

5.2.7. CORDEX biases in the SPEI6 drought index over the Mediterranean region#
Production date: 17-03-2026
Produced by: CMCC foundation - Euro-Mediterranean Center on Climate Change. Albert Martinez Boti and Lorenzo Sangelantoni.
🌍 Use case: Investigating drought indices to inform water management#
❓ Quality assessment question#
How well do CORDEX models simulate drought compared to signals derived from ERA5?
The Standardized Precipitation-Evapotranspiration Index (SPEI) [1] is a widely used drought indicator that integrates precipitation and potential evapotranspiration, providing a more complete measure of water deficits than precipitation alone. Its multiscalar formulation allows the evaluation of different types of drought [2], from short-term agricultural or soil moisture deficits to long-term hydrological or ecological events. Being standardised, SPEI is dimensionless, facilitating comparisons across regions and climates. By capturing variations in frequency, duration, and severity, it effectively reflects the complex nature of drought, making it a robust and physically meaningful proxy for drought assessment in the context of climate change [3].
Understanding SPEI is particularly relevant for the water management sector. By capturing multiple types of drought SPEI serves as a versatile indicator for various users. Climate projections using SPEI enable planners to anticipate future water deficits, guide allocation, and design effective strategies for reservoir management, irrigation, and drought preparedness, helping to reduce socio-economic and ecological impacts [4][5].
This assessment evaluates SPEI6 (six-month accumulation) across a subset of CORDEX models available through the Copernicus Climate Data Store (CDS). Model outputs are compared against SPEI6 derived from ERA5 reanalysis, which serves as the reference product. We specifically evaluate whether changes in the 1991–2010 period relative to the 1971–1990 baseline are accurately represented by CORDEX models and the trend across the whole 1971-2010 period for the Mediterranean domain.
This notebook is the counterpart to the assessment performed for CMIP6 (CMIP6 biases in the SPEI6 drought index over the Mediterranean region)
📢 Quality assessment statement#
These are the key outcomes of this assessment
The CORDEX ensemble median for the subset of models considered in this assessment does not generally capture the general intensification of drought over the Mediterranean observed in ERA5, showing SPEI6 changes close to zero for most regions.
Individual models exhibit highly diverse spatial patterns, with some closely resembling ERA5, underscoring the importance of taking into account the whole ensemble (and not only the ensemble mean) for planning purposes.
Despite these biases, the selected subset of CORDEX models may still be useful for exploring SPEI-based future water deficits and guiding drought preparedness, as long as limitations are considered.
Regions with high inter-model spread, such as North Africa, Turkey, and the eastern Mediterranean, may be associated with future higher uncertainty, suggesting that adaptation strategies in these areas should consider a wider range of possible futures.
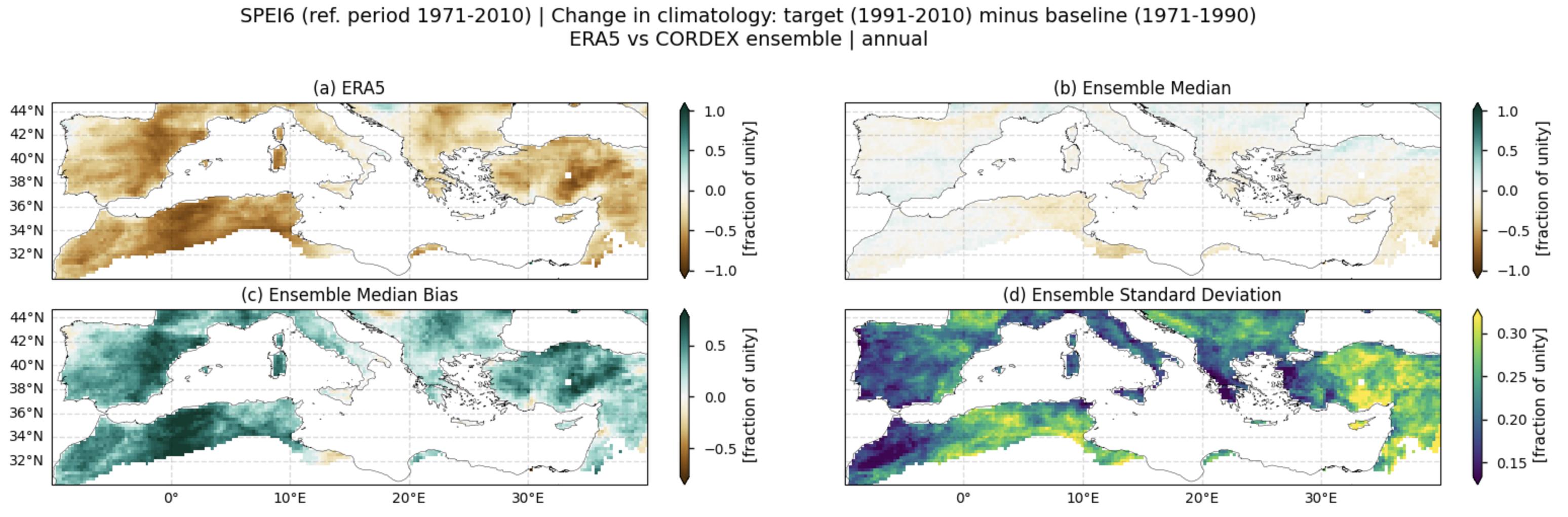
Fig. 5.2.7.1 Spatial patterns of SPEI6 change over the Mediterranean region. Panels show (a) ERA5 reference, (b) CORDEX ensemble median (median of the selected subset of models at each grid cell), (c) ensemble median bias relative to ERA5, and (d) ensemble spread (standard deviation across the selected models). SPEI6 is standardised over the reference period 1971–2010. SPEI6 change is calculated at each grid point as the difference between the monthly climatologies of the target period (1991–2010) and the baseline period (1971–1990), and then averaged to obtain the ANNUAL mean.#
📋 Methodology#
The Standardized Precipitation-Evapotranspiration Index accumulated to six months (SPEI6) has been calculated for this assessment — through the use of xclim — as a proxy to evaluate drought conditions for a subset of CORDEX models, which are evaluated against SPEI6 derived from ERA5 reanalysis. The study covers the Mediterranean domain, following IPCC-AR6 regional definitions [6], and results include spatial maps of SPEI6 changes for ERA5, CORDEX, and the biases of these changes. Additionally, time series showing the temporal evolution of drought across the domain are calculated, comparing trends from the models with ERA5 over the historical period considered within this assessment (1971–2010).
