

1.5.4. Satellite soil moisture for drought monitoring in Europe (2023 case study)#
Production date: 03-04-2026
Produced by: Amaya Camila Trigoso Barrientos (VUB)
🌍 Use case: Supporting monitoring of drought conditions across Europe during the growing season to inform agricultural risk management and climate impact assessments.#
❓ Quality assessment question(s)#
Is satellite-derived soil moisture data sufficiently complete, consistent, and temporally representative to reliably detect and monitor anomalies in drought conditions at continental and regional scales?
This assessment evaluates the suitability of satellite-derived soil moisture data for drought monitoring in Europe, with a specific focus on data completeness in the context of anomaly-based analysis. Completeness is assessed in terms of the availability of valid observations required to construct a 30-year climatological baseline (1991–2020) and to support dekadal (10-day) anomaly calculations. The analysis does not aim to provide a comprehensive evaluation of all quality dimensions, but rather to examine whether the dataset provides sufficient temporal and spatial support for this specific use case. In this context, completeness is considered a critical factor influencing the reliability of standardized soil moisture anomalies (SSMA), particularly given the uneven temporal distribution of observations across the record. The objective of this assessment is to determine to what extent the dataset provides adequate baseline support to reliably detect and monitor drought conditions at continental and regional scales, using the 2023 European drought as a case study.
📢 Quality assessment statement#
These are the key outcomes of this assessment
The dataset provides adequate spatial and temporal consistency to capture the main large-scale drought patterns across Europe during the 2023 growing season.
Data completeness varies significantly across regions and seasons, with lower availability in areas affected by snow cover, complex terrain, and dense vegetation.
Applying stricter baseline completeness thresholds improves the reliability of anomaly estimates but reduces spatial coverage, particularly in regions with historically sparse observations.
The dataset is suitable for qualitative drought monitoring and regional-scale analysis, but limitations in baseline representativeness and surface sensitivity should be considered for quantitative applications.
📋 Methodology#
The C3S COMBINED satellite soil moisture dataset was downloaded for the period 1991–2023 and spatially subsetted to Europe. The analysis focuses on the volumetric surface soil moisture variable aggregated at dekadal (10-day) resolution. A land mask based on European boundaries was applied to exclude ocean pixels from all analyses.
To assess the suitability of the dataset for anomaly-based drought monitoring, completeness was evaluated in terms of the availability of valid observations required to construct a 30-year climatological baseline (1991–2020). The number of valid years per pixel and dekad was quantified, and different completeness thresholds were applied (no threshold, ≥50%, ≥70%) to evaluate their impact on anomaly calculations.
SSMA for 2023 were computed at the dekadal scale using the baseline mean and standard deviation for each pixel and day-of-year. The analysis focuses on the March–August period to capture the onset, development, and peak of the 2023 European drought.
Spatial maps were generated for selected dekads to compare anomaly patterns under different completeness thresholds, and predefined regions were used to analyse regional behaviour. For each region, the distribution of SSMA across land pixels was summarized using the median and interquartile range (IQR), and data completeness was quantified as the percentage of valid pixels contributing to each dekad.
The methodology is designed to evaluate how data availability influences the reliability of anomaly-based drought indicators, rather than to provide a full validation against reference datasets.
Import packages
Define dataset request and parameters
Download and transform soil moisture data
Spatially subset to Europe
Apply land mask to exclude ocean pixels
2. Baseline completeness assessment
Compute number of valid years per pixel and dekad (1991–2020)
Visualize spatial distribution of baseline support
Analyse completeness patterns across regions and seasons
Identify areas with limited baseline representativeness
3. Temporal completeness analysis
Evaluate completeness across years and dekads (1991–2023)
Analyse seasonal and interannual variability in data availability
Relate completeness patterns to known limitations
4. SSMA computation under different thresholds
Compute climatological mean and standard deviation per dekad
Apply completeness thresholds (no threshold, ≥50%, ≥70%)
Calculate standardized soil moisture anomalies (SSMA) for 2023
Mask pixels not meeting threshold criteria
5. Spatial analysis of anomalies
Generate maps of SSMA for selected dekads (April–July 3rd dekads)
Compare spatial patterns across thresholds
Relate patterns to drought evolution reported in literature
Define regions of interest
Compute median SSMA and IQR over land pixels
Quantify completeness (% valid pixels) per dekad
Compare temporal evolution across thresholds
Interpret results in the context of drought development
📈 Analysis and results#
1. Request and download data#
Import packages#
Set the data request#
Download data#
Administrative boundaries were obtained from the Eurostat GISCO database, ensuring consistency with official European statistical geographies [1].
