

4.1. Seasonal Forecast Prediction of Upper Ocean Heat Content Extremes#
Production date: 01-03-2026
Produced by: Helene B. Erlandsen (METNorway)
🌍 Use case: Predicting upper ocean heat content extremes in climate services#
❓ Quality assessment question#
What is the forecast skill of the seasonal prediction system for detecting extreme upper ocean heat content events in the NDJ season, from October initializations?
This notebook evaluates the skill of the Météo-France System-9 seasonal forecasting system in predicting upper ocean heat content extremes. We chose this system as an example since it had high data coverage of 300-m integrated potential temperature. The analysis uses:
Seasonal Forecast Data: Monthly depth-averaged potential temperature for the upper 300 m, from Météo-France System-9 forecasts. [doi:10.24381/cds.2f9be611]
Reanalysis Data: Ocean heat content from the ORAS5 global ocean and sea-ice reanalysis dataset. [doi:10.24381/cds.67e8eeb7]
We consider the skill in predicting upper ocean heat content extremes in November, December, and January between 1993 and 2023 for (re-)forecasts with a nominal start date October 1st, using metrics such as the Symmetric Extremal Dependence Index (SEDI) and the Brier Skill Score (BSS). The metrics considered follow Jacox et. al. 2022, [1], however in this work we look at upper ocean heat content and not sea surface temperature. Since ocean heat content (OHC) anomalies may persist for several months, this variable is an important component of seasonal predictability, containing relevant information even at a monthly time-scale (McAdam et. al. 2022, [2]).
📢 Quality assessment statement#
These are the key outcomes of this assessment
The Météo-France System-9 forecast model demonstrates skill in detecting the risk of NDJ (November-January) upper ocean heatwaves. The model successfully captures 33% of observed heatwaves in November, with hit rates remaining consistent through December (30%) and January (27%).
The forecast is useful for identifying broad, large-scale patterns of risk, particularly during major El Niño events. However, the Brier Skill Score (BSS) highlights that its probabilistic reliability varies by region. Using a multi-model forecast ensemble would likely increase the spread of the forecasts and provide more reliable results outside the ENSO region.
The system has potential as a tool for anticipating and building resilience to marine heatwaves, especially in ENSO-sensitive regions. This analysis could be extended to other C3S seasonal systems for which the required data are available.
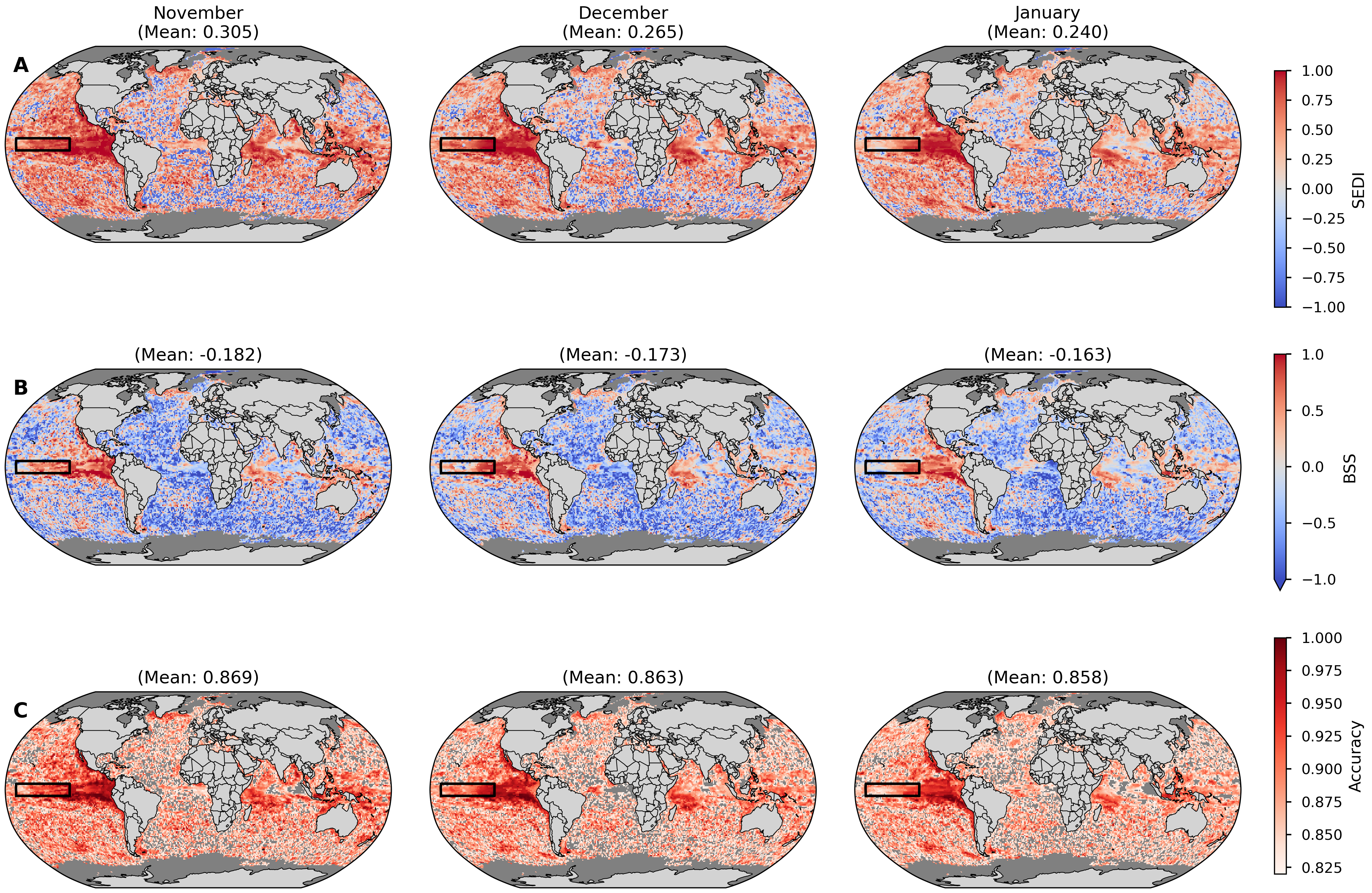
Fig. 4.1.1 Figure 1: Spatial Forecast Skill for November-December-January (NDJ) Upper Ocean Heatwaves (1993–2023). Skill of Météo-France System-9 forecasts (with nominal start date October 1st) verified against ORAS5 reanalysis. Heatwaves are defined as upper 300m ocean heat content (OHC) anomalies exceeding the 90th percentile within the 1993-2023 period. Rows show: (A) Symmetric Extremal Dependence Index (SEDI), (B) Brier Skill Score (BSS); and (C) Accuracy. In all maps, red areas indicate positive skill (forecast is better than the reference), while blue areas indicate negative skill. Masked areas are shown in grey. For the Accuracy maps (C) the areas with an accuracy lower than what would be expected by random chance (82%) are also shown with a grey color.#
📋 Methodology#
The following steps were applied to evaluate the skill of the seasonal forecasting system in predicting heatwave extremes:
This section includes:
imports, settings, parameter definitions, and reusable functions required to initialize the analysis. Here the extent of the Nino3.4 area is given (5°N–5°S, 170°–120°W, also delineated in most map plots, e.g. Figure 3). This area is selected to represent the tropical Pacific and ENSO, providing a key benchmark for seasonal predictability. The data is also loaded in this section.
Météo-France System-9: The seasonal forecast data includes monthly depth-averaged potential temperature for the upper 300m. We use the hindcasts with a nominal start date of October 1st, between 1993 and 2023. For consistency only the hindcast period is used, since the model system has a different number of ensemble members in the forecast period compared to the hindcast period. depth_average_potential_temperature_of_upper_300m (\(\bar{\Theta}\)) was converted to OHC using the similar constants as used by ORAS5 (pers. comm.): \(\text{OHC} =\rho \, c_p \, \bar{ \Theta} \, dz \), where \( \rho = 1026 \, \text{kg/m}^3\), \( c_p = 3991 \, \text{J/kg/K} \), and \( dz = 300 \, \text{m} \).