Potential evapotranspiration (PET) is calculated with the Hargreaves method [7], which requires only maximum and minimum temperature (and optionally mean temperature), providing a computationally efficient yet robust estimate (e.g., [8]). The accumulated series of precipitation minus PET is then standardised for the reference period, defined by the C3S Atlas (1971–2010).
Five key concepts are defined:
Reference period: The period used to standardise SPEI values, here 1971–2010, following the C3S Atlas.
Baseline period: The period against which changes are calculated, here 1971–1990.
Target period: The period for which changes are evaluated, here 1991–2010.
Historical period: The entire period considered in this assessment, here 1971–2010.
SPEI6 change: Differences in SPEI6 between the target period and the baseline, representing anomalies in drought conditions.
The analysis and results follow the next outline:
1. Parameters, requests and functions definition
This notebook follows the same methodology as the assessment performed for CMIP6 ( CMIP6 biases in the SPEI6 drought index over the Mediterranean region). The historical period considered here is slightly shorter (1971–2010) compared to 1961–2020 in the CMIP6 assessment. This choice helps to avoid memory overload, ensures efficient execution of the notebook, guarantees availability of CORDEX models for the historical period, and avoids including many years of scenario data (CORDEX historical runs only extend until 2005).
📈 Analysis and results#
1. Parameters, requests and functions definition#
1.1. Import packages#
1.2. Define Parameters#
In the “Define Parameters” section, various customisable options for the notebook are specified:
The historical period can be adjusted by modifying
historical_slice; the default range is 1971-2010.The reference period can be adjusted by modifying
reference_slice; the default range is 1971–2010, following the C3S Atlas.The baseline period can be adjusted by modifying
baseline_slice; the default range is 1971-1990.The target period can be adjusted by modifying
target_slice; the default range is 1991-2010.The
interpolation_methodparameter allows selecting the interpolation method when regridding is performed.collection_idis not customisable for this assessment and is set to ‘CORDEX’.The
areaparameter specifies the geographical domain of interest. By default, the Mediterranean domain is used, following IPCC-AR6 regional definitions [6]The
time_aggallows selecting the time aggregation for the analysis. Options include: annual, DJF, MAM, JJA, SON, Jan, Feb, Mar, Apr, May, Jun, Jul, Aug, Sep, Oct, Nov, Dec.SPEI accumulation window (
window): Defines the accumulation period in months for the SPEI calculation. Common options include 3, 6, or 12 months, depending on whether short-term or long-term droughts are of interest. In this assessment, a six-month accumulation is used.The
chunksselection allows the user to define if dividing into chunks when downloading the data on their local machine. Although it does not significantly affect the analysis, it is recommended to keep the default value for optimal performance.
1.3. Define models#
The following climate analyses are performed using a subset of CORDEX models that provide both the historical and RCP8.5 experiments, as well as maximum, minimum and mean temperature and precipitation, within the Climate Data Store (CDS). All Global Climate Models (GCMs) driving the selected CORDEX simulations were included, and the selection ensures a representative coverage of the available Regional Climate Models (RCMs). A total of 17 models were chosen to maintain consistency with the number used in the quality assessment CMIP6 biases in the SPEI6 drought index over the Mediterranean region.
1.4. Define ERA5 request#
Within this notebook, ERA5 serves as the reference product. In this section, we set the required parameters for the cds-api data-request of ERA5.
1.5. Define model requests#
In this section we set the required parameters for the cds-api data-request.
1.6. Functions to cache#
In this section, functions that will be executed in the caching phase are defined. Caching is the process of storing copies of files in a temporary storage location, so that they can be accessed more quickly. This process also checks if the user has already downloaded a file, avoiding redundant downloads.
Description of the main functions:
compute_spei_cordex: Uses the xclim package to calculate the Standardized Precipitation-Evapotranspiration Index (SPEI). Thereference_sliceargument specifies the reference period used for standardization, while thewindowargument defines the number of months over which precipitation and evapotranspiration are accumulated (6 months in this assessment).get_mask_below_03: Generates a mask identifying grid points where precipitation is below 0.3 mm/day, allowing filtering of extremely dry regions.
2. Downloading and processing#
2.1. Download and transform ERA5#
In this section, the download.download_and_transform function from the ‘c3s_eqc_automatic_quality_control’ package is used to retrieve ERA5 hourly reference data, resample it to daily frequency, compute daily potential evapotranspiration, calculate the daily water balance, and derive the SPEI (SPEI6 for this assessment). Results are cached to avoid redundant downloads and repeated processing.
2.2. Download and transform models#
In this section, the download.download_and_transform function from the ‘c3s_eqc_automatic_quality_control’ package is used to download daily data from CORDEX models, compute daily potential evapotranspiration, calculate the daily water balance, and derive the SPEI (SPEI6 for this assessment). SPEI6 is computed on each model’s native grid and also on the ERA5 grid to enable bias assessment. When regridding is required, it is performed for each essential climate variable before the index calculation to preserve standardisation. Results are cached to avoid redundant downloads and repeated processing.
model='cccma_canesm2_clmcom_clm_cclm4_8_17'
model='cccma_canesm2_gerics_remo2015'
model='cnrm_cerfacs_cm5_ipsl_wrf381p'
model='cnrm_cerfacs_cm5_smhi_rca4'
model='ichec_ec_earth_dmi_hirham5'
model='ichec_ec_earth_knmi_racmo22e'
model='ipsl_cm5a_mr_ipsl_wrf381p'
model='ipsl_cm5a_mr_knmi_racmo22e'
model='miroc_miroc5_clmcom_clm_cclm4_8_17'
model='miroc_miroc5_gerics_remo2015'
model='mohc_hadgem2_es_cnrm_aladin63'
model='mohc_hadgem2_es_mohc_hadrem3_ga7_05'
model='mpi_m_mpi_esm_lr_mpi_csc_remo2009'
model='mpi_m_mpi_esm_lr_cnrm_aladin63'
model='ncc_noresm1_m_dmi_hirham5'
model='ncc_noresm1_m_mohc_hadrem3_ga7_05'
model='ncc_noresm1_m_smhi_rca4'
2.3. Apply land-sea mask and change some attributes#
This section changes some attributes and applies a land–sea mask to all models, as well as to ERA5. A bare-earth (barrean) mask is also applied to ensure meaningful results in arid regions, as in the C3S atlas. In particular, we follow the methodology available in their Github repository. While their implementation of the mask also considers factors such as snow depth and vegetation cover, here we only apply the filter based on annual mean precipitation for 1971–2010 being less than 0.3 mm day⁻¹. This simplification is justified because, in the region under consideration, the bare-earth mask obtained with the full set of filters closely matches the one derived from the precipitation threshold alone.