Spatially subset to Europe#
2. Baseline completeness assessment#
To assess whether the dataset provides sufficient baseline support for computing standardized soil moisture anomalies (SSMA), the number of valid years available for each pixel and dekad was quantified over the 1991–2020 reference period, which corresponds to the standard 30-year climatological baseline recommended by the World Meteorological Organization (WMO)[2]. The most recent years (2021–2022) were not included to ensure consistency with established climatological reference periods and to avoid mixing the baseline with the period of analysis. In addition, recent years—particularly 2022—were characterized by pronounced drought conditions in Europe [3]; including such anomalous years in the baseline could bias the climatological mean and standard deviation, thereby reducing the sensitivity of the anomaly calculation.
The soil moisture time series was first subset to the baseline period and grouped by dekad of the year (36 dekads per year). For each dekad and pixel, the number of years containing a valid soil moisture value was counted. This results in a spatially explicit estimate of baseline sample size, ranging from 0 to 30 years, which represents the number of observations available to compute the climatological mean and standard deviation for that dekad. The resulting maps show the distribution of baseline support across selected dekads of the year.
This analysis is performed to evaluate whether the available baseline data are sufficient to support robust anomaly calculations. Although the dataset is provided as dekadal aggregates, the effective sample size underlying the climatology can vary substantially across space and time. In some regions and dekads, only a limited number of valid years are available, which may reduce the reliability of the derived anomalies. Therefore, assessing baseline support is a useful step to interpret the SSMA results within the scope of this drought monitoring use case.
This assessment focuses on the availability of valid dekadal values across years, rather than the number of daily observations contributing to each dekadal aggregate, as the anomaly calculation depends primarily on the robustness of the baseline climatology.
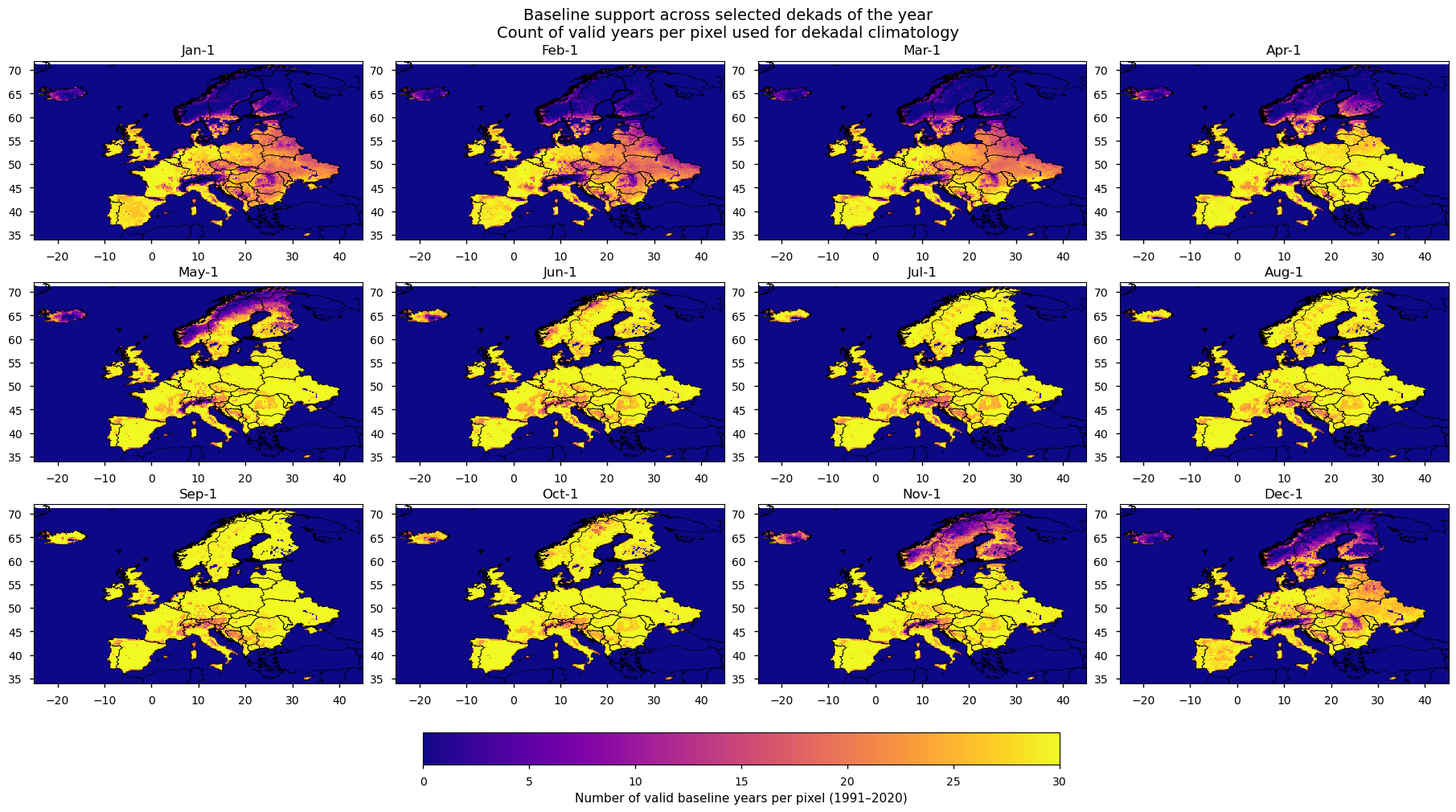
Figure 1. Number of valid baseline years per pixel (1991–2020) for selected dekads of the year.
