

1.5.3. Satellite-Derived Monitoring of Summer LSWT in Lake Superior#
Production date: 15-05-2026
Produced by: Victor Couplet (VUB) & Camila Trigoso (VUB)
🌍 Use case: Monitoring summer surface water temperature variability and long-term trend in Lake Superior.#
❓ Quality assessment question(s)#
Can the C3S satellite lake surface water temperature dataset accurately reproduce summer LSWT observations in Lake Superior, and is it suitable for assessing long-term summer temperature variability and trends?
Cases of an increasing trend in lake surface water temperature (LSWT) have been observed in numerous lakes across various regions, including the United States, Europe, and other parts of the world [1] [2]. For example, Austin and Colman (2008) found that summer LSWT in Lake Superior increased at a rate of (11±6)×10-2 °C/year from 1979 to 2006. They attributed this trend to the earlier retreat of winter ice, which causes the positive overturning period to begin sooner, allowing the lake more time to warm. Their analysis was based on measurements from in-situ buoys [3]. Later, the Great Lakes Integrated Sciences and Assessments (GLISA) analyzed the annual mean LSWT of Lake Superior between 1995 and 2021. The increasing long-term trend observed by Austin and Colman was not apparent in the period analyzed by GLISA. However, they noted a shift to higher temperatures after 1998 [4]. The LSWT data analyzed by GLISA was derived from satellite observations and obtained through the NOAA Great Lakes CoastWatch [5]. Cannon et al. (2024) investigated summer LSWT of Lake Superior using simulation data over a longer time interval (1980-2021), and found a warming trend of (5.2±3.1)×10-2 °C/year [6].
The objective of this assessment is to evaluate whether the satellite-lake-water-temperature dataset from the Climate Data Store (CDS) is suitable for climate change monitoring, using Lake Superior as a case study. We calculated the trend summer LWST for a period of 28 years, from 1995 to 2023, and validated the data and trend computation against in-situ buoy measurements from the NOAA National Buoy Data Center (NBDC) [7].
📢 Quality assessment statement#
These are the key outcomes of this assessment
Lake Superior’s summer LSWT trend over 1995–2023, derived from the C3S satellite lake water temperature dataset, is small and not statistically significant. This indicates that no robust long-term warming or cooling signal can be detected over this period.
The C3S dataset shows good agreement with NOAA in situ buoy observations at selected locations. Differences in summer mean temperatures are partly attributable to the higher temporal sampling of in situ measurements and to differences in measurement depth, with satellites observing skin temperature and buoys measuring subsurface temperature (≈1 m). Additional discrepancies may result from cloud contamination in the satellite record, as well as from limitations in the in situ data, which may include temporal gaps, quality issues, and measurement inconsistencies.
The dataset is well suited for monitoring interannual variability in lake surface temperature; however, trend analyses require caution. The lack of statistical significance in the estimated trends, combined with strong interannual variability (e.g., elevated temperatures during the 1998 El Niño event), limits the ability to detect long-term changes over this period. Incorporating longer time series, including pre-1995 observations where available, would improve the robustness of trend assessments.
📋 Methodology#
The analysis and results are organized in the following steps, which are detailed in the sections below:
Satellite lake surface water temperature (LSWT) data are downloaded for the summer months (July–September) over the period 1995–2023.
The dataset is filtered based on quality flags and lake identification to retain only high-quality observations for Lake Superior.
A spatially weighted mean LSWT is computed, followed by the calculation of annual summer mean LSWT values.
The temporal trend is estimated using the Theil–Sen estimator, and its statistical significance is assessed with the Mann–Kendall test.
4. Comparison with NOAA buoy data
Satellite LSWT data are validated against in-situ measurements from three NOAA-NBDC buoys located in Lake Superior.
Performance metrics, including mean bias, mean absolute error (MAE), and root mean square error (RMSE), are calculated.
Buoy observations are resampled to match the less frequent satellite overpass times. Metrics are then recalculated on these time-matched datasets to determine whether differences in summer means arise from sampling frequency or from measurement characteristics (e.g., sensing depth, retrieval uncertainties).
Finally, LSWT trends derived from buoy data over multiple periods are computed and compared with satellite-based trends and published literature results.