Note: ds_interpolated contains data from the models regridded to the ERA5 grid. model_datasets contain the same data on the original grid of each model. Regridding is performed for every essential climate variable prior to the index calculation in order to avoid compromising standardisation.
100%|██████████| 1/1 [00:00<00:00, 22.34it/s]
3. Plot and describe results#
This section will display the following results:
SPEI6 change maps comparing ERA5 and the ensemble median (defined as the median of the change values for the selected subset of models at each grid cell). The layout includes ERA5, the ensemble median, the ensemble median bias, and the ensemble spread (calculated as the standard deviation of the change across the selected subset of models).
SPEI6 change maps for each individual model.
Bias maps of the SPEI6 change for each model.
Time series of SPEI6 change (averaged over the Mediterranean region).
Note: SPEI6 change is calculated at each grid point as the arithmetic difference between climatologies in the target period (1991–2010) and the baseline period (1971–1990).
3.1. Define plotting functions#
The functions presented here are used to calculate SPEI6 changes and generate corresponding layout plots. Three types of layout can be displayed, depending on the plotting function:
Reference and ensemble summary: Includes the ERA5 reference product, the ensemble median, the bias of the ensemble median, and the ensemble spread. This is generated using
plot_ensemble().Individual models: Displays all models individually using
plot_models().Model biases: Displays the bias of each model relative to the reference, also using
plot_models().
Calculation of SPEI6 change:
compute_spei_change()calculates SPEI6 change at each grid point as the arithmetic difference between monthly climatologies of the target period (1991–2010) and the baseline period (1971–1990). It then aggregates the change according to the user-specifiedtime_aggin Section 1.2.compute_change_4timeseries()computes SPEI6 anomalies relative to the baseline climatology for each month of the timeseries and aggregates them according to thetime_aggparameter. This provides monthly, seasonal, or annual-level information depending on the user’s selection.
3.2. Plot ensemble maps#
In this section, we invoke the plot_ensemble() function to visualise the SPEI6 change for the following: (a) the reference ERA5 product, (b) the ensemble median (defined as the median of the change values for the selected subset of models at each grid cell), (c) the bias of the ensemble median, and (d) the ensemble spread (calculated as the standard deviation of the change across the selected subset of models).
ANNUAL aggregation
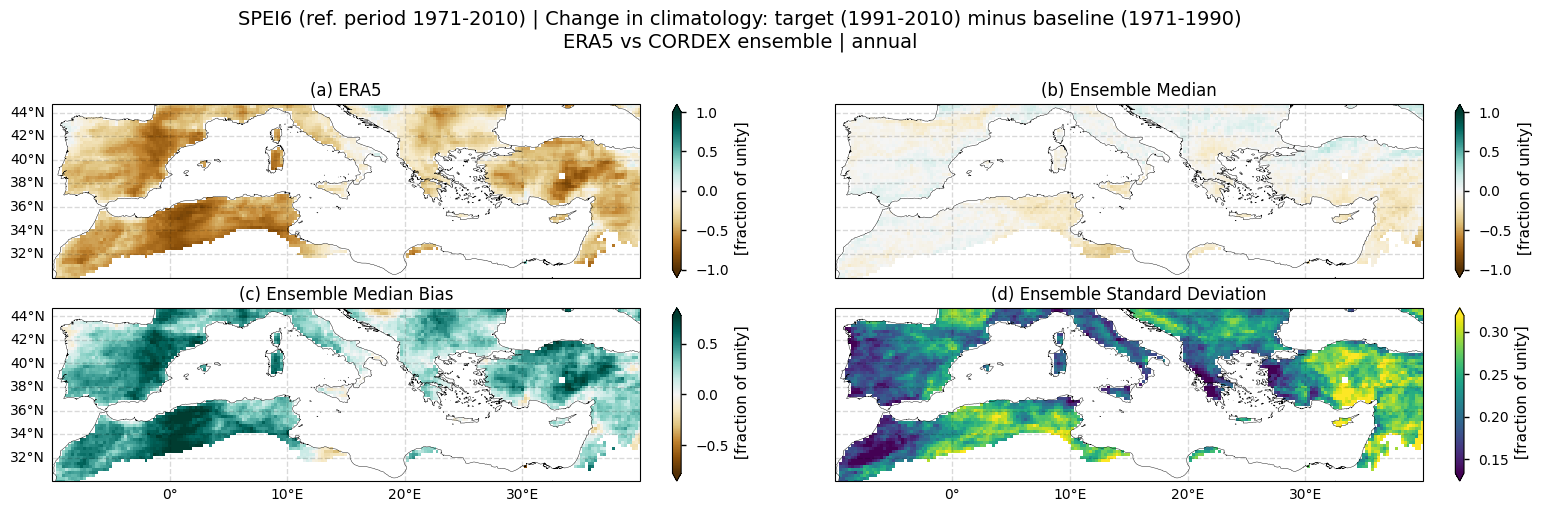
Fig 1. Spatial patterns of SPEI6 change over the Mediterranean region. Panels show (a) ERA5 reference, (b) CORDEX ensemble median (median of the selected subset of models at each grid cell), (c) ensemble median bias relative to ERA5, and (d) ensemble spread (standard deviation across the selected models). SPEI6 is standardised over the reference period 1971–2010. SPEI6 change is calculated at each grid point as the difference between the monthly climatologies of the target period (1991–2010) and the baseline period (1971–1990), and then averaged to obtain the ANNUAL mean.