ORAS5: Reanalysis OHC for the upper 300m is used as the observational reference. Data is regridded to a common 1° spatial resolution using conservative normalization in xESMF.
The seasonal forecast and reanalysis data were processed for the period from 1993 to 2023; and we consider forecasts with a nominal start date October 1st, valid for November, December, and January. For instance, the last season considers forecasts with a nominal start date October 1st 2023 for November and December 2023, and January 2024. By choosing an October initialization, we avoid compounding the task of extreme event detection with the lower predictability associated with other initialization windows, such as the boreal spring period in the Eastern Tropical Pacific (Jacox et. al. 2022, [1]).
Anomalies: Monthly anomalies are calculated by subtracting the calendar month climatology.
We also apply a common land mask to the interpolated products, also omitting areas where at any time the seasonal forecasts has temperatures below 0°C (we could have used a lower threshold than 0°C, but use this threshold as it at least will mask out all ice covered areas).
The seasonal forecast system (System 9) is initialized by nudging the ocean and sea-ice models towards the Mercator Ocean International GLORYS12V1 reanalysis, except for wihtin 225 km of coastlines or in the presence of sea ice (Specq et. al. 2024, [3]). In contrast, ORAS5 is used as the reference reanalysis in this study. This makes the reference data somewhat independent, however, the data assimilated in ORAS5 and GLORYS12 likely overlap to a great extent. Differences in means will not affect the conclusions as anomalies are considered. Further, the limits for a heatwave is calculated separately for the seasonal forecast data and the reference data, allowing them to have different distributions.
2. OHC Time Series and Trend Analysis
We compare the data in map plots and in area aggregated time-series plots. Initial inspection showed strong temporal trends in OHC during the time period. The linear trends were removed from the raw data, so that the trends would not inflate the skill scores. Further, the strong temporal trends would skew the diagnosis of heatwaves to primarily occur in the more recent years.
3. Model Performance vs. Reanalysis
The OHC anomalies based on detrended data were used to assess heatwaves. We show that the reference data and seasonal forecasting data have different data distributions. To align our diagnosed heatwaves, the defined percentiles of a heatwave are calculated separately depending on both the data source and the calendar month. To avoid unrealistic jumps, and to align our analysis with Jacox et. al. 2022, [1] we use a three-month centered rolling window to set the monthly heatwave thresholds. For instance, January thresholds are derived from pooled December, January, and February anomalies. Heatwaves are defined as anomalies exceeding the 90th percentile.
In the subsequent sections we evaluate the forecast over different dimensions:
Pooling and grouping strategies#
Analysis Goal |
Grouping Strategy |
Question It Answers |
|---|---|---|
Skill Maps |
Pool time and ensemble for each grid point. |
“What is the forecast skill at this specific location over the entire 30-year period?” |
Annual Time Series |
Pooled horizontally and over the ensemble for each year. |
“What was the overall global forecast accuracy in the year 1997?” |
Summary Tables |
Pool time, space, and ensemble for each lead-time (month). |
“What was the overall global forecast skill for all Novembers combined in the record?” |
4. Metrics: SEDI, BSS, Accuracy
We evaluate the forecasting system using the metrics outlined below.
SEDI - the Symmetric Extremal Dependence Index#
SEDI quantifies the forecast skill for rare binary events (e.g., heatwaves). It is the Symmetric Extremal Dependence Index (Ferro & Stephenson 2011 [4]). SEDI has a maximum value of one, and a minimum value of -1. Scores above zero indicate a forecast better than random chance.
SEDI is built on the output of a contingency table. A contingency table provides: sample size, n; base rate, p; hit rate, H; and false-alarm rate, F. The ensemble members are pooled and each adds to the counts in the contingency table before the SEDI score is calculated.
Event observed |
Non-event observed |
||
|---|---|---|---|
Event forecasted |
a = Hpn |
b = F(1-p)n |
a + b |
Non-event forecasted |
c = (1-H)pn |
d = (1-F)(1-p)n |
c + d |
Sum |
a + c = pn |
b + d = (1-p)n |
n |
Hit rate (H) = \( \frac{a}{a+c} \), False alarm rate (F) = \( \frac{b}{b+d} \)
SEDI = \( \frac{logF - logH -log(1-F) + log(1-H)}{logF + logH +log(1-F) + log(1-H)} \)
The Brier Skill Score (BSS)#
The Brier Skill Score (BSS) compares the forecast skill against a reference forecast (e.g., climatology), which for heatwaves defined as values above 90% of those observed, would be that there always was about a 10% chance of a heatwave.
It is calculated as: \( \text{BSS} = 1 - \frac{\text{Brier Score (BrS)}}{\text{BrS}_{\text{ref}}} \)
It is based on the Brier Score, which measures the mean squared error between forecast probabilities and observed binary events.
The BSS’s upper limit is 1, meanwhile it has no lower limit. Scores above zero indicate a forecast better than the climatology, which is around a 10% chance.
Accuracy#
Accuracy measures the proportion of correct predictions (both true positives and true negatives) out of the total number of forecasts made. The formula is:
\( \text{Accuracy} = \frac{\text{True Positives (TP)} + \text{True Negatives (TN)}}{\text{Total Predictions (N)}} \)
For rare events like heatwaves (which occur about 10 % of the time in this study), a simple accuracy score can be misleading. A forecast that always predicts “no heatwave” would be 90 % accurate but have zero skill. Therefore, we compare the forecast’s accuracy to a random chance benchmark. For an event with a 10% probability (p=0.1), the accuracy of a random forecast is calculated as:
\( \text{Random Accuracy} = p^2+(1−p)^2 = 0.1^2+(0.9)^2 = 0.82 \)
This means the forecasting system must achieve an accuracy greater than 0.82 (or 82%) to be considered more skillful than random chance.
5. Contingency Table Analysis The contingency tables for all November, December, and January’s are presented and discussed.
6. Annual Variability and ENSO Influence Finally, we display the annual metrics as time-series, also showing the components of the contingency table, allowing a discussion of the components of the metrics.
📈 Analysis and results#
1. Data Preparation#
This section includes imports, settings, parameter definitions, and reusable functions required to initialize the analysis.
Imports and Settings#
Definition of Parameters#
We have chosen Meteo-France System-9, and focus on the hindcast period, which are available from 1993 until 2024, to have a consistent ensemble throughout the analysis.
We focus on the forecasts initiated October 1st every year, and consider one, two, and three months leadtimes - i.e. the forecasted values for November, December, and January. In the initial processing also October and February values are used, as the heatwave thresholds are centered a three-month month moving window.
Helper Functions for Data Processing and Plotting#
Data Loading#
We download the reanalysis and seasonal forecast datasets, regridding the reanalysis data to align with the seasonal forecast grid, and computing the detrended anomalies. These transformations are performed using the c3s_eqc_automatic_quality_control download.download_and_transform function and custom preprocessing steps. xesmf conservative regridding was used to transform the ORAS5 ORCA025 grid to a global 1x1 latlon grid. Sensitivity tests were conducted to ensure that the regridding process (comparing area-conservative interpolation used for ORAS5 vs. a version of the two step distance-weighted interpolation that System 9 underwent) produced similar changes to the mean and variance of the original data (not shown).
The data is combined and reindexed so that year and calendar month are the dataset coordinates.
The long-term climatology and possibly the monthly trend is subtracted.
We apply a common land mask and also mask out areas where seasonal forecast data have values corresponding to a monthly mean potential temperature below 0°C.
The seasonal forecast vertically integrated potential temperature is converted to OHC, following the convention used in ORAS5.
The variable names are changed to reflect their current state.
Building a flat list of unique reanalysis requests...
Found 155 unique months of reanalysis to download.
2. OHC Time Series and Trend Analysis#
Compares the model’s OHC and heatwave representation against the reanalysis. The time series of globally averaged OHC anomalies clearly shows a strong positive trend over the 1993-2023 period (Figure 2). This warming trend is present in both the ORAS5 reanalysis and the Météo-France System 9 seasonal forecasts, though it is slightly stornger in Météo-France System 9. Because this predictable, long-term signal could artificially inflate skill scores, the linear trend is removed from both datasets for all subsequent heatwave and skill analyses. The detrended time series shows the interannual variability, such as the strong El Niño events, more clearly.