3. Temporal completeness analysis#
Completeness was calculated for each year–dekad combination between 1991 and 2023 as the percentage of valid land pixels within the study domain. A land mask derived from the European land geometry was applied so that only inland pixels were included. The resulting heatmap shows how data availability changes through both the seasonal cycle and the observational record, and helps identify whether low completeness is concentrated in specific years or dekads.
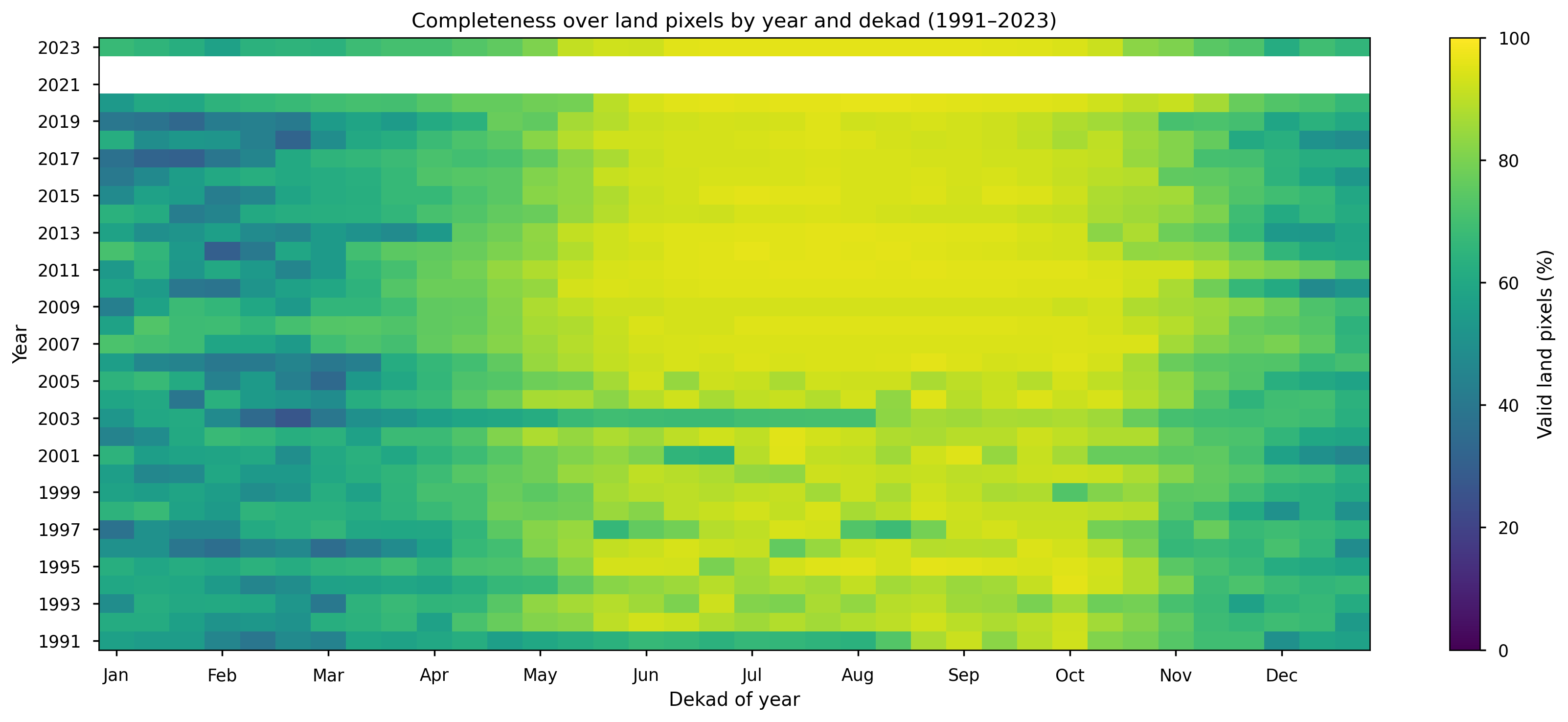
Figure 2. Heatmap of completeness over European land pixels by year and dekad (1991–2023), expressed as the percentage of valid observations.