The regridding artefacts visible in panel (d) result from the use of a conservative regridding method, which is commonly recommended when dealing with precipitation. They typically arise from large values in specific models and differences among the models’ native grids.
3.3. Plot ensemble maps - Seasonal aggregations#
Same as 3.2 section but for: DJF, MAM, JJA and SON
WINTER (DJF)
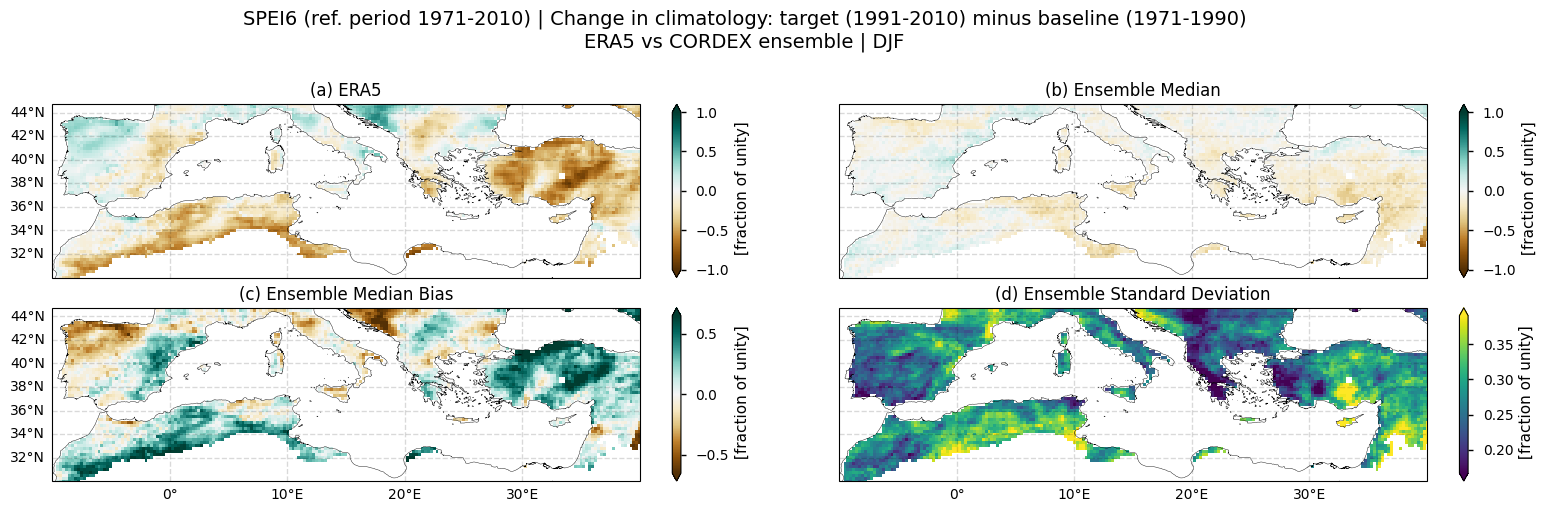
Fig 2. Spatial patterns of SPEI6 change over the Mediterranean region. Panels show (a) ERA5 reference, (b) CORDEX ensemble median (median of the selected subset of models at each grid cell), (c) ensemble median bias relative to ERA5, and (d) ensemble spread (standard deviation across the selected models). SPEI6 is standardised over the reference period 1971–2010. SPEI6 change is calculated at each grid point as the difference between the monthly climatologies of the target period (1991–2010) and the baseline period (1971–1990), and then averaged across the winter to obtain the DJF mean.
SPRING (MAM)
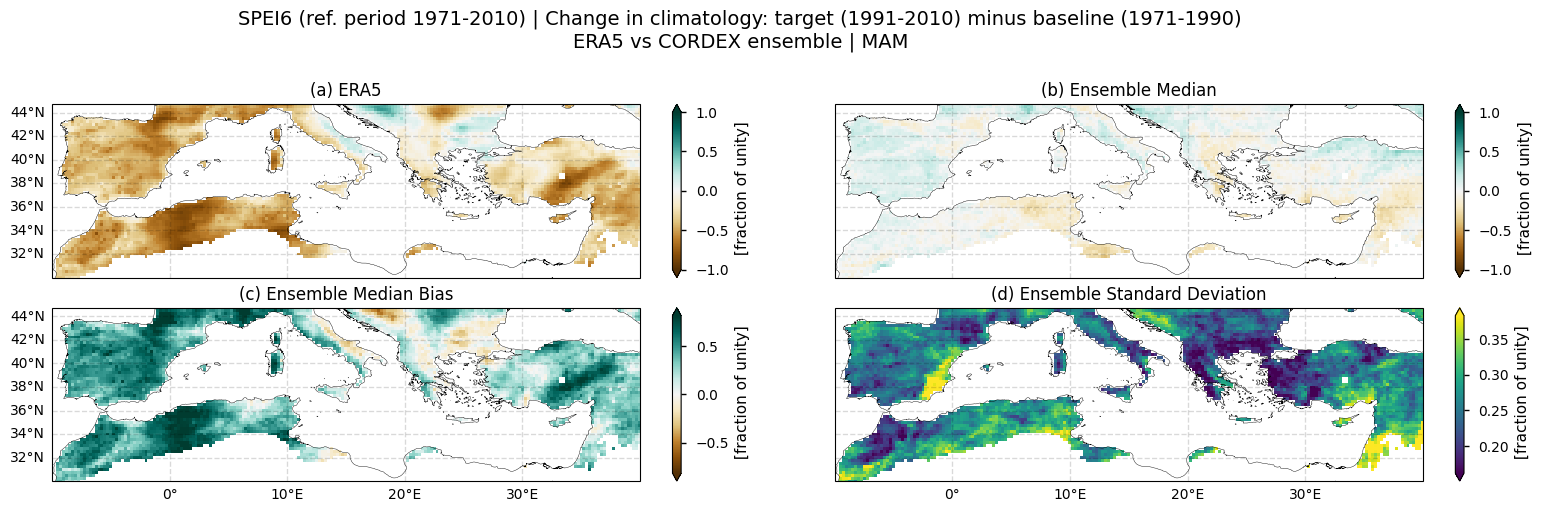
Fig 3. Spatial patterns of SPEI6 change over the Mediterranean region. Panels show (a) ERA5 reference, (b) CORDEX ensemble median (median of the selected subset of models at each grid cell), (c) ensemble median bias relative to ERA5, and (d) ensemble spread (standard deviation across the selected models). SPEI6 is standardised over the reference period 1971–2010. SPEI6 change is calculated at each grid point as the difference between the monthly climatologies of the target period (1991–2010) and the baseline period (1971–1990), and then averaged across the spring to obtain the MAM mean.