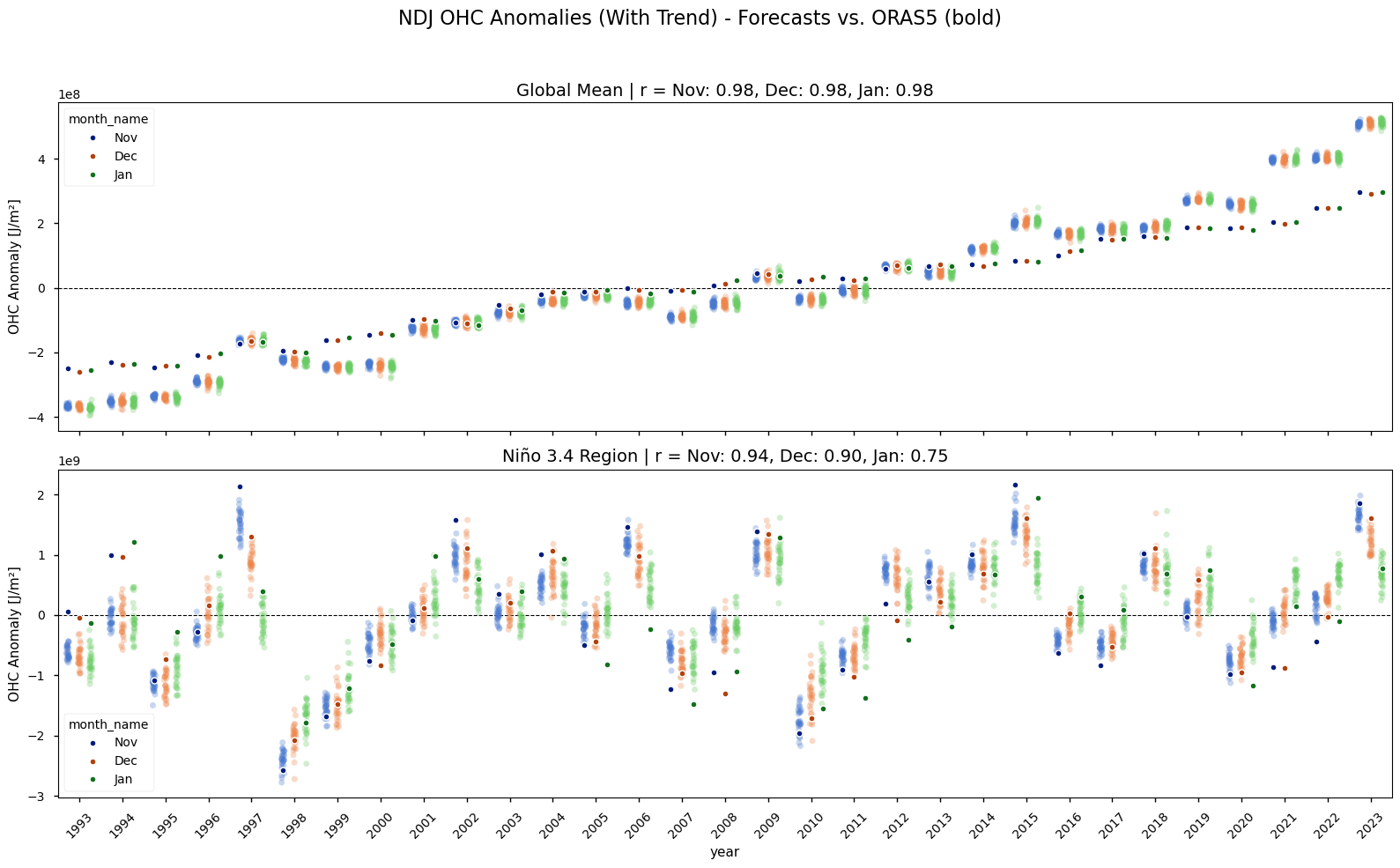
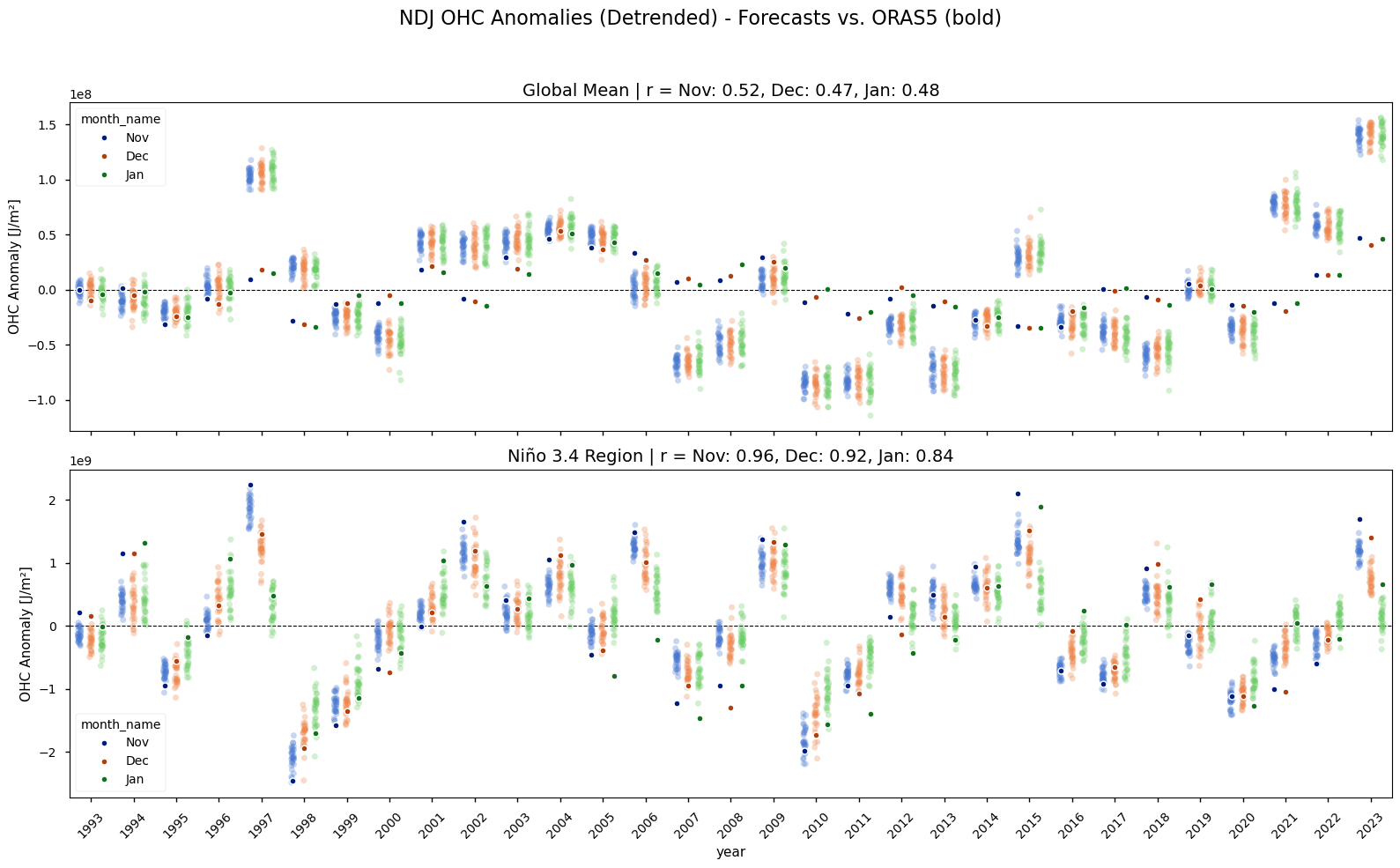
Figure 2#
Annual time series of reanalysis and forecast anomalies according to calendar month. The forecast fields have a nominal start date October 1st. The single dots with a stronger color shows the reanalysis data, while the more lightly colored plot clouds show the seasonal forecasts (one dot per realization). The upper two rows show the anomalies in the original time-series for the global and Niño3.4 area, while the lower panels show the detrended data. The subplot-titles provide the Pearson correlation coefficients of the area averaged anomalies. Note that the y-axis range varies.