📈 Analysis and results#
1. Request and download data#
Import packages#
Set variables#
Set the data request#
Download data#
100%|██████████| 29/29 [00:06<00:00, 4.25it/s]
2. Data preprocessing#
We download satellite lake surface temperature data and visualize the water masses over the region spanning 46.30–49.00°N latitude and 92.10–84.80°W longitude. In the dataset, Lake Superior is identified by ID number 2. The locations of the three NOAA buoys used for data comparison are also plotted.
Plot lakeid#
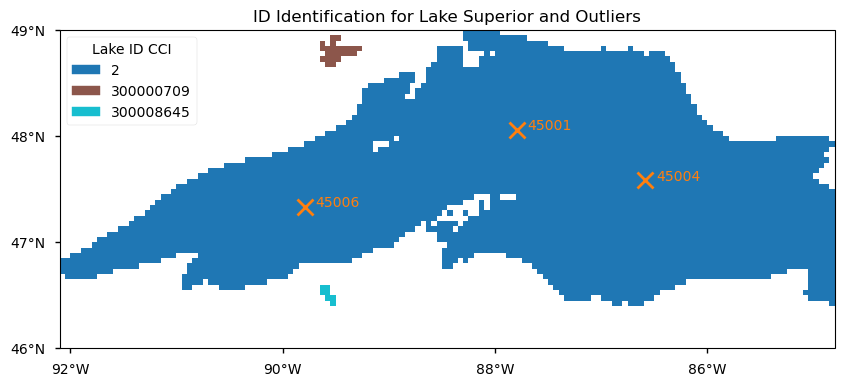
Figure 1 : Lake Superior identification in the dataset. Locations of the three NOAA-NBDC buoys used for data comparison are shown as orange crosses.
Data filtering#
Only observations with quality levels 4 (good) and 5 (best) are retained for analysis.
3. Summer mean analysis#
For each time step, lake surface water temperatures are averaged spatially across Lake Superior, and these values are then averaged over the summer months (July–September). The 1995–2023 trend is estimated using the Theil–Sen estimator, and its statistical significance is assessed with the Mann–Kendall test.
Summer mean#
Trend estimation#
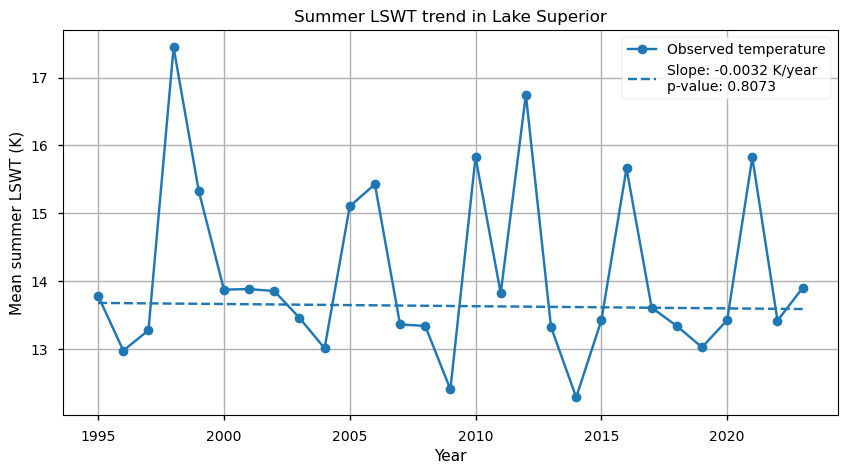
Figure 2 : Mean summer LSWT for Lake Superior between 1995 and 2023, and trend estimation.
The trend line in Figure 2 shows a slight negative slope of −0.0032 °C yr⁻¹. However, the p-value of 0.81 is well above the common significance threshold of 0.05, indicating that the trend is not statistically significant. This lack of significance may partly reflect the relatively short 28-year period analyzed, as longer time series are typically required to detect meaningful climate trends in large lakes.
At first glance, the absence of a significant warming trend may seem surprising. Previous work [3] reported a significant increase in summer temperatures from 1979 to 2006, and it seems unlikely that summer lake surface temperatures have stabilised since then, given ongoing global warming.
To verify these results, we will compare the satellite data with in-situ buoy measurements.