The results presented in Figures 1 and 2 are consistent with the spatial and temporal completeness assessment described in the Product Quality Assessment Report (PQAR).
Figure 1 shows that completeness is lower in regions affected by seasonal soil moisture freeze–thaw processes, particularly at higher latitudes and during the winter season. Reduced completeness is also observed in mountainous areas, as well as in some urban regions (e.g. around London), which may be influenced by radio-frequency interference (RFI).
Figure 2 indicates a clear seasonal signal, with generally higher completeness across Europe (approximately between 35°N and 70°N) during the May–September period. It can also be observed that completeness during the spring–summer months is lower in earlier years of the record, particularly prior to 2007. This is consistent with Figure 4 of the PQAR, which highlights that the addition of AMSR-E (from 2002) and ASCAT (from 2007) significantly improved spatial coverage. This improvement is reflected in Figure 2, where a noticeable increase in completeness is observed following the introduction of ASCAT in 2007.
4. SSMA computation under different thresholds#
The SSMA was calculated following a similar approach as the one explained by the European Drought Observatory (EDO) [4]. Surface soil moisture values for each pixel and each dekad of the year 2023 were compared to the long-term climatological period (1991–2020, 30 years). The anomaly was computed using the following equation:
\(\text{SMA} = \frac{\text{SMI}_t - \overline{\text{SMI}}}{\delta_{\text{SMI}}}\)
where:
\(\text{SMI}_t\) = Surface soil moisture 2023 for a specific dekad for that pixel
\(\overline{\text{SMI}}\) = Mean surface soil moisture 1991-2020 for that same dekad for that pixel
\(\delta_{\text{SMI}}\) = Standard deviation surface soil moisture 1991-2020 for that same dekad for that pixel
Furthermore, based on the completeness analysis presented in the previous section, a minimum baseline-availability threshold was introduced in the SSMA calculation. For each pixel and each dekad, the number of years within the 1991–2020 baseline period containing a valid soil moisture value was counted. A threshold was then applied requiring that a minimum fraction of these 30 years be available in order to compute the climatological mean and standard deviation.
Specifically, thresholds of 50% and 70% were tested, corresponding to at least 15 and 21 valid years, respectively, for a given pixel–dekad combination. If the number of valid years did not meet the selected threshold, the anomaly for that pixel and dekad was masked and not included in the analysis. A no-threshold case was also retained for comparison, where anomalies are computed regardless of baseline availability.
The threshold is applied at the dekadal level across years and does not account for the number of daily observations contributing to each dekadal aggregate. This is consistent with common practice in drought monitoring applications, where anomalies are typically computed from dekadal products, as also adopted in Joint Research Centre (JRC) Global Drought Observatory (GDO) analyses [3] [5] [6]. Given the focus of this use case on dekadal-scale drought conditions, this approach was considered appropriate.
5. Spatial analysis of anomalies#
To support the interpretation of the SSMA results, spatial maps were generated for the third dekad of April, May, June, and July 2023. These four dekads were selected to enable direct comparison with the corresponding multi-panel figure presented in the JRC August 2023 drought report [6], which shows the evolution of soil moisture anomaly conditions during late spring and early summer. The standardized anomalies were mapped over Europe using a consistent color scale, and predefined regions of interest were delineated to guide the subsequent regional analysis. The same figure layout was produced for different baseline-availability thresholds in order to visually compare their effect on the spatial patterns of the anomalies.
The comparison with JRC drought products should be interpreted as a qualitative assessment of pattern consistency rather than a strict validation. The C3S COMBINED dataset represents surface soil moisture, while the JRC Soil Moisture Anomaly is derived from LISFLOOD simulations of root-zone soil moisture [4]. These differences in depth and methodology imply distinct temporal responses and spatial characteristics, and therefore some discrepancies are expected.