3. Model Performance vs. Reanalysis#
This section directly compares the model’s OHC and heatwave representation against the reanalysis, after having detrended both.
Correlation of OHC Anomalies#
/data/common/miniforge3/envs/wp3/lib/python3.12/site-packages/dask/array/numpy_compat.py:58: RuntimeWarning: invalid value encountered in divide
x = np.divide(x1, x2, out)
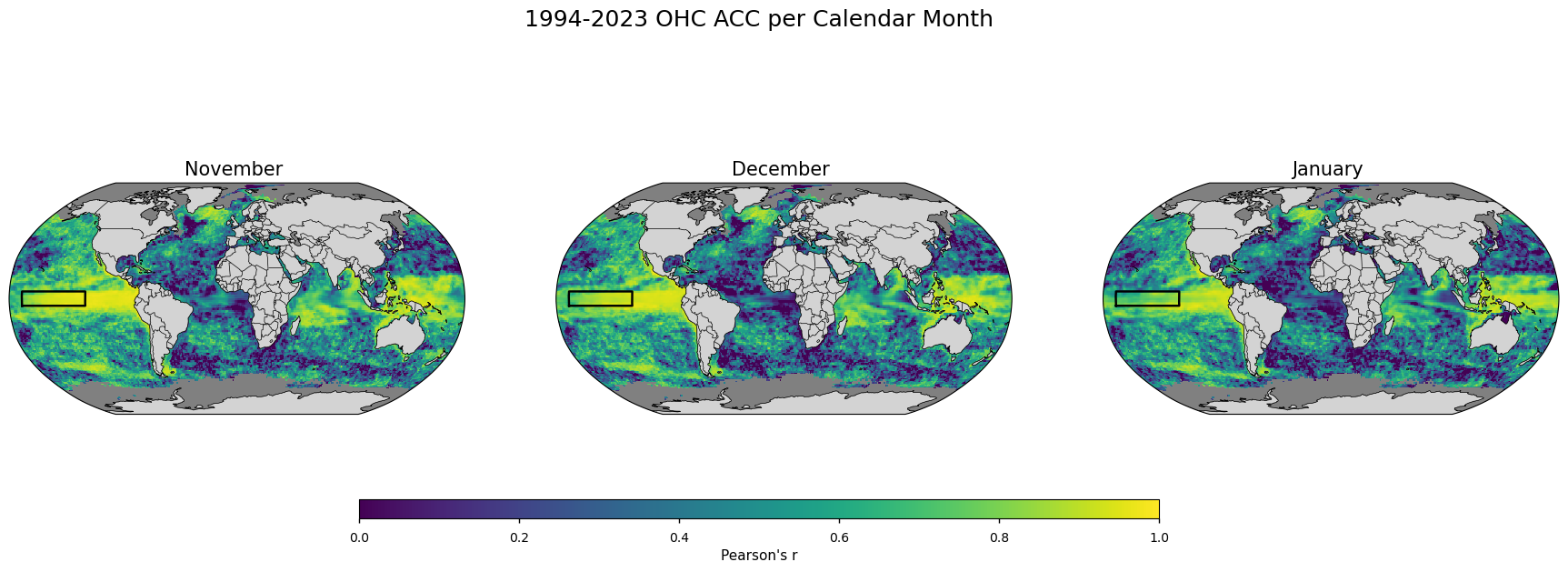
Figure 3#
Map plot showing the temporal anomaly correlation coefficients (Pearson’s) between the forecast ensemble mean and the reanalysis 1993-2023 NDJ OHC every valid grid box.
Comparison of distributions#
We inspect the OHC anomalies in the two data sources to see if they share a similar distribution. We look at November, December, and January simultaneously and pool the seasonal forecast ensemble members. Identical distributions and tails would allow for the use of the same physical magnitudes for a heatwave threshold.
The differences in the probability density functions, the longer tails in the reanalysis versus the more blunt tails in the forecasts justify the use of relative heatwave thresholds depending on the specific data source.
Starting statistical analysis (subsampling step: 5)...
Computing weighted statistics...
--- Statistics Summary ---
Metric Forecast (S9) Reanalysis (ORAS5)
StdDev (J/m²) 6.40e+08 6.71e+08
Kurtosis 4.18 6.50
Total Points 3687357 118947
Points per Member 118947 118947
K-S Test p-value: 1.73e-47
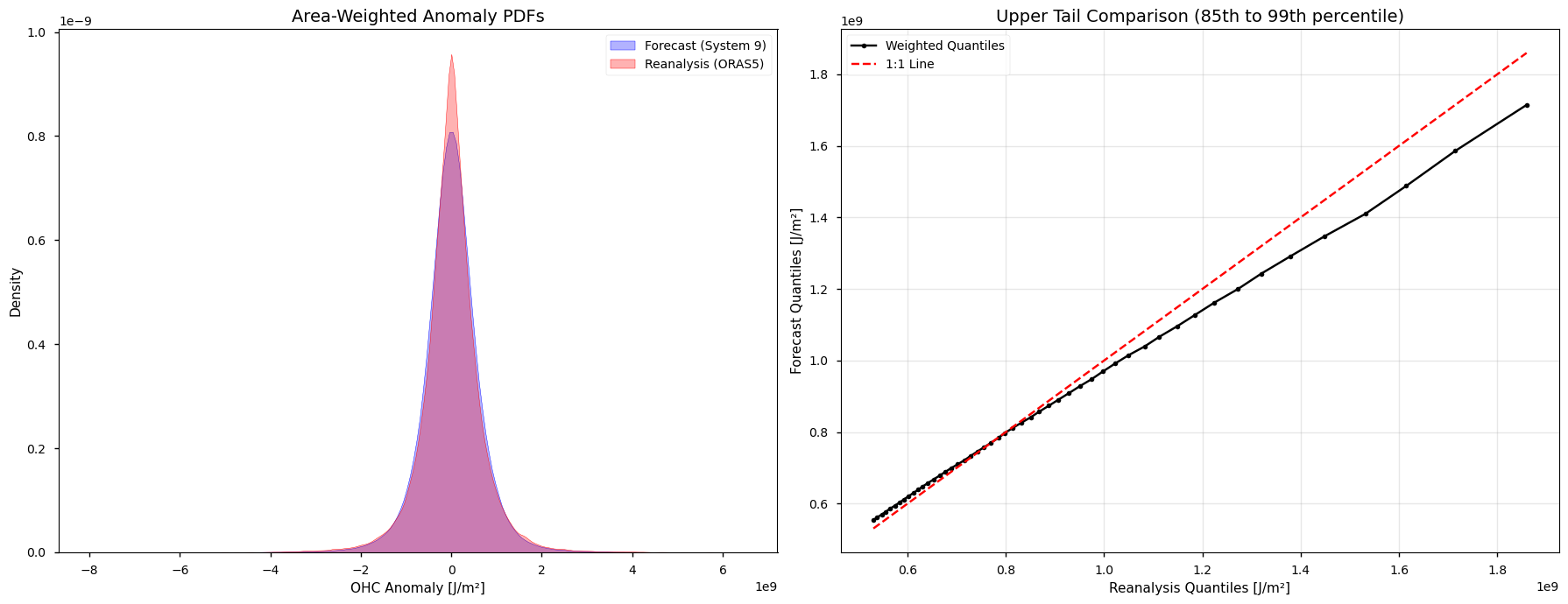
Figure 4#
Distribution analysis of pooled OHC anomalies for the NDJ season. The left plot shows the area-weighted probability density functions (PDFs) for the forecast (blue) and reanalysis (red), where the broader “shoulders” of the blue curve indicate a blunter distribution. The right plot shows a quantile-quantile comparison of the upper tail (\(P_{85}\) to \(P_{99}\)) of the two data sources. The black line falling below the diagonal indicate higher intensity values (longer tails) in the reanalysis data compared to the forecast.