SUMMER (JJA)
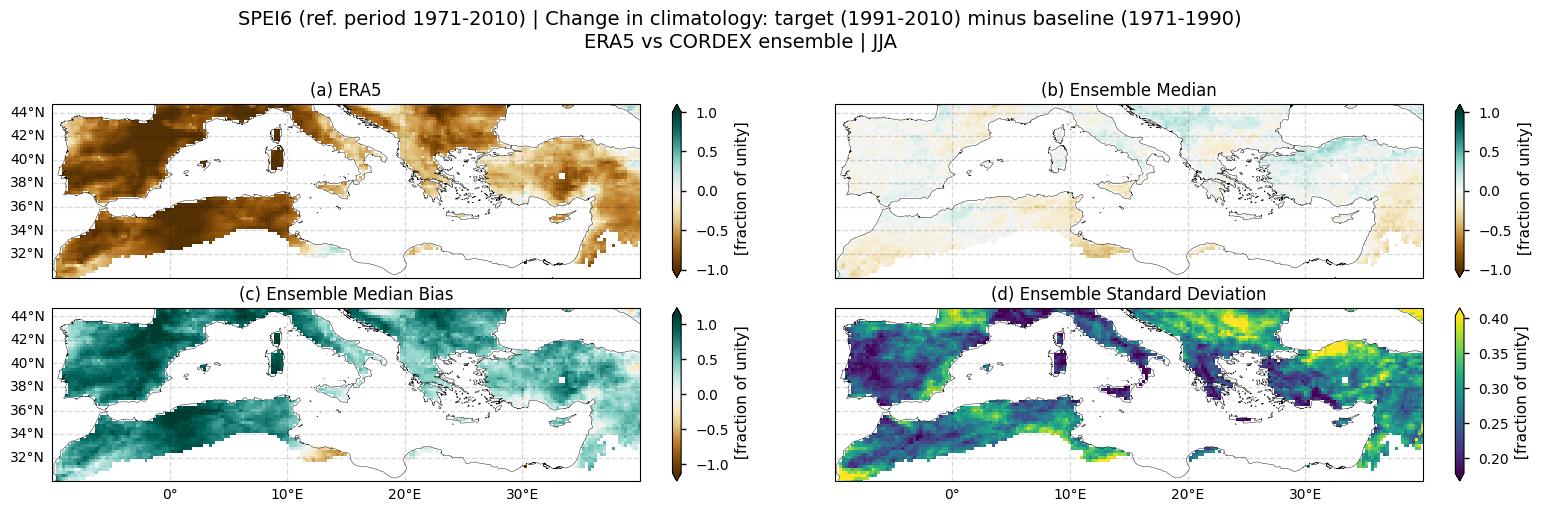
Fig 4. Spatial patterns of SPEI6 change over the Mediterranean region. Panels show (a) ERA5 reference, (b) CORDEX ensemble median (median of the selected subset of models at each grid cell), (c) ensemble median bias relative to ERA5, and (d) ensemble spread (standard deviation across the selected models). SPEI6 is standardised over the reference period 1971–2010. SPEI6 change is calculated at each grid point as the difference between the monthly climatologies of the target period (1991–2010) and the baseline period (1971–1990), and then averaged across the summer to obtain the JJA mean.
AUTUMN (SON)
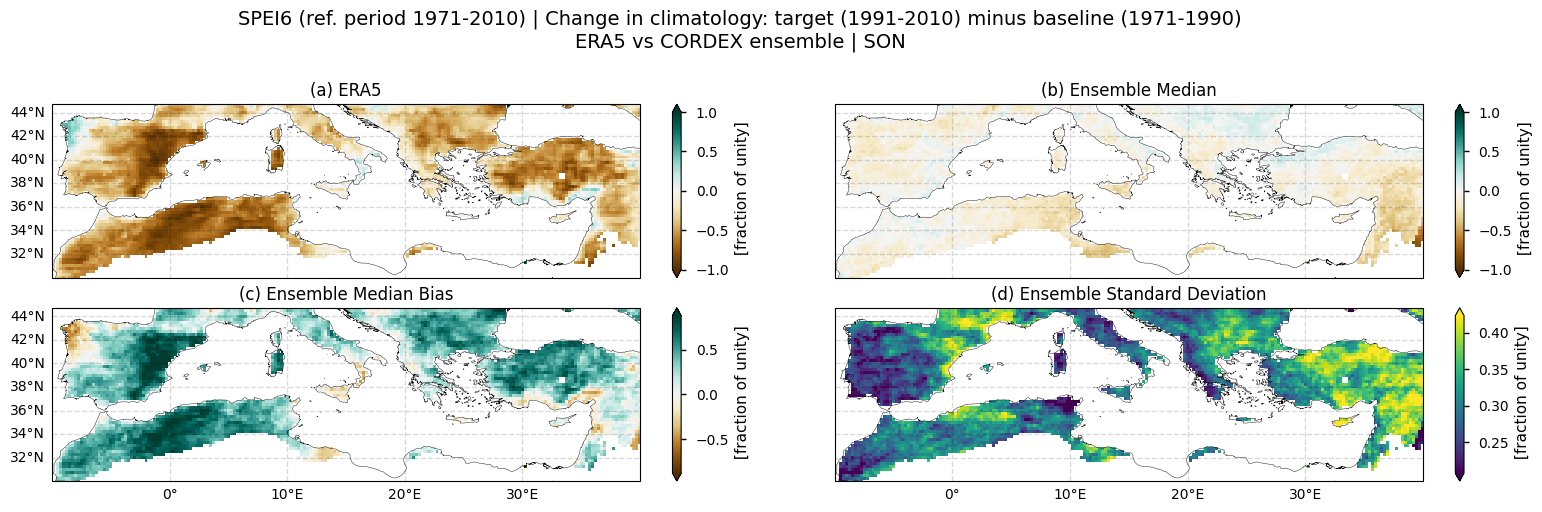
Fig 5. Spatial patterns of SPEI6 change over the Mediterranean region. Panels show (a) ERA5 reference, (b) CORDEX ensemble median (median of the selected subset of models at each grid cell), (c) ensemble median bias relative to ERA5, and (d) ensemble spread (standard deviation across the selected models). SPEI6 is standardised over the reference period 1971–2010. SPEI6 change is calculated at each grid point as the difference between the monthly climatologies of the target period (1991–2010) and the baseline period (1971–1990), and then averaged across the autumn to obtain the SON mean.