4. Comparison with NOAA buoy data#
The satellite data are compared with in-situ measurements from three NOAA NDBC buoys in Lake Superior [7]. These are the same buoys used in [3], which reported a significant increase in summer temperatures from 1979 to 2006. In-situ data are now available through 2024. The goal of this section is thus to compare satellite and buoy data over 1995–2023 and evaluate whether similar trends are observed in the buoy measurements.
The buoy data are downloaded from the NOAA National Data Buoy Center website [7], which provides data by station and year. We developed a Python script that automatically downloads the data for buoys 45001, 45004, and 45006 for all available years between 1979 and 2024, and combines them into a single, unified dataset.
Overall progress: 34%|███▍ | 47/138 [00:34<01:21, 1.12it/s, station=45004, year=1980]
→ download error: 404 Client Error: Not Found for url: https://www.ndbc.noaa.gov/data/historical/stdmet/45004h1979.txt.gz
Overall progress: 67%|██████▋ | 93/138 [01:09<00:46, 1.03s/it, station=45006, year=1980]
→ download error: 404 Client Error: Not Found for url: https://www.ndbc.noaa.gov/data/historical/stdmet/45006h1979.txt.gz
Overall progress: 68%|██████▊ | 94/138 [01:09<00:34, 1.26it/s, station=45006, year=1981]
→ download error: 404 Client Error: Not Found for url: https://www.ndbc.noaa.gov/data/historical/stdmet/45006h1980.txt.gz
Overall progress: 100%|██████████| 138/138 [01:42<00:00, 1.34it/s, station=45006, year=2024]
Total rows loaded: 958592
Although NOAA National Data Buoy Center (NDBC) buoy observations provide an important independent reference for evaluating satellite-derived LSWT, they should not be treated as error-free ground truth. NDBC applies both real-time automated quality control and delayed/manual quality control to its observations. According to the NDBC Handbook of Automated Data Quality Control Checks and Procedures [8], automated checks are used to detect issues such as transmission errors, missing data, total sensor failure, range-limit exceedances, and unrealistic temporal changes. Observations may be flagged as good, suspect, failed, or missing, and some failed observations are not released in real time. Manual quality control can also be applied after data are stored, including manual failure of data from sensors judged to be unreliable.