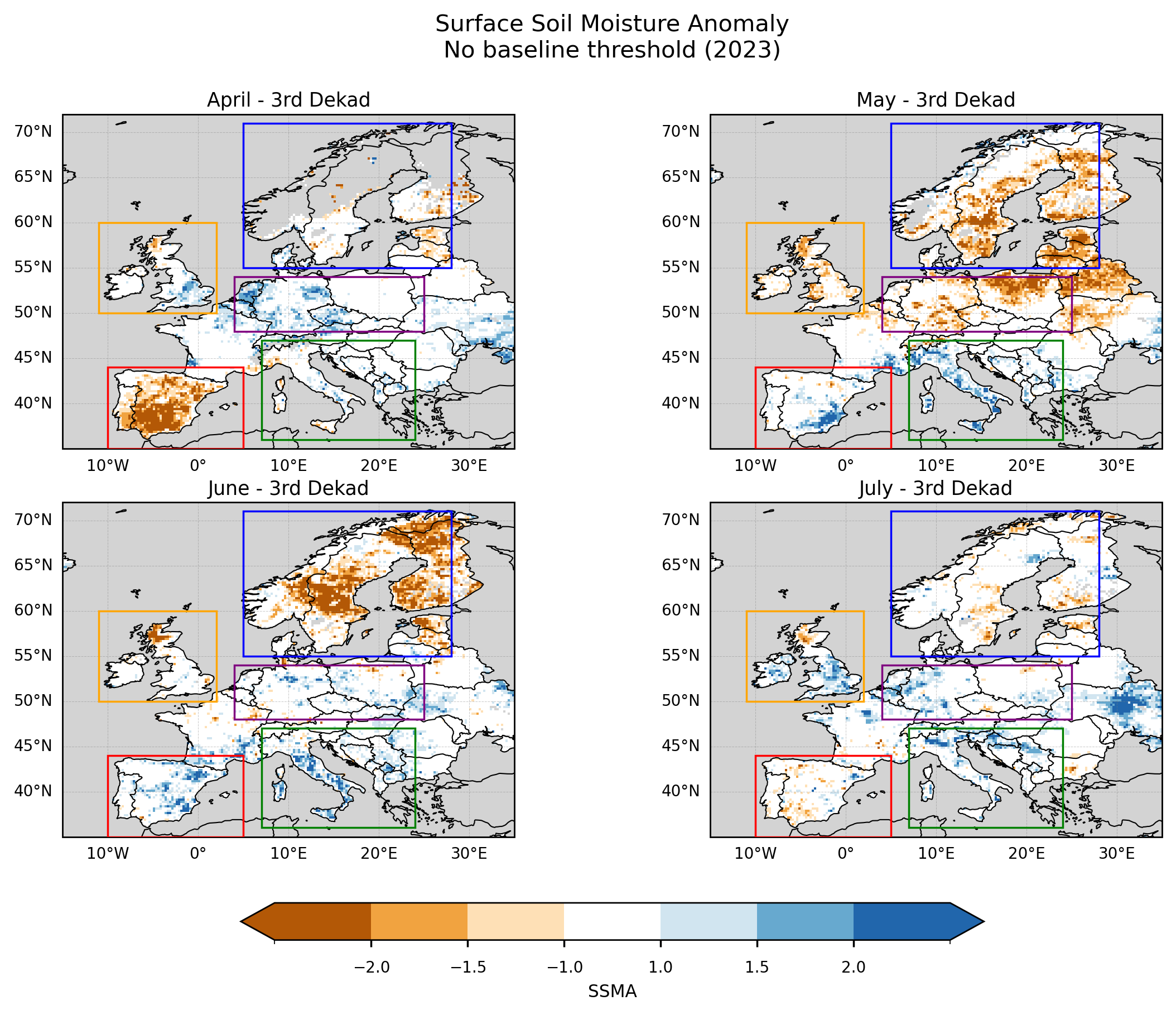
Figure 3. SSMA over Europe for the third dekad of April, May, June, and July 2023. Anomalies are computed without applying a baseline completeness threshold. Boxes indicate the regions selected for subsequent regional analysis.
