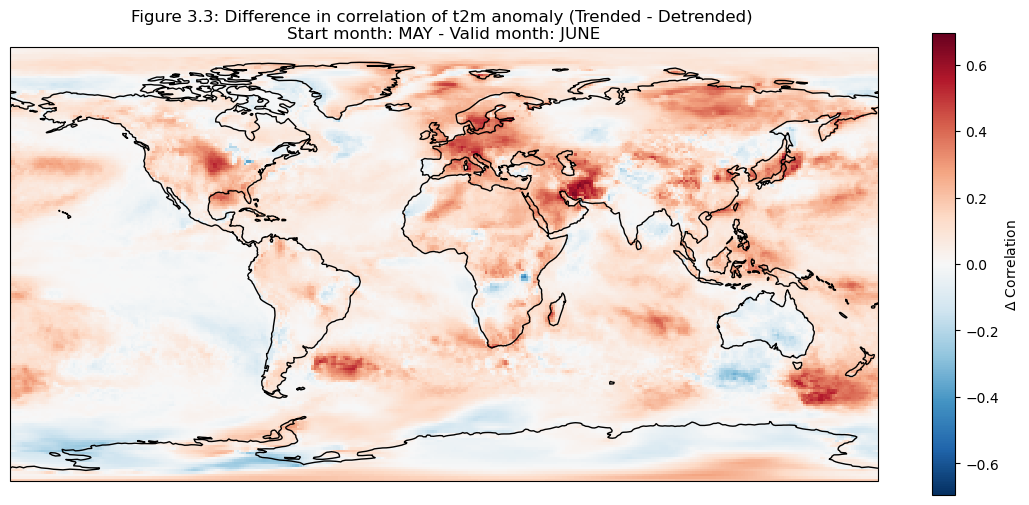
The hatched area is where the correlation exceeds the critical value.
It can be seen in the above plots that there is a high correlation over the North American Great Lakes. This is likely due to the fact that they are large enough that the heat retention impacts correlation skill at one month lead time.
Selecting regions#
Based on the correlation maps, regions are selected to investigate further; Addis Ababa, Bonn, NINO3.4.
4. Plot and describe results#
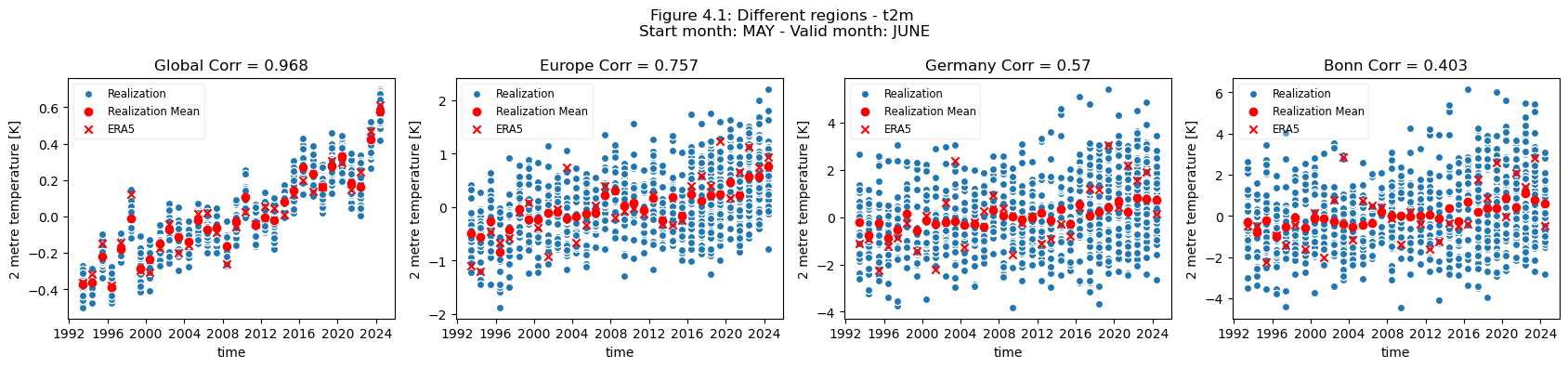
In this section the regional means are computed and plots generated to illustrate scale variations for the selected regions.