Therefore, discrepancies between satellite and buoy LSWT should not automatically be interpreted as satellite retrieval errors. They may also reflect limitations in the in situ record, including temporal gaps, sensor problems, incomplete quality control, or unrealistic variability.
The buoy data are averaged over the summer months, and each buoy is compared to the summer mean temperature of the nearest satellite pixel corresponding to its location (see Figure 3).
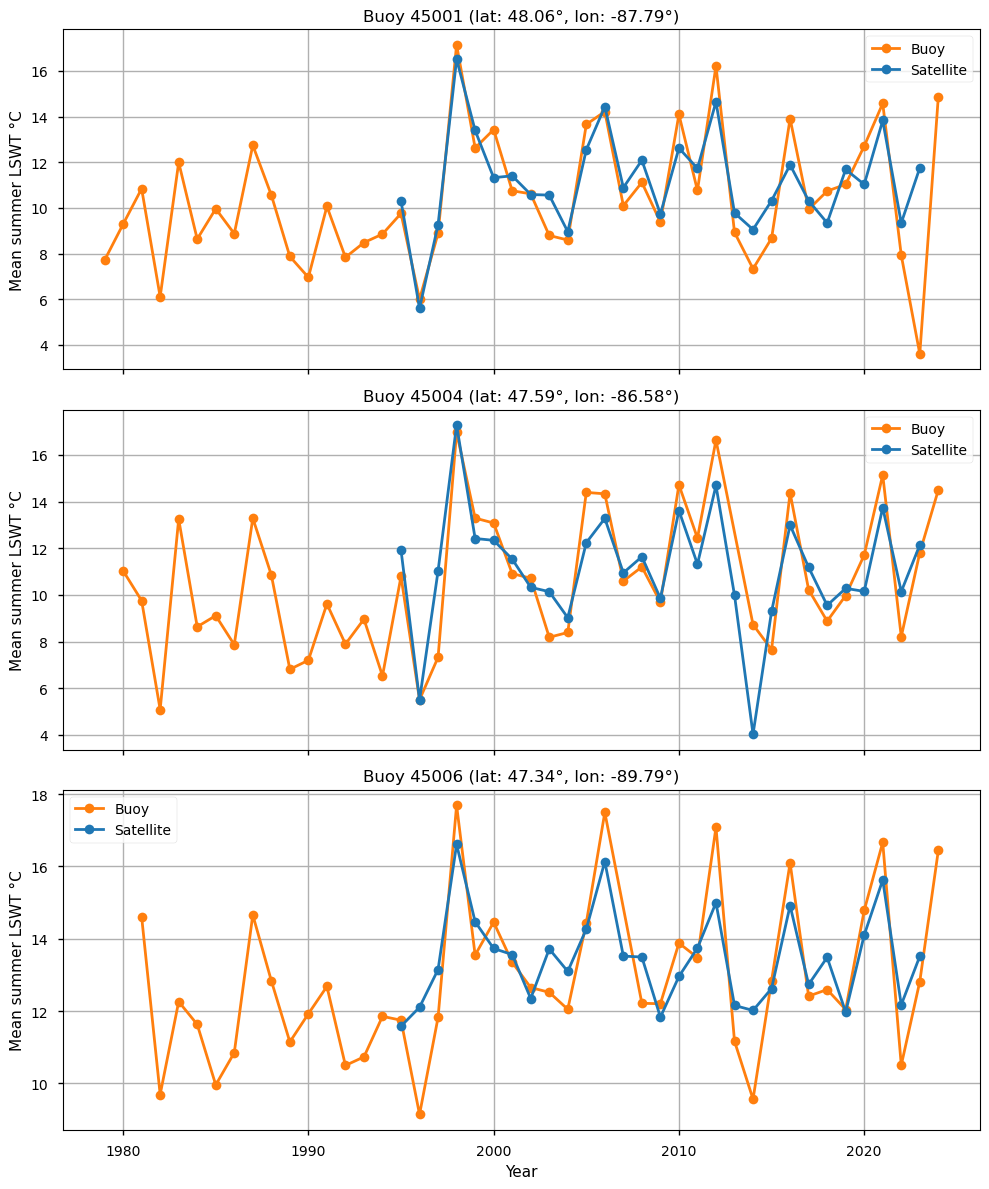
Figure 3: Mean summer LSWT for three Lake Superior buoys, compared to the mean summer LSWT from satellite data at the nearest pixel locations.
We observe that the satellite data are generally close to the buoy measurements; for instance, the 1998 peak in summer LSWT is well captured. To further quantify the differences between satellite and buoy data, we compute the mean bias, mean absolute error (MAE), and root mean square error (RMSE).
| station | n_samples | bias | MAE | RMSE | |
|---|---|---|---|---|---|
| 0 | 45001 | 29 | 0.32 | 1.23 | 1.88 |
| 1 | 45004 | 28 | -0.12 | 1.20 | 1.58 |
| 2 | 45006 | 28 | 0.21 | 0.95 | 1.18 |
| 3 | ALL | 85 | 0.14 | 1.13 | 1.58 |
Overall, the satellite data exhibit a small warm bias of 0.14 °C. However, the MAE and RMSE are relatively large, at 1.13 °C and 1.58 °C, respectively. A likely source of error is the difference in sampling frequency: the satellite dataset provides roughly one measurement per day, whereas the buoys record about 30 measurements per day. In addition, some days are missing in the satellite data, possibly due to cloud cover. To explore this further, we focus on summer 2016 for buoy 45001 (see Figure 4).
We observe that only two satellite observations are available between late July and mid-August, a particularly warm period, whereas the buoy provides continuous coverage throughout the three summer months (Figure 4, top pannel). This limited satellite data availability likely contributes to the satellite-derived mean summer LSWT being approximately 2 °C lower than the buoy-based mean. Indeed, when restricting the buoy data to the 31 measurements closest in time to the 31 satellite observations during summer 2016, the resulting mean LSWT is very similar to the satellite-derived value (Figure 4, bottom pannel).