Comparison of Heatwave Representation#
Heatwaves are defined as monthly anomalies exceeding a 90th percentile threshold. The thresholds are calculated from a three-month centered moving window, and separately for each data source. For reanalysis data, the threshold is calculated across all years at each grid point. For the seasonal forecast, the threshold is calculated across all years and all ensemble members at each grid point.
Computing p90 thresholds...
/data/common/miniforge3/envs/wp3/lib/python3.12/site-packages/numpy/lib/_nanfunctions_impl.py:1617: RuntimeWarning: All-NaN slice encountered
return fnb._ureduce(a,
Thresholds computed.
Generating heatwave masks...
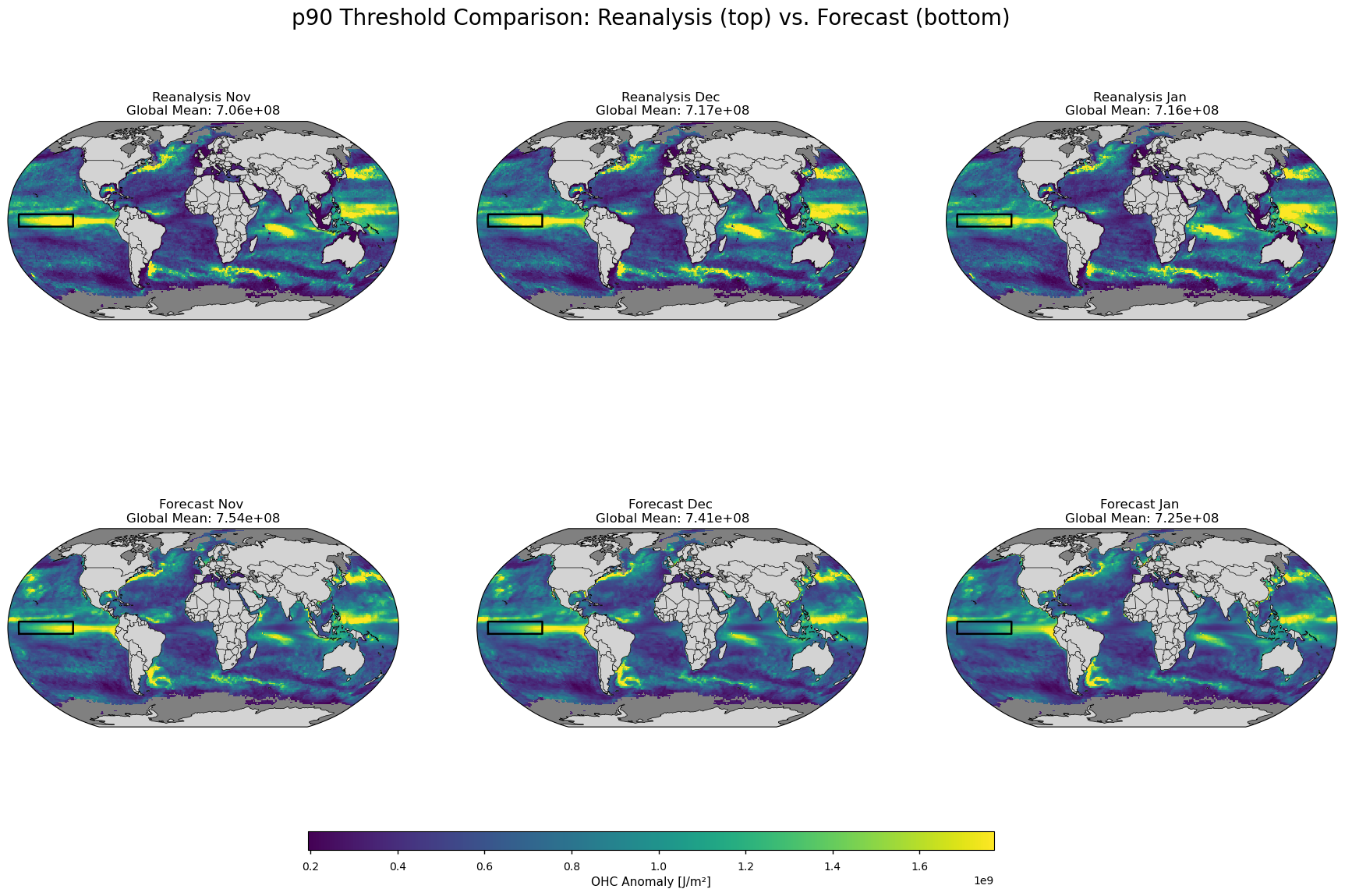
Figure 5#
Map plot showing the definition of heatwave (or the grid cell threshold to be exceeded) in the OHC anomalies for the seasonal forecasts (left) and the reanalysis (right).
Diagnostic Plots.#
We choose 1997 as our year to inspect the spatial patterns of the anomalies.
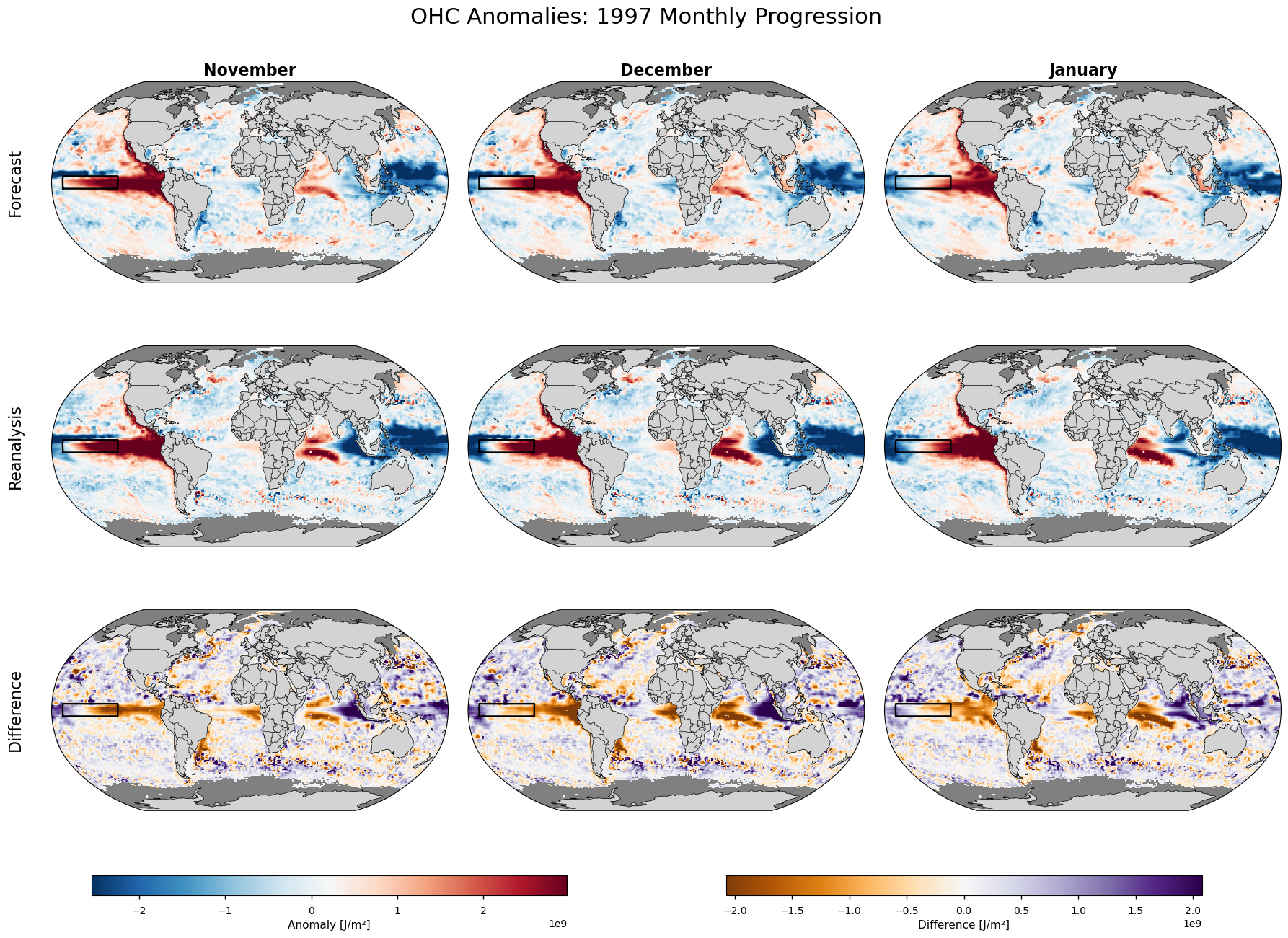
Figure 6#
Map plots showing ensemble mean OHC anomalies from the seasonal forecast with a nomianal start date 1 October 1997 (upper row), the corresponding reanalysis fields (centre row), and their difference (forecast minus reanalysis, bottom row).