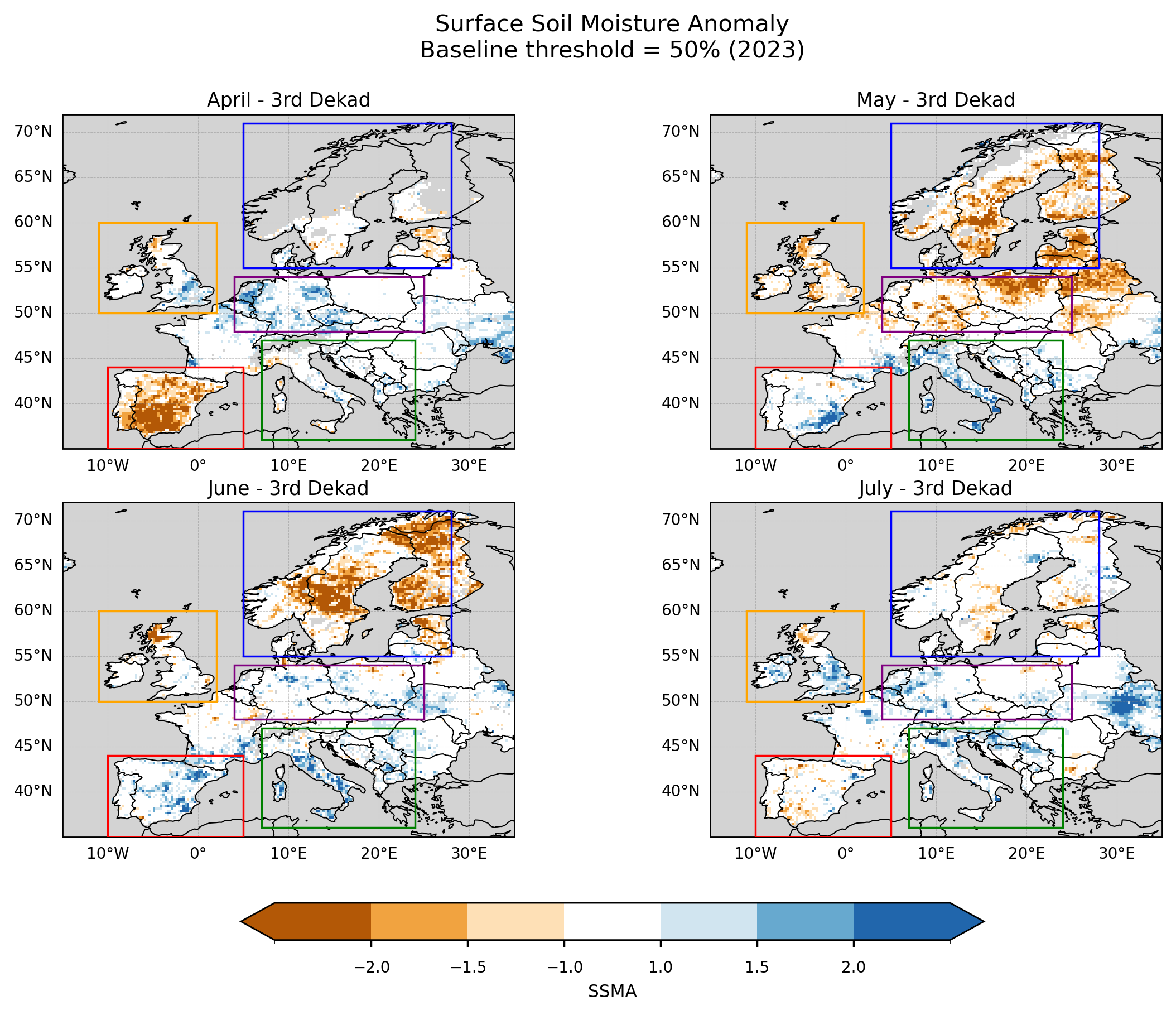
Figure 4. SSMA over Europe for the third dekad of April, May, June, and July 2023. Anomalies are computed using a baseline completeness threshold of ≥50%. Boxes indicate the regions selected for subsequent regional analysis.