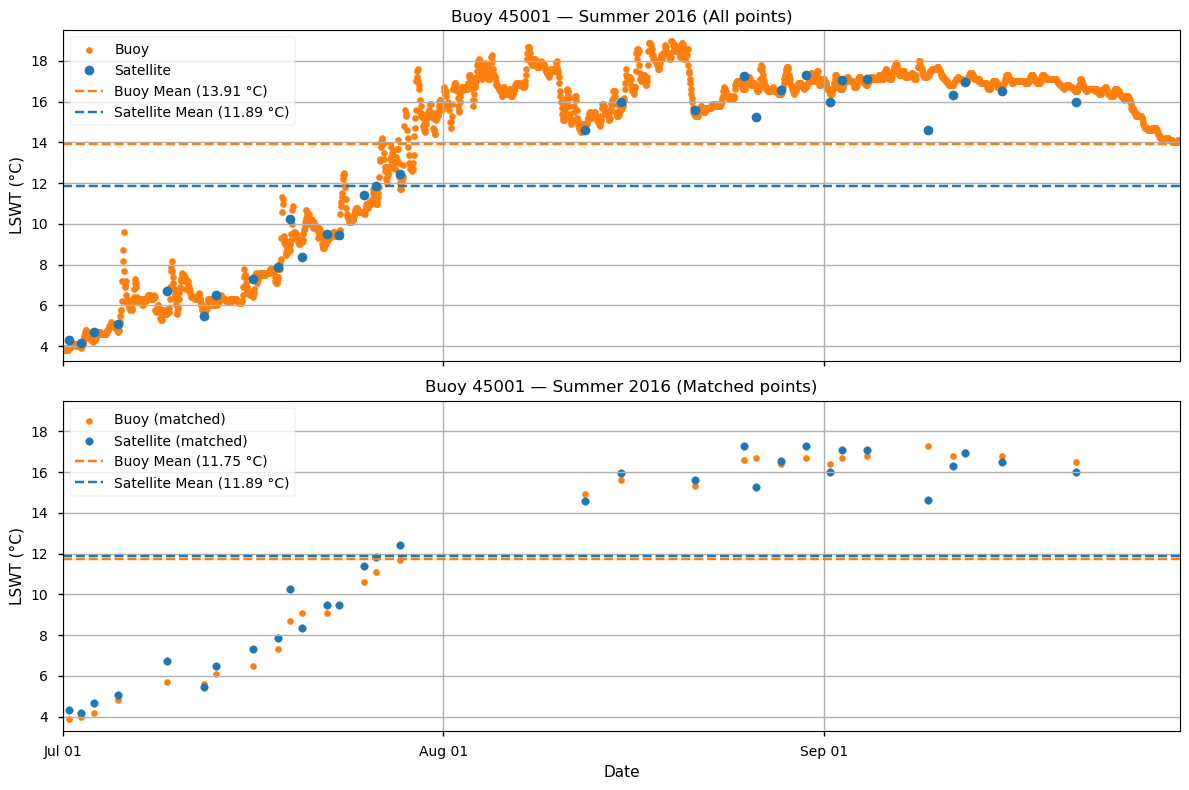
Figure 4 : Comparison of buoy and satellite measurements used to compute the 2016 mean summer LSWT at the location of buoy 45001.
This time-matching procedure is repeated for each buoy and year. Specifically, each satellite observation is paired with the nearest buoy measurement in time, provided that the time difference is less than the specified tolerance (default: 1 hour).
The mean summer LSWT computed from the successfully time-matched satellite–buoy pairs are compared in Figure 5. To further quantify differences between the time-matched satellite and buoy data, we compute the mean bias, mean absolute error (MAE), and root mean square error (RMSE).