3.4. Plot model maps#
In this section, we invoke the plot_models() function to visualise the SPEI6 change of every model individually. Note that the model data used in this section maintains its original grid. Only the annual mean is shown here.
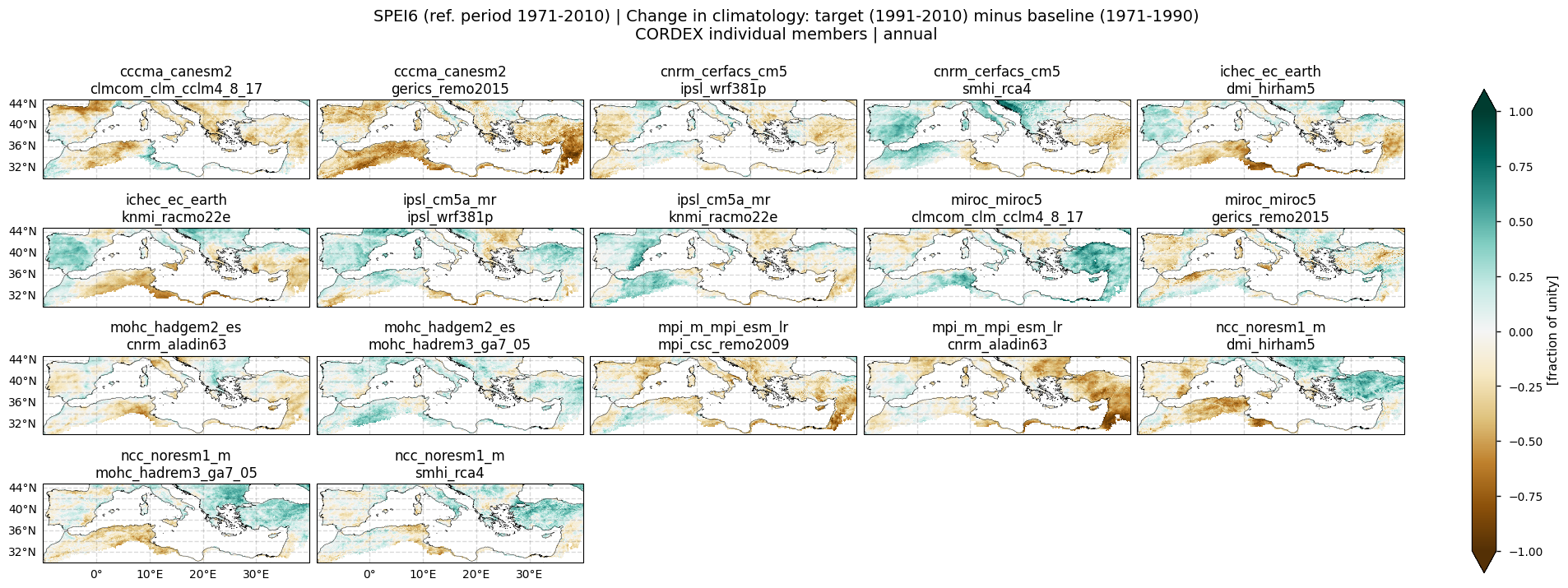
Fig 6. Spatial patterns of SPEI6 change for each individual CORDEX model over the Mediterranean region. SPEI6 is standardised over the reference period 1971–2010. For each model, SPEI6 change is calculated at each grid point as the difference between the monthly climatologies of the target period (1991–2010) and the baseline period (1971–1990), and then averaged to obtain the annual mean.
3.5. Plot bias maps#
In this section, we invoke the plot_models() function to visualise the bias of the SPEI6 change for every model individually. Note that the model data used in this section has previously been interpolated to the ERA5 grid. Regridding is performed for each essential climate variable before the index calculation to preserve standardisation. Only the annual mean is shown here.