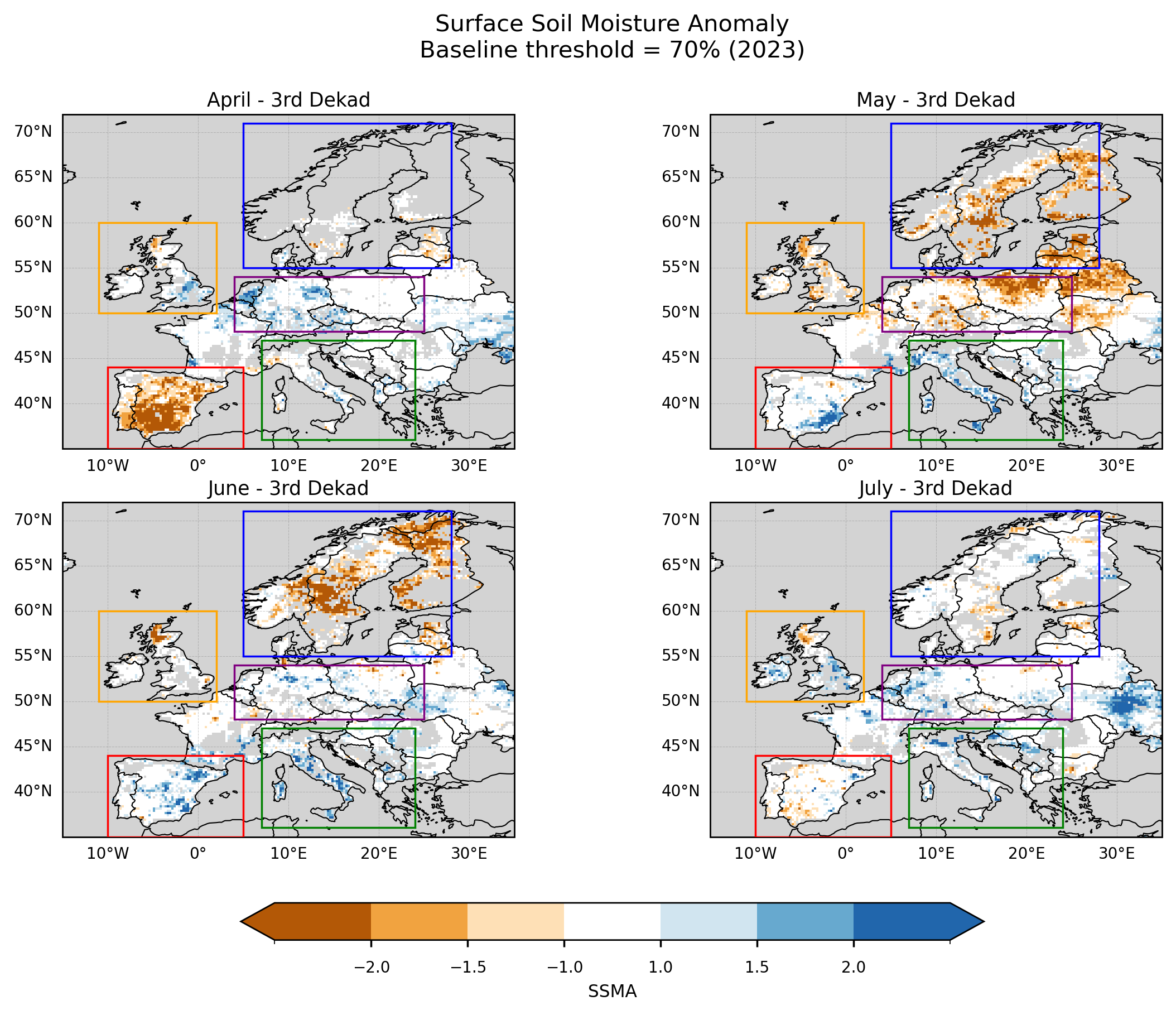
Figure 5. SSMA over Europe for the third dekad of April, May, June, and July 2023. Anomalies are computed using a baseline completeness threshold of ≥70%. Boxes indicate the regions selected for subsequent regional analysis.