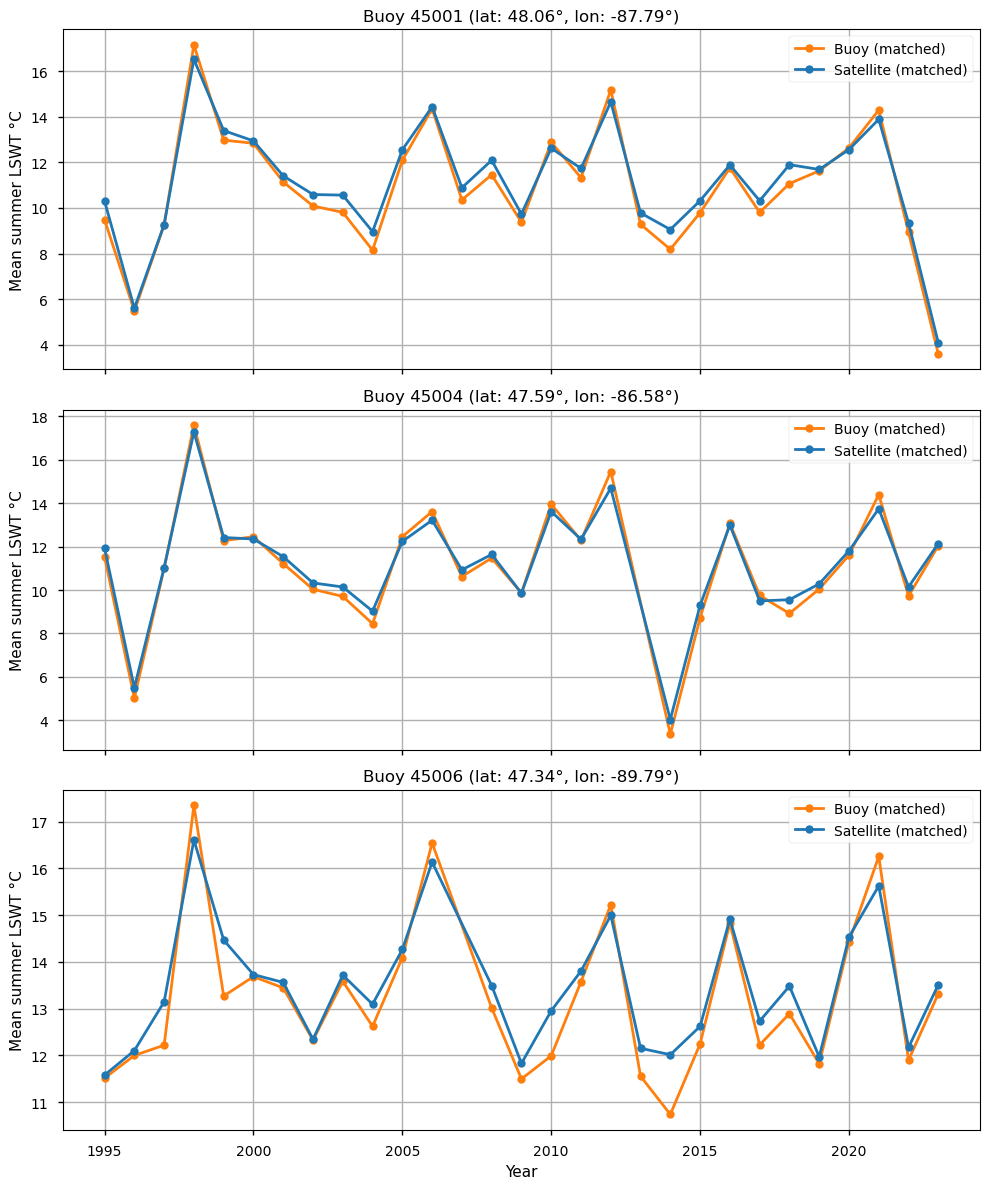
Figure 5: Mean summer LSWT from satellite data compared to buoy data using only successfully time-matched satellite–buoy pairs.
| station | n_samples | bias | MAE | RMSE | |
|---|---|---|---|---|---|
| 0 | 45001 | 29 | 0.30 | 0.43 | 0.50 |
| 1 | 45004 | 28 | 0.10 | 0.33 | 0.39 |
| 2 | 45006 | 28 | 0.26 | 0.41 | 0.53 |
| 3 | ALL | 85 | 0.22 | 0.39 | 0.48 |
Overall, the satellite data exhibit a small warm bias of 0.22 °C relative to the time-matched buoy observations, slightly larger than the bias obtained when using all available data to compute summer means (0.14 °C). In contrast, the MAE and RMSE are substantially reduced, at 0.39 °C and 0.48 °C, respectively (compared to 1.13 °C and 1.58 °C). This indicates that a large fraction of the difference between the LSWT means shown in Figure 3 (computed using all data) is attributable to the lower sampling frequency and limited temporal availability of the satellite observations, while individual satellite measurements are comparatively precise. The remaining discrepancies with buoy data are likely due to fundamental measurement differences: satellites measure the lake skin temperature, whereas buoys measure subsurface temperature (typically at ~1 m depth). Depending on atmospheric and lake conditions (e.g., wind and stratification), these measurements can differ. In addition, satellite retrievals may be affected by cloud contamination.