4. Metrics: SEDI, BSS, Accuracy#
This section presents the primary skill scores (SEDI, BSS, Accuracy).
Symmetric Extremal Dependence Index (SEDI)#
SEDI (Ferro & Stephenson 2011, [4]) is calculated using the hit rate (H) and false alarm rate (F), as can be found in a contingency table:
\( \text{SEDI} = \frac{\log(F) - \log(H) - \log(1-F) + \log(1-H)}{\log(F) + \log(H) + \log(1-F) + \log(1-H)} \)
To avoid numerical issues, logarithms are computed using a lower bound of \(10^{-6}\).
The Brier Skill Score (BSS)#
The Brier Skill Score (BSS) here compares the forecast’s Brier score against the Brier score of using the climatology of the reference data set as a forecast. The climatologically based heatwave forecast is near a 10% chance, but is here calculated explicitly per grid point. The BSS’s upper limit is 1, meanwhile it has no lower limit. Scores above zero indicate a forecast better than climatology.
Accuracy Assessment#
Proportion of correct predictions relative to total events. Forecast accuracy was calculated as: \( \text{Accuracy} = \frac{\text{True Positives} + \text{True Negatives}}{N} \) where \(N\) is the total number of events. Accuracy above a random threshold (e.g., 0.82 for a base rate of 0.1) indicates skill better than chance.
Pooling Strategy for Skill Metrics in Map Form#
To calculate robust skill scores, data is pooled in different ways depending on the metric. The BSS pools the ensemble members at once, while this is done in a later step for SEDI and Accuracy:
For SEDI and Accuracy: These metrics are calculated from a contingency table (i.e., hits, misses, false alarms, correct rejections). For these every ensemble member in every year is treated as an independent event. This means we are pooling across the time dimension (1993-2023) and the ensemble dimension. This results in a single, robust skill score map that represents the overall performance for that calendar month across the entire period.
For the Brier Skill Score (BSS): This metric evaluates the performance of a probabilistic forecast compared to a reference forecast (here climatology) for each calendar month and grid cell. The calculation is done in steps:
First, for each year, the ensemble members are pooled to create a single forecast probability for that year (e.g., if 5 of 25 members predict a heatwave, the probability is 0.2).
The Brier Score is then calculated for each year by comparing that probability to the single observed outcome (
1or0).Finally, these annual Brier Scores are averaged across all years to get the final score. The BSS then compares this to the reference score from climatology.
Findings#
A key finding of this analysis is a divergence between the metrics in several regions (Figure 7). The SEDI and Accuracy scores ( > 0.82) indicate that the forecast is better than a reference climatology, while BSS is weakly negative in many regions. A negative BSS indicates that the forecast is less skillful than the long-term climatological average, i.e. assuming a ~10% chance of a heatwave everywhere, every year.
This suggests that while the model has the ability to correctly identify many heatwave events (demonstrated in the positive SEDI), it likely forecasts with too much confidence or has a high “false alarm rate,” where it predicts heatwaves that don’t occur. The BSS penalizes this lack of reliability, while SEDI, which focuses only on the co-occurrence of extreme events, is less sensitive to it.
The highest skill (SEDI > 0.5) is consistently found in the tropical Pacific Ocean. This region’s variability is dominated by the El Niño-Southern Oscillation (ENSO), the primary source of seasonal predictability in the climate system. The model successfully captures the OHC anomalies associated with strong ENSO events. The skill is lower in the mid-to-high latitudes. These regions are governed by more chaotic and faster-moving atmospheric and oceanic processes, making them more difficult to predict months in advance.
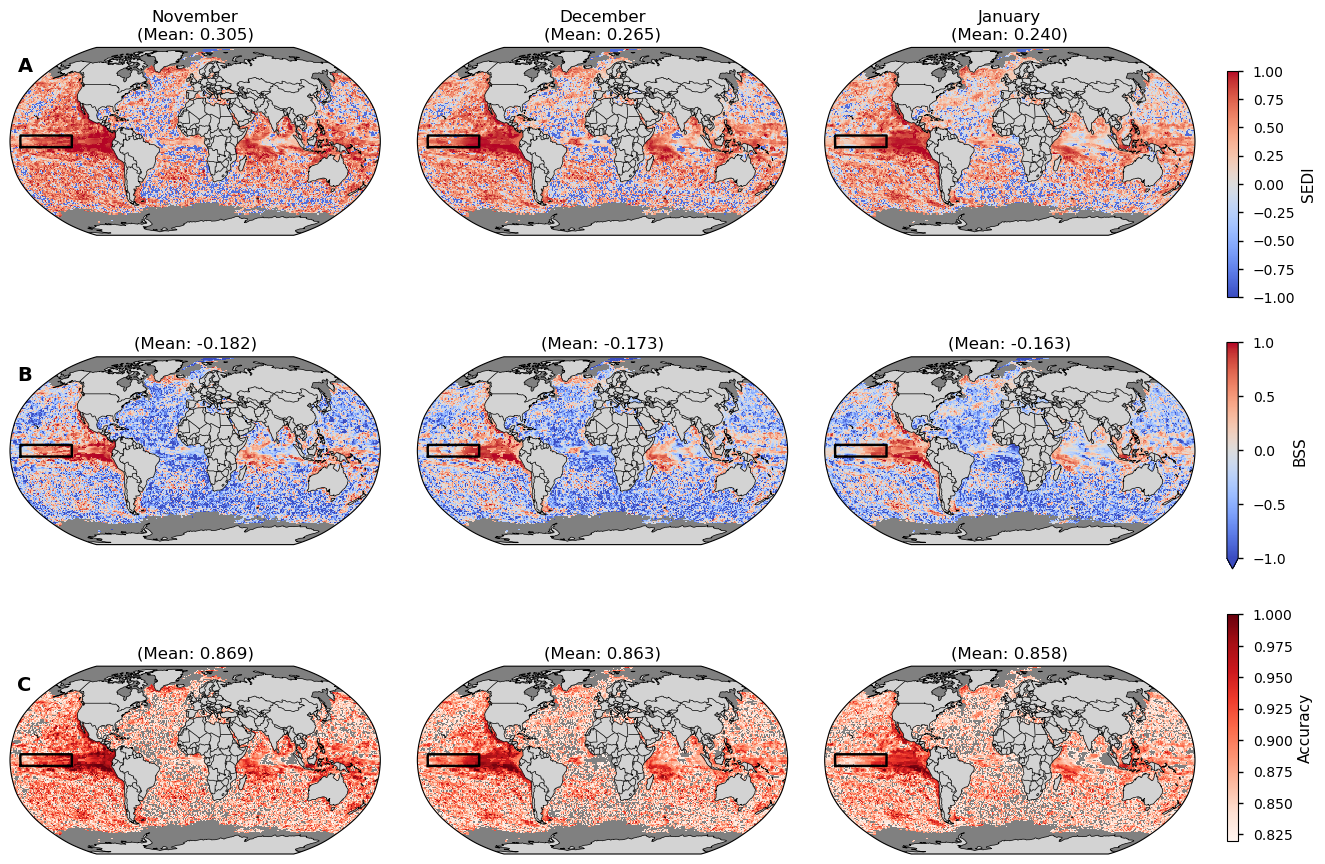
Figure 7#
Skill of Météo-France System-9 forecasts with a nominal start date October 1st for November, December, and January, using the ORAS5 reanalysis as the reference dataset. Heatwaves are defined as upper 300m ocean heat content (OHC) anomalies exceeding the 90th percentile within the 1993-2023 period. Rows show: (A) Symmetric Extremal Dependence Index (SEDI), (B) Brier Skill Score (BSS); and (C) Accuracy. In all maps, red areas indicate positive skill (forecast is better than the reference), while blue areas indicate negative skill. Masked areas are shown in grey. For the Accuracy maps (C) the areas with an accuracy lower than what would be expected by random chance (82%) are also shown with a grey color.