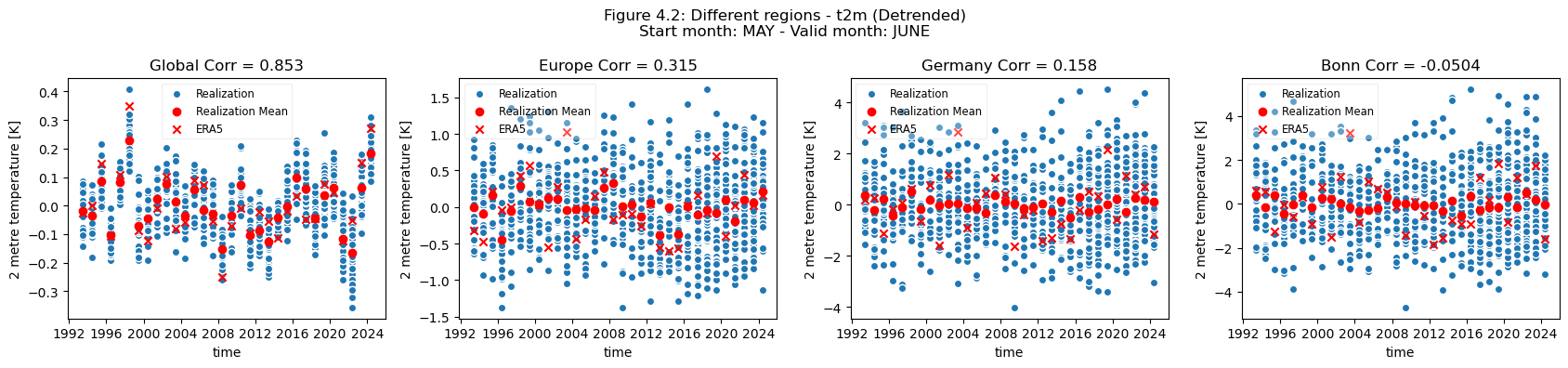
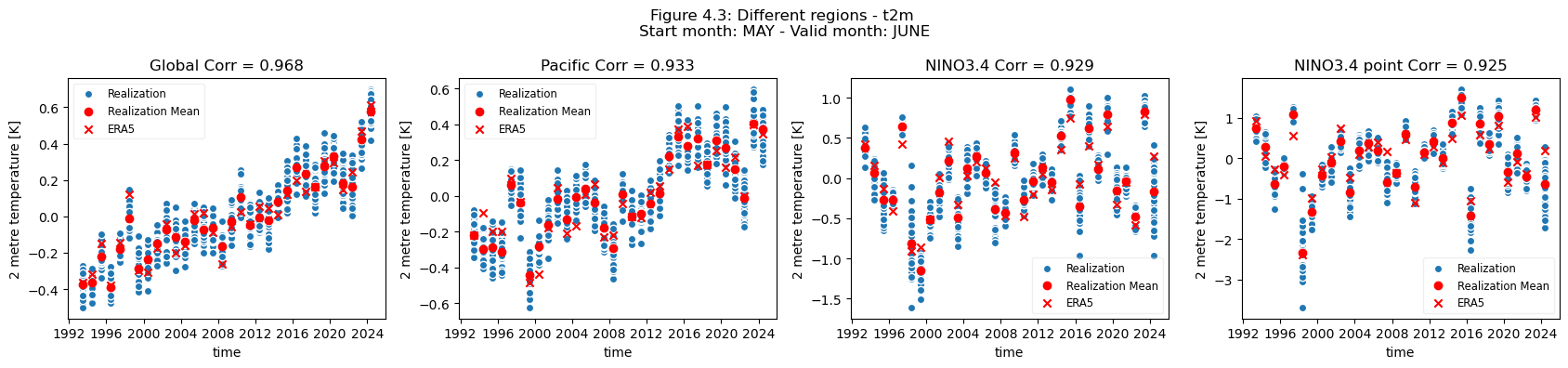
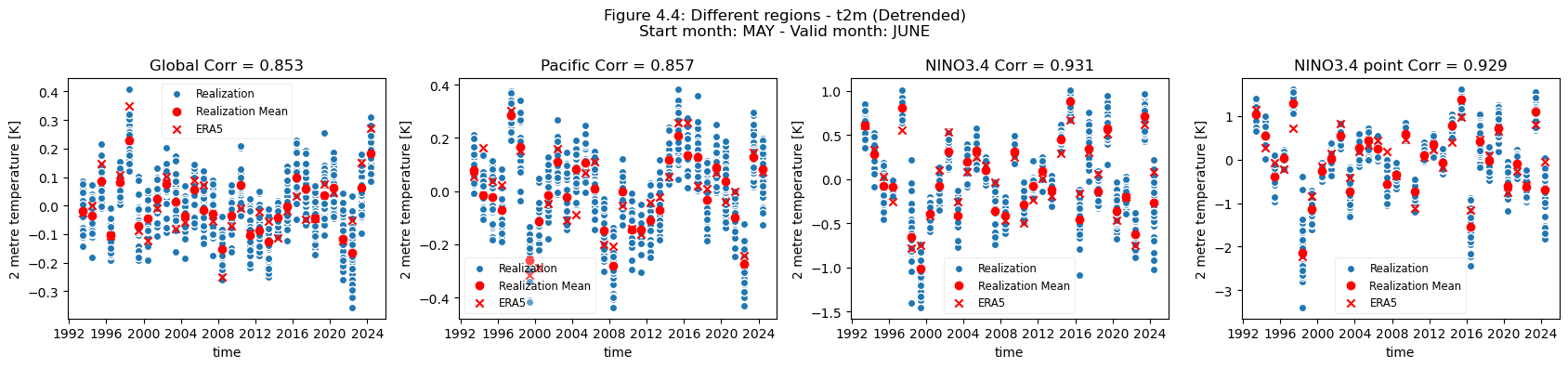
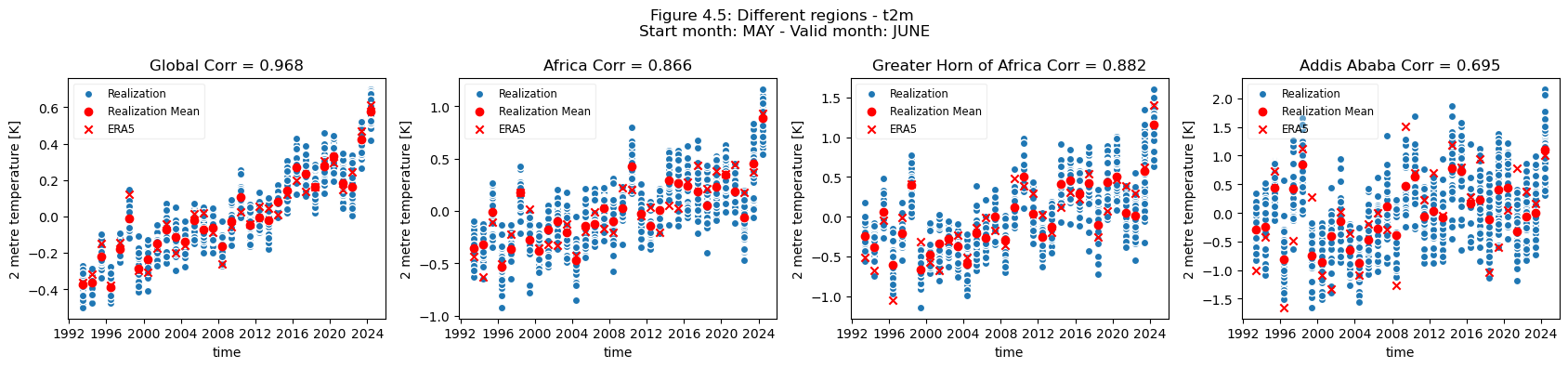
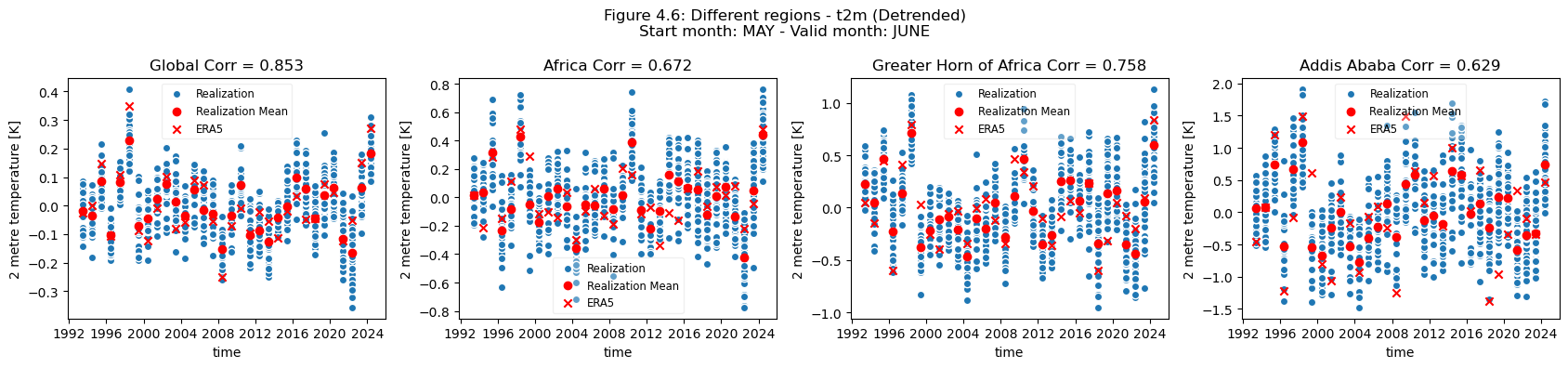
Discussion#
Looking at the comparison of different regions at different spatial scales a few conclusions can be drawn.
For regions with a visible trend, that trend inflates the correlation for t2m compared against analysis. This can be seen for Europe, where comparing the detrended and trended plots, the correlation is greater for the data with trend in Europe. Hence, for Europe, most of the visible correlation can be attributed to the underlying trend. This can be compared with the region of greater horn of Africa. Where comparing the trended and detrended case indicates that less of the visible correlation can be attributed to the underlying trend.
For the selected regions, forecast quality depending on scale varies. Looking at the Europe, Germany, Bonn case, there is a drop in forecast quality as the scale decreases. This cannot be observed in the NINO3.4 where the quality remains more or