Estimation of linear trends#
Using all the available buoy data, we estimate linear trends for three periods: 1979–2006, 1995–2023, and 1979–2023 (Figure 6). These are compared with trends derived from satellite data and with previously published results.
For 1979–2006, the three buoys show warming trends of 0.108 °C/year, 0.098 °C/year, and 0.100 °C/year. Unsurprisingly, these values are consistent with the 0.11 ± 0.06 °C/year estimate reported in [3], which used the same buoy dataset. The associated p-values are relatively small (0.10, 0.30, and 0.07) but fall short of the conventional 0.05 significance threshold, likely due to the limited number of observations.
For 1995-2023, the three buoys show diverging trends of -0.013 °C/year, 0.035 °C/year, and 0.014 °C/year, with large associated p-values (\(\geq\)0.8), indicating that none of these trends are significant. Satellite-derived trends at the corresponding buoy locations (0.003 °C/year, −0.032 °C/year, and −0.004 °C/year) display the same qualitative behavior: diverging and non-significant. These results are consistent with those in Figure 2 based on spatially averaged satellite data, and with previous analyses [4], confirming the absence of a significant summer LSWT warming trend over this period.
For 1979–2023, the three buoys show warming trends of 0.048 °C/year, 0.061 °C/year, and 0.044 °C/year, with p-values just above the conventional 0.05 significance threshold. These results are consistent with [6], which reported a warming trend of 0.052±0.031°C/year for 1980-2021 based on simulation data.
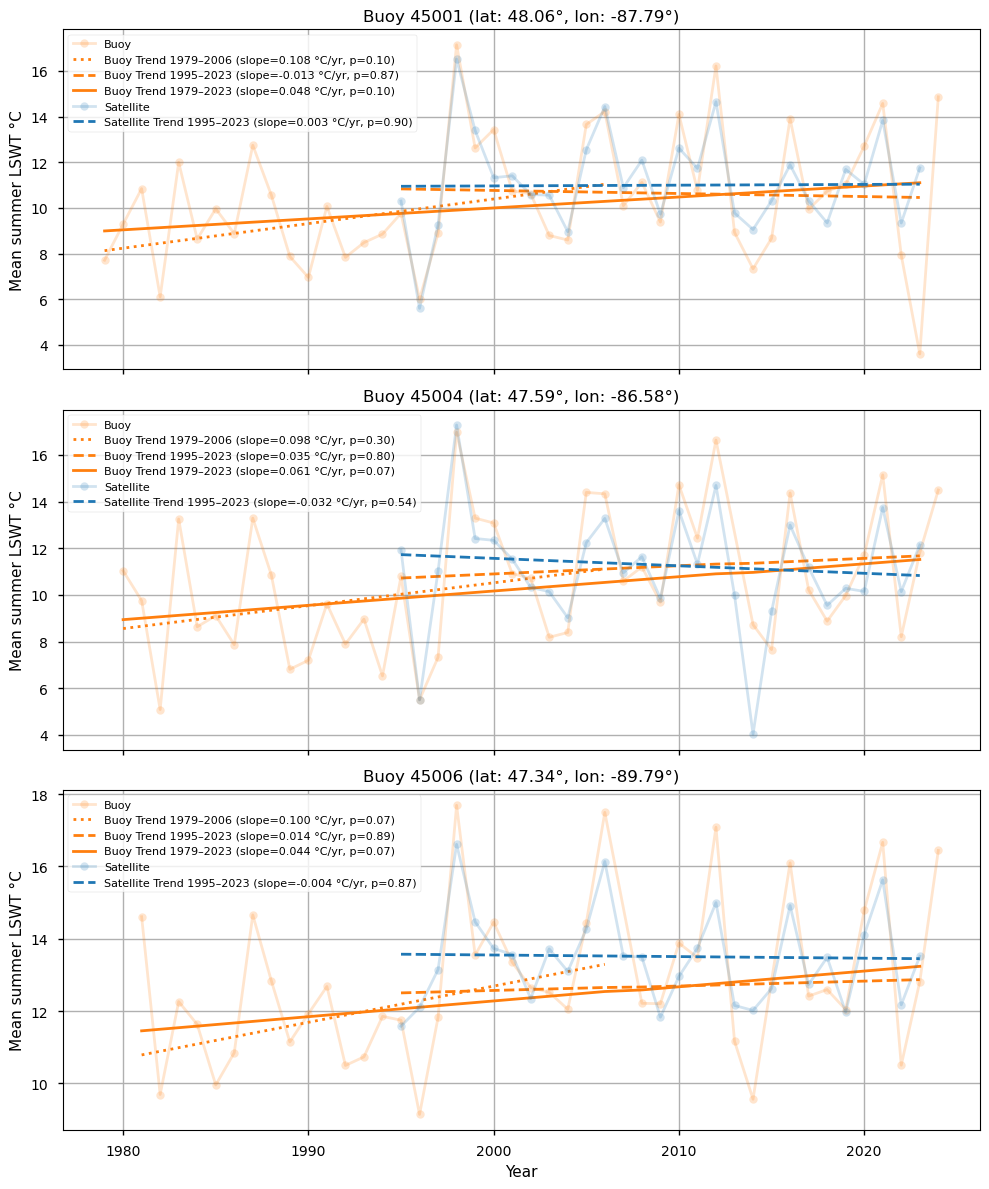
Figure 6: Time series of mean summer LSWT for buoy and satellite observations at each buoy location. Semi-transparent lines show summer means, and overlaid trend lines (dotted, dashed, or solid) indicate linear trends for different periods, with slope and p-values reported. Trends were estimated using the Theil-Sen method in combination with the Mann-Kendall test for statistical significance.
Discussion#
Lake Superior’s summer LSWT trend over 1995–2023, derived from the Copernicus satellite-lake-water-temperature dataset, is slightly negative but not statistically significant. Although this initially seemed surprising given sustained global warming, the result was confirmed using in-situ buoy data.