5. Contingency Table Analysis#
We examine the spatially-pooled contingency tables for each month to better understand the forecast behavior.
--- Contingency Tables in Percent (%) ---
November:
| Event Observed | Non-event Observed | Total (Forecast) | |
|---|---|---|---|
| Event Forecasted | 3.2% | 6.8% | 10.0% |
| Non-event Forecasted | 6.6% | 83.5% | 90.0% |
| Total (Observed) | 9.7% | 90.3% | 100.0% |
December:
| Event Observed | Non-event Observed | Total (Forecast) | |
|---|---|---|---|
| Event Forecasted | 2.9% | 7.1% | 9.9% |
| Non-event Forecasted | 6.8% | 83.2% | 90.1% |
| Total (Observed) | 9.7% | 90.3% | 100.0% |
January:
| Event Observed | Non-event Observed | Total (Forecast) | |
|---|---|---|---|
| Event Forecasted | 2.6% | 7.4% | 10.0% |
| Non-event Forecasted | 7.0% | 83.0% | 90.0% |
| Total (Observed) | 9.6% | 90.4% | 100.0% |
For all Novembers (one month leadtime, or 1-2 months, to be exact), when the model predicts a marine heatwave, that prediction is correct 32% of the time (Precision). Conversely, the False Discovery Rate is 68%, meaning roughly two-thirds of forecasted heatwaves did not materialize in observations. The predictive skill degrades slightly with lead time; by January (three month leadtime), the probability of a forecasted heatwave actually occurring drops to 26%.
Regarding the capture of observed events (Hit Rate), the model successfully anticipates 33% of the heatwaves that occurred in November. This capability decreases marginally to 30% in December and 27% in January. Overall, the system demonstrates an ability to capture approximately one-third of heatwave events at a one-month lead time, though users must be mindful of the high false alarm ratio.
6. Annual Variability and ENSO Influence#
We now investigate the year-to-year skill for each month and its potential connection to ENSO.
Annual metrics - global#
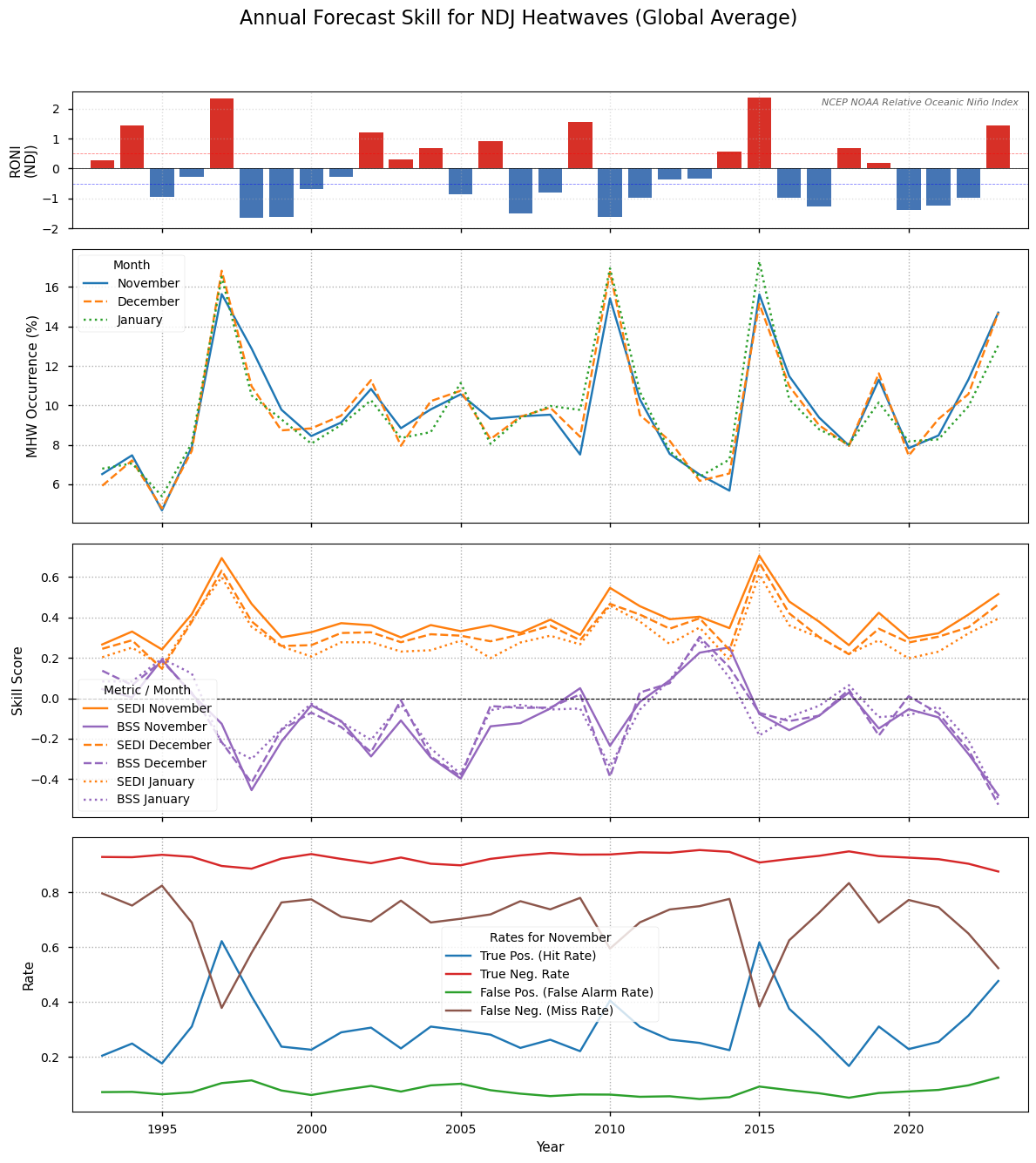
Figure 8#
Annual time series of globally-averaged forecast performance for the NDJ season. The upper panel depticts occurrence of El Niño according to the NCEP NOAA Relative Oceanic Niño Index (RONI), defines as the three month running average of the relative Niño 3.4 index. The second row depicts global marine heatwave (MHW) occurrence each year, i.e. the percentage of gridcells in heatwave conditions. The third plot shows the SEDI and the BSS in NDJ averaged over the valid ocean region. The contingency table components, the False or True Positives and Negatives each year for a selected month, November, are shown in the lower plot. The figure is similar to Extended Data Fig. 5 in Jacox et. al. 2022, [1].
An analysis of global year-to-year variability in SEDI and BSS (Figure 8) reveals a divergence in skill metrics. The SEDI scores (orange lines) remain positive and notably peak during major El Niño events (e.g., 1997-98, 2015-16). This indicates that the forecast system is highly effective at signal detection; it successfully identifies high-risk periods during these major climate drivers. Conversely, the BSS (purple lines), which measures probabilistic skill, often deteriorates during these same events. This might indicate that the single-model system is overconfident. The distribution analysis (Figure 4) shows that the reference reanalysis exhibits a sharper tail than the forecast ensemble. While the model often captures the correct warming signal, this lower extreme-tail variability may be linked to the observed overconfidence in its probabilistic assignments.
While the model correctly predicts the risk of a heatwave (high SEDI), the probability it assigns is less accurate. This is a common limitation of single-model systems, where the ensemble spread is insufficient to represent true uncertainty. Transitioning to a multi-model ensemble would likely improve reliability for decision-making by increasing that spread.