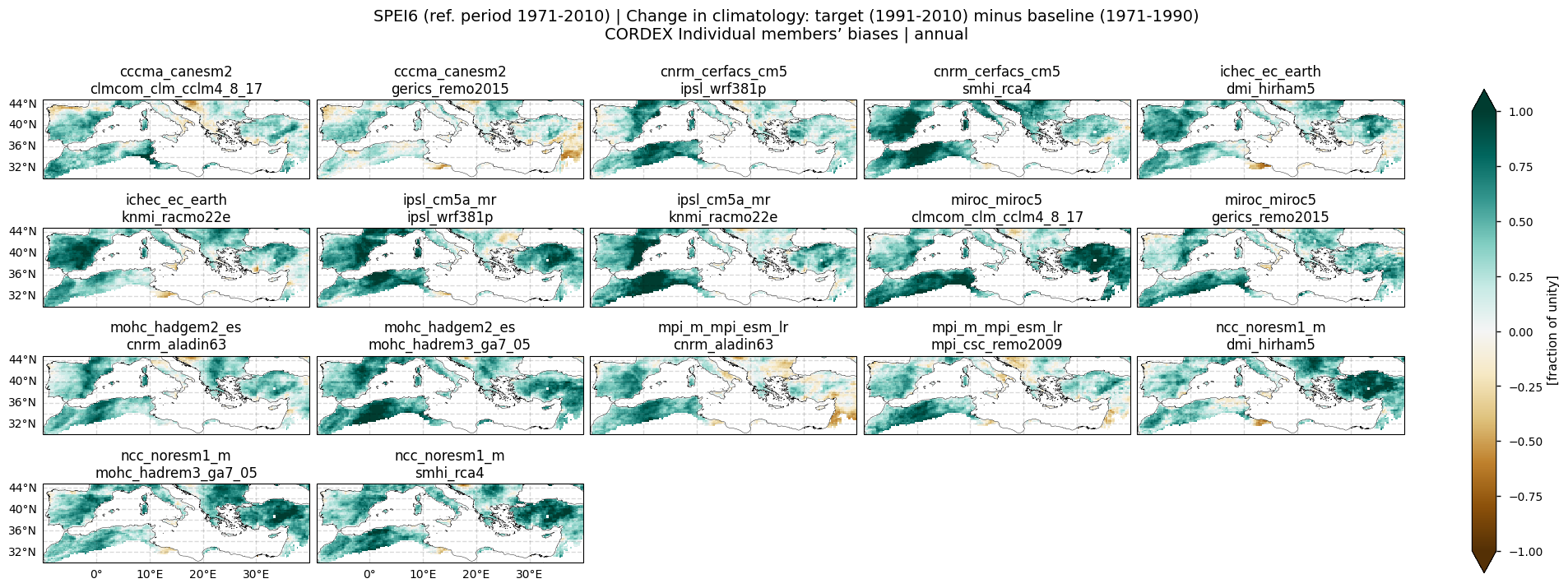
Fig 7. Bias of SPEI6 change for each individual CORDEX model relative to ERA5 over the Mediterranean region. SPEI6 is standardised over the reference period 1971–2010. For each model and ERA5, SPEI6 change is calculated at each grid point as the difference between the monthly climatologies of the target period (1991–2010) and the baseline period (1971–1990), and then averaged to obtain the annual mean.
3.6. Timeseries#
This section shows the timeseries of SPEI6 anomalies relative to the baseline climatology. We first use compute_change_4timeseries(), which calculates SPEI6 anomalies for each month of the timeseries (relative to the baseline monthly climatologies) and aggregates them according to the time_agg parameter. Spatially averaged values are then obtained. Light blue shading highlights the baseline period, while light orange shading marks the target period. The analysis compares the CORDEX ensemble median, ERA5, and individual models, displaying trends for both ERA5 and the ensemble median. Additionally, it shows the ensemble spread and the slope values of the trends for ERA5 and the CORDEX ensemble median. Only the annual aggregation is shown here.
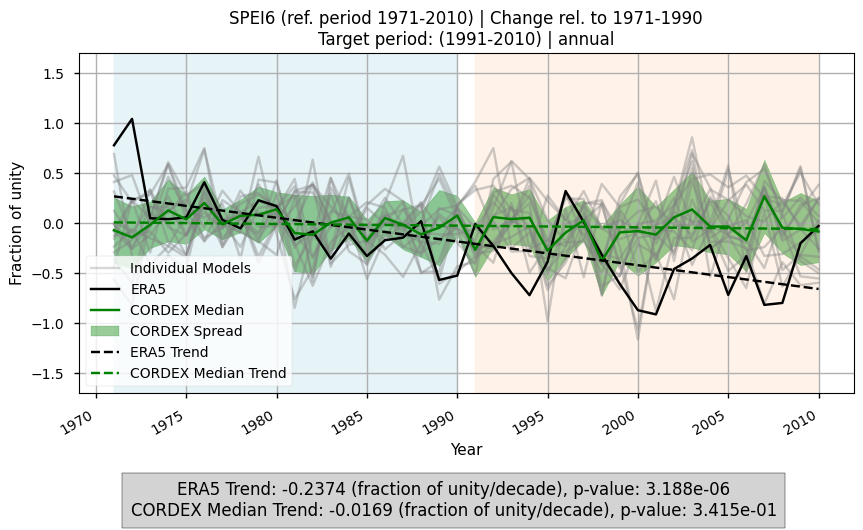
Fig 8. Timeseries of SPEI6 anomalies over the Mediterranean region. Monthly anomalies are calculated relative to the monthly baseline climatologies, aggregated according to the specified timescale, and then spatially averaged over the region. Light blue shading indicates the baseline period, and light orange shading indicates the target period. The figure compares ERA5, the CORDEX ensemble median, and individual models, showing trends for ERA5 and the ensemble median, as well as the ensemble spread and slope values of the trends.
3.7. Results summary#
ERA5 indicates a general intensification of drought conditions over the Mediterranean region when comparing the baseline (1971–1990) and target (1991–2010) periods.
The CORDEX ensemble median (obtained from the subset of models considered within this notebook) of the SPEI6 change is generally close to zero (Fig. 1). However, the inter-model spread is high, and is particularly pronounced over the Iberian Peninsula, southern France, North Africa, the Balkans region, and the easternmost Mediterranean areas (including Turkey, Lebanon, and Syria). In fact, the spatial pattern of the SPEI6 change is pretty different depending on the considered model (Fig. 6 and 7).
Seasonal analysis (Figs. 2–5) indicates that, in ERA5, drought intensification is strongest in summer. Spring and autumn also show notable decreases in SPEI6, although localised increases partly offset the spatial mean, especially in spring. In winter, the sign of the SPEI6 change is region-dependent, with large decreases over the eastern Iberian Peninsula, the eastern Mediterranean, and North Africa, and increases over the western Iberian Peninsula, as well as parts of Italy and the Balkans. Considering the CORDEX ensemble median, SPEI6 changes remain close to zero for most seasons and regions, with no clear spatial patterns overall, or at least none consistent with those observed in ERA5.
The timeseries of spatial means over the Mediterranean confirms an increase in drought conditions during the considered historical period in ERA5, with a trend of –0.24 (Fig. 8). For the ensemble median of CORDEX, the timeseries shows a trend close to zero, which is also not statistically significant. The timeseries plot also shows a high inter-model spread. Timeseries for seasonal aggregations are not shown here, but have been computed offline and exhibit behaviour similar to the annual case.
The results obtained in this notebook differ from those reported in the quality assessment named CMIP6 biases in the SPEI6 drought index over the Mediterranean region, where CMIP6 ensemble median captured the sign of the SPEI6 change for a similar historical period, although with an underestimation compared to ERA5.