Overall, the satellite data show good agreement with the quality-controlled and time-matched buoy measurements, although the buoy records themselves may contain gaps or suspect observations and should not be interpreted as error-free ground truth. Differences in computed summer means primarily arise from the lower temporal sampling and occasional missing satellite observations, but the systematic bias is small. This indicates that the satellite-lake-water-temperature dataset is suitable for analyzing summer LSWT trends in Lake Superior. However, no significant warming trend is observed over the 1995–2023 period.
One possible explanation is the unusually high summer temperatures in 1998, associated with a strong El Niño event early in the satellite record. This may have contributed to the relatively large warming trend reported for 1979–2006 [3] and simultaneously obscured longer-term warming signals in the 1995–2023 period. Incorporating pre-1995 in-situ observations, where available, would improve assessments of long-term trends. Indeed, when considering the full buoy record, a near-significant warming trend of ~0.05 °C/year is observed over 1979–2023.
ℹ️ If you want to know more#
Farina, G., Thiem, H. (2024) Several Great Lakes experience record-warm water temperatures heading into winter. Climate.gov
Key resources#
Dataset documentation:
Code libraries used:
C3S EQC custom functions,
c3s_eqc_automatic_quality_control, prepared by B-Open
References#
[1] Wang, X., Shi, K., Qin, B. et al. (2024). Disproportionate impact of atmospheric heat events on lake surface water temperature increases. Nat. Clim. Chang.
[2] Copernicus (2018). Lake surface temperatures. Climate Change Service.
[3] Jay A. Austin, Steven M. Colman (2007). Lake Superior summer water temperatures are increasing more rapidly than regional air temperatures: A positive ice-albedo feedback. Geophysical Research Letters Volume 34, Issue 6.
[4] GLISA (2024). Lake Superior Retrospective.
[5] NOAA CoastWatch Great Lakes Regional Node (2024). Average Surface Water Temperature (GLSEA).
[6] Cannon, D., Wang, J., Fujisaki-Manome, A., Kessler, J., Ruberg, S., & Constant, S. (2024). Investigating Multidecadal Trends in Ice Cover and Subsurface Temperatures in the Laurentian Great Lakes Using a Coupled Hydrodynamic–Ice Model. Journal of Climate, 37(4), 1249-1276.
[7] NOAA National Buoy Data Centre.
[8] National Data Buoy Center (NDBC) (2023). Handbook of Automated Data Quality Control Checks and Procedures. NDBC Technical Document T80-10. National Oceanic and Atmospheric Administration (NOAA), National Weather Service, Stennis Space Center, Mississippi, USA.