We focus on a key area: the Niño 3.4 region (5°N-5°S, 170-120°W). The Niño 3.4 region was chosen as it represents the tropical pacific and the ENSO.
Annual metrics - Niño 3.4 region#
--- Running Case Study: Niño 3.4 Region ---
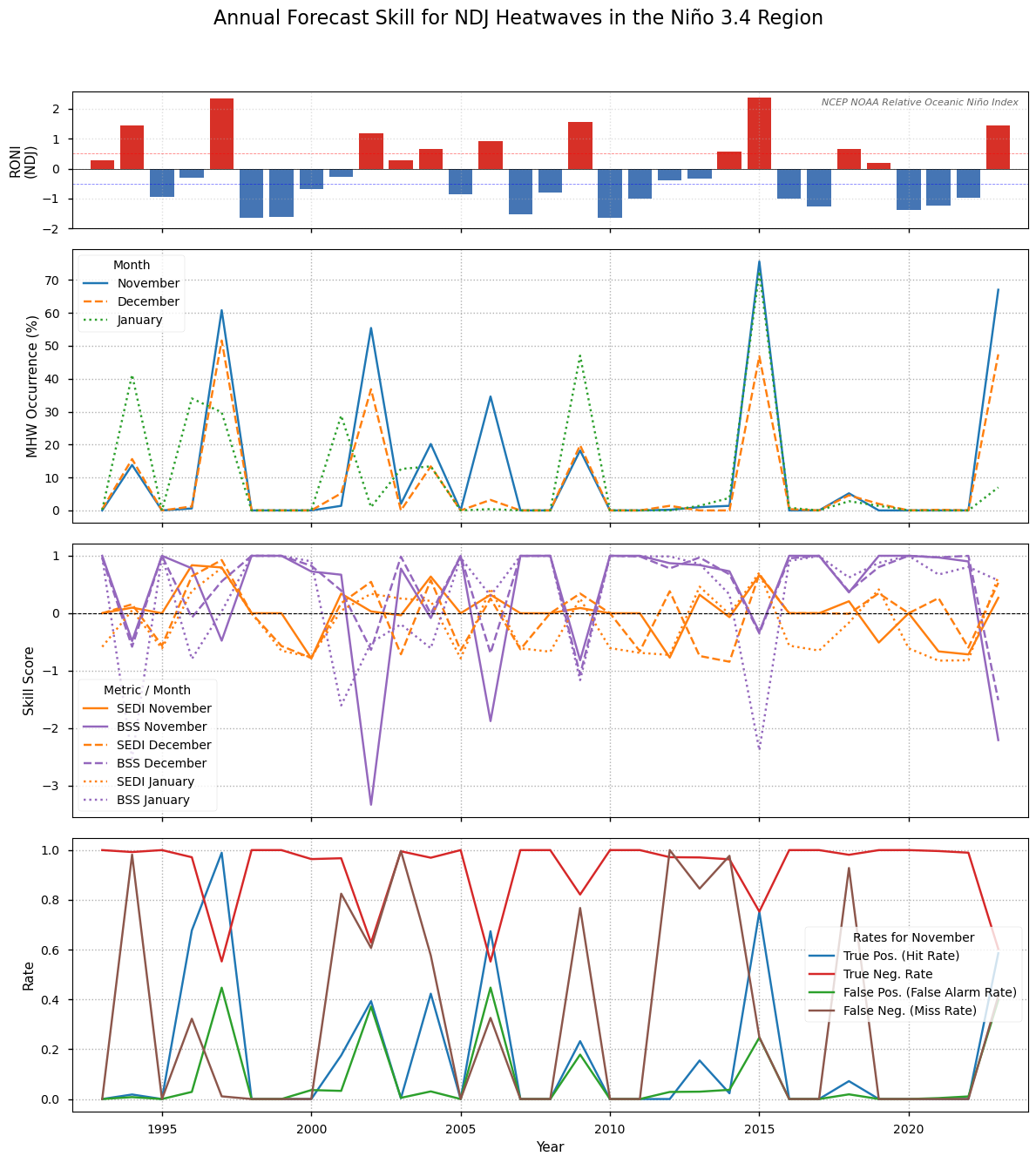
Figure 9#
As in Figure 8, but for the Niño 3.4 region.
In contrast, the skill within the Niño 3.4 region (Figure 9) is much higher and more reliable. Although the time-series exhibits higher variability, which is expected a dynamic and smaller region, the BSS is consistently positive, approaching 1.0 during the major 1997-98 and 2015-16 events. The high SEDI scores further confirm the model’s ability to capture these extremes. This confirms that the probabilistic forecasts are both skillful and reliable regarding marine heatwaves during ENSO events, which are the primary driver of seasonal predictability.
Summary of Results#
This study compares the Météo-France System-9 seasonal forecasts against the ORAS5 ocean reanalysis for forecasts initialized around October 1st for mean monthly values in November, December, and January. The analysis focused on the forecast skill for extreme upper OHC events (anomalies >90th percentile) after removing long-term trends from both datasets. By looking at anomalies, detrending the data, and applying lead-time (or calendar month) dependent percentiles we do our best to match the seasonal data with the reference data. We assess skill 1–3 months after the forecasts nominal start date using metrics such as the Symmetric Extremal Dependence Index (SEDI) and the Brier Skill Score (BSS). The metrics considered follow Jacox et al. (2022) [1], however, in this work we look at OHC and not SST. It should be noted that this evaluation and use-case considers a single ocean reanalysis as a reference dataset. Using an ensemble of observational datasets could provide a more robust assessment.
The forecast system demonstrates clear, positive skill in detecting events. The Symmetric Extremal Dependence Index (SEDI) is positive globally and spikes during major El Niño events (e.g., 1997-98, 2015-16). This is corroborated by the contingency rate analysis (Figure 8 lower panel), which shows the True Positive (Hit) Rate increasing dramatically in these years, confirming the model successfully captures the El Niño signal, and the corresponding effect on the MHW index derived from the ocean heat content.
The system provides a valuable tool for anticipation of NDJ upper ocean heatwaves, with its utility and reliability being highest in ENSO-dominated regions. However, outside this region the Brier Skill Score (BSS) is often negative, indicating that the forecast probabilities are less reliable than the static climatological reference forecast (always a 10% chance). This might indicate that the model has too little ensemble spread in these regions. This makes the forecast a good “heads-up” warning for high-risk periods, but for higher reliability outside the main ENSO regions a multi-model system might be useful.
ℹ️ If you want to know more#
Key resources#
Seasonal forecast monthly averages of ocean variables DOI: 10.24381/cds.2f9be611
ORAS5 global ocean reanalysis monthly data from 1958 to present DOI: 10.24381/cds.67e8eeb7
Code libraries used:
C3S EQC custom functions,
c3s_eqc_automatic_quality_control, prepared and advised on by B-Openxesmf
ocean-regrid
make_cornersto provide cell edge coordinates for the ORCA025 tripolar gridxskillscore
dask
xarray
pandas
matplotlib
seaborn
scipy
numpy
cartopy
References#
[1] Jacox, M. G., Alexander, M. A., Amaya, D., Becker, E., Bograd, S. J., Brodie, S., Hazen, E. L., Pozo Buil, M., & Tommasi, D. (2022). Global seasonal forecasts of marine heatwaves. Nature, 604(7906), 486–490.
[2] McAdam, R., Masina, S., Balmaseda, M., Gualdi, S., Senan, R., & Mayer, M. (2022). Seasonal forecast skill of upper-ocean heat content in coupled high-resolution systems. Climate Dynamics, 58(11–12), 3335–3350.
[3] Specq, D., Dorel, L., Beuvier, J., Ardilouze, C., & Batté, L. (2024). Documentation of the Météo-France seasonal forecasting system 9. Zenodo.
[4] Ferro, C. A. T., & Stephenson, D. B. (2011). Extremal Dependence Indices: Improved Verification Measures for Deterministic Forecasts of Rare Binary Events. Weather and Forecasting, 26(5), 699–713.