less constant, despite the decrease in region. The Greater Horn of Africa, where the drop off in quality with scale can be seen somewhat in the case of Addis Ababa, but not on the same scale as can be seen in the Europe case.
Considering this, and the anomalies for the different regions at different scales, it can be seen that the region of NINO3.4 has a better correlation with the reanalysis than the global regional mean, while Bonn has a low correlation where most of the quality can be attributed to the underlying trend. Addis Ababa has some correlation, which is retained even after detrending. The high correlations for the NINO3.4 region are partially dependent on the start date and forecast length, which can be seen in the SST indices plots on the C3S verification page), though it should be noted that these plots use sea surface temperature and not t2m. Forecast quality, and seasonal forecast biases, generally vary with start date and lead time, as seen in some of the other assessments.
ℹ️ If you want to know more#
Key resources#
Seasonal forecast monthly statistics on single levels: 10.24381/cds.68dd14c3
ERA5 monthly averaged data on single levels from 1940 to present: 10.24381/cds.f17050d7
Code libraries used:#
C3S EQC custom functions,
c3s_eqc_automatic_quality_control, prepared by B-Openxarray
numpy
matplotlib
cartopy
linear_model from sklearn
References#
[1] Greuell, W., Franssen, W. H. P., and Hutjes, R. W. A.: Seasonal streamflow forecasts for Europe – Part 2: Sources of skill, Hydrol. Earth Syst. Sci., 23, 371–391, https://doi.org/10.5194/hess-23-371-2019, 2019.
[2] Prodhomme, C., Materia, S., Ardilouze, C. et al. Seasonal prediction of European summer heatwaves. Clim Dyn 58, 2149–2166 (2022). https://doi.org/10.1007/s00382-021-05828-3
[3] Gubler, S., and Coauthors, 2020: Assessment of ECMWF SEAS5 Seasonal Forecast Performance over South America. Wea. Forecasting, 35, 561–584, https://doi.org/10.1175/WAF-D-19-0106.1
[4] Calì Quaglia, F., Terzago, S. & von Hardenberg, J. Temperature and precipitation seasonal forecasts over the Mediterranean region: added value compared to simple forecasting methods. Clim Dyn 58, 2167–2191 (2022). https://doi.org/10.1007/s00382-021-05895-6