The limited change in SPEI6 simulated by some CORDEX models, compared to ERA5 and the previous CMIP6-based counterpart assessment, may partly reflect methodological and structural factors. In particular, the shorter analysis periods used here (20-year blocks instead of 30) may reduce the robustness of the signal. In addition, many CORDEX RCMs do not include time-evolving aerosols, which can lead to an underestimation of temperature trends in some regions and consequently affect drought-related indices such as SPEI6 [9].
3.8. Implications for the users#
The pronounced inter-model spread over North Africa, Turkey, and the eastern Mediterranean implies that users in these regions may face higher future uncertainty. This highlights the need to stress-test adaptation strategies against a wide range of plausible futures rather than relying on a single scenario.
Although the ensemble median does not capture the SPEI6 change signal for the historical period, this does not necessarily imply that the models are not suitable for investigating future changes, as the spatial pattern of change depends on the individual model considered and model biases are not necessarily stationary, but may evolve under changing climate conditions [10].
The approach used in this notebook illustrates how a subset of GCM–RCM combinations can be selected while maintaining representation of all driving GCMs. This can be useful in situations where computational or practical constraints limit the use of the full ensemble. However, the results also reinforce that broader ensembles provide a more robust basis for assessing uncertainty.
Finally, users should be aware that results may vary depending on the choice of historical periods and model configurations. In this context, complementary tools such as the C3S Atlas, which includes a larger ensemble and alternative period definitions, can provide additional context for interpreting these findings. In addition, this notebook helps users understand the basis of the SPEI index and its methodological assumptions, supporting its application in operational water management and drought preparedness.
ℹ️ If you want to know more#
Key resources#
Some key resources and further reading were linked throughout this assessment.
The CDS catalogue entries for the data used were:
CORDEX regional climate model data on single levels (daily - Maximum 2m temperature in the last 24 hours, Minimum 2m temperature in the last 24 hours, 2m air temperature and Mean precipitation flux): https://cds.climate.copernicus.eu/datasets/projections-cordex-domains-single-levels?tab=overview
ERA5 hourly data on single levels from 1940 to present (2m temperature and total precipitation): https://cds.climate.copernicus.eu/datasets/reanalysis-era5-pressure-levels-monthly-means?tab=overview
Code libraries used:
C3S EQC custom functions,
c3s_eqc_automatic_quality_control, prepared by B-Open
References#
[1] Vicente-Serrano, S. M., Beguerı́a, S., and López-Moreno, J. I., 2010. A multiscalar drought index sensitive to global warming: The standardized precipitation evapotranspiration index, Journal of Climate, 23, 1696–1718. https://doi.org/10.1175/2009JCLI2909.1
[2] Wilhite, D. A., 2000. Droughts as a natural hazard: concepts and definitions. In: DROUGHT, A Global Assessment, vol. I and II, Routledge Hazards and Disasters Series, Routledge.
[3] Vicente-Serrano, S. M., Beguerı́a, S., Lorenzo-Lacruz, J., Camarero, J. J., López-Moreno, J. I., Azorin-Molina, C., Revuelto, J., Morán-Tejeda, E., and Sanchez-Lorenzo, A., 2012. Performance of drought indices for ecological, agricultural, and hydrological applications, Earth Interactions, 16, https://doi.org/10.1175/2012EI000434.1
[4] Kalisoras, A., Georgoulias, A. K., Akritidis, D., and Zanis, P., 2025. Future Projections in Agricultural Drought Characteristics for Greece Under Different Climate Change Scenarios. Environmental and Earth Sciences Proceedings, 35(1), 29. https://doi.org/10.3390/eesp2025035029
[5] Spinoni, J., Barbosa, P., Bucchignani, E., Cassano, J., Cavazos, T., Cescatti, A., Christensen, J. H., Christensen, O. B., Coppola, E., Evans, J. P., Forzieri, G., Geyer, B., Giorgi, F., Jacob, D., Katzfey, J., Koenigk, T., Laprise, R., Lennard, C. J., Kurnaz, M. L., … Dosio, A., 2021. Global exposure of population and land-use to meteorological droughts under different warming levels and SSPs: A CORDEX-based study. International Journal of Climatology, 41(15), 6825–6853. https://doi.org/10.1002/joc.7302
[6] Iturbide, M., Gutiérrez, J. M., Alves, L. M., Bedia, J., Cerezo-Mota, R., Cimadevilla, E., Cofiño, A. S., Di Luca, A., Faria, S. H., Gorodetskaya, I. V., Hauser, M., Herrera, S., Hennessy, K., Hewitt, H. T., Jones, R. G., Krakovska, S., Manzanas, R., Martínez-Castro, D., Narisma, G. T., Nurhati, I. S., Pinto, I., Seneviratne, S. I., van den Hurk, B., and Vera, C. S., 2020. An update of IPCC climate reference regions for subcontinental analysis of climate model data: definition and aggregated datasets, Earth Syst. Sci. Data, 12, 2959–2970, https://doi.org/10.5194/essd-12-2959-2020
[7] Hargreaves, G. H., and Samani, Z. A., 1985. Reference crop evapotranspiration from temperature, Applied engineering in agriculture, pp. 96–99. https://doi.org/10.13031/2013.26773
[8] Beguerı́a, S., Vicente-Serrano, S. M., Reig, F., and Latorre, B., 2014. Standardized precipitation evapotranspiration index (spei) revisited: Parameter fitting, evapotranspiration models, tools, datasets and drought monitoring, International Journal of Climatology, 34, 3001–3023. https://doi.org/10.1002/joc.3887
[9] Schumacher, D.L., Singh, J., Hauser, M., et al., 2024. Exacerbated summer European warming not captured by climate models neglecting long-term aerosol changes. Commun Earth Environ 5, 182. https://doi.org/10.1038/s43247-024-01332-8
[10] Schmith, T., Thejll, P., Berg, P., Boberg, F., Christensen, O. B., Christiansen, B., Christensen, J. H., Madsen, M. S., and Steger, C., 2021. Identifying robust bias adjustment methods for European extreme precipitation in a multi-model pseudo-reality setting, Hydrol. Earth Syst. Sci., 25, 273–290, https://doi.org/10.5194/hess-25-273-2021