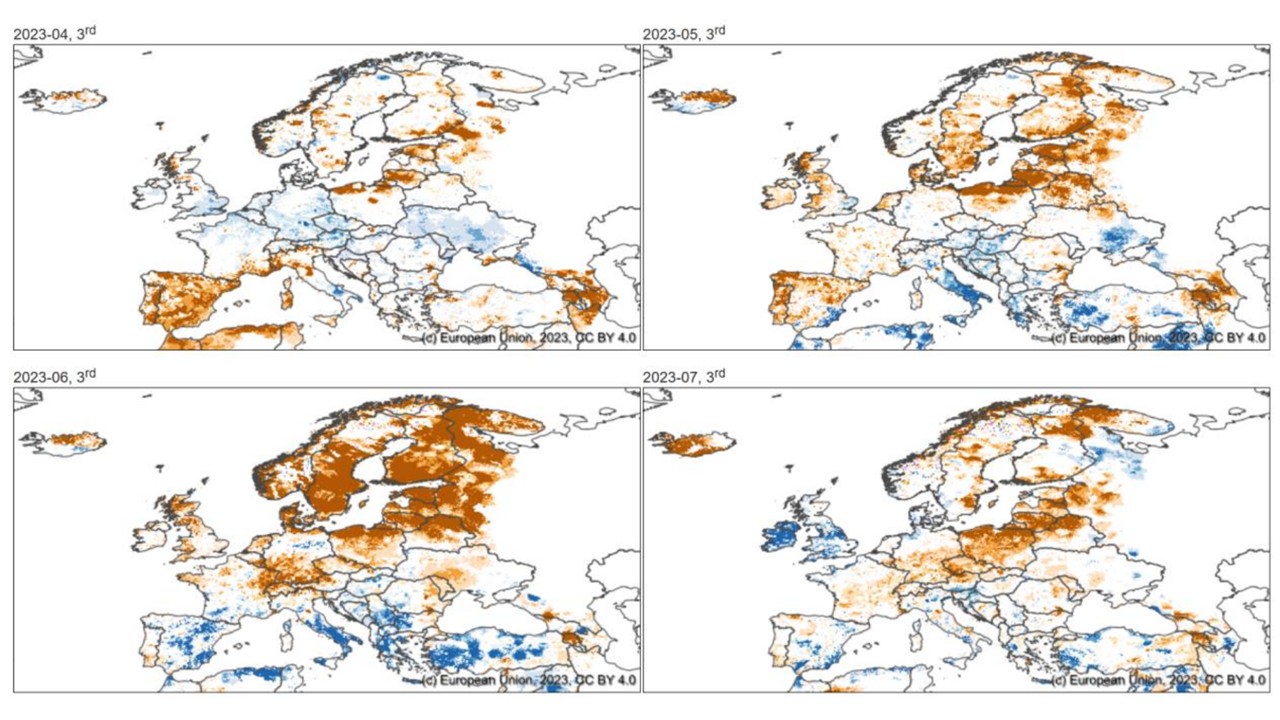
Figure 6. Soil Moisture Anomaly from April to July 2023. Extracted from: JRC (2023)[6]
The application of a baseline completeness threshold has a clear impact on the spatial coverage of the SSMA maps. Under the ≥70% threshold, missing values become more prominent in regions where long-term data availability is limited, particularly in areas with complex terrain such as the Pyrenees, Alps, Apennines, Dinaric Alps, Balkan Mountains, and Carpathians. Reduced coverage is also observed in parts of northern Spain and southern UK, potentially reflecting a combination of retrieval limitations over heterogeneous terrain and urban areas.
Compared to the no-threshold and ≥50% cases, the ≥70% threshold leads to a noticeable reduction in spatial coverage over southern and southeastern Europe, especially across Italy and the Balkans. In these regions, areas that appear as neutral or positive anomalies in the lower-threshold cases are masked out when stricter baseline requirements are applied. This highlights the sensitivity of the spatial patterns to baseline data availability.
Despite these differences, several large-scale features remain consistent with the patterns reported in the JRC drought analyses. In particular, persistent negative anomalies are observed across Scandinavia, and a transition towards more neutral or slightly positive anomalies is visible over parts of the British Isles in late July. This suggests that, even with reduced baseline support in some regions, the main spatial signals are broadly captured.
The largest discrepancies with respect to the JRC results are observed over central-western Europe (e.g. Benelux, Germany, and surrounding areas), where the satellite-based anomalies show weaker or more spatially fragmented drought signals. These differences may reflect both the sensitivity of surface soil moisture to short-term variability and the impact of data completeness on the anomaly calculation.
6. Regional SSMA analysis#
The following section computes and visualizes regional SSMA statistics for selected European subregions. For each region, SSMA values are spatially subsetted to the corresponding bounding box and restricted to land pixels using a geographic mask. The analysis focuses on the period from March to August 2023, using dekadal time steps.
This period was selected to capture the onset, development, and peak of the 2023 European drought, while maintaining consistency with the temporal coverage of the JRC drought reports, which provide assessments for March [3], June [5], and August [6]. Focusing on this interval allows for a targeted evaluation of the dataset’s ability to represent the main phases of the drought event, while avoiding the inclusion of less relevant periods outside the core drought season.
Within each region and dekad, the distribution of SSMA across all land pixels is summarized using the median and interquartile range (IQR; 25th–75th percentiles), providing a robust representation of central tendency and spatial variability. In parallel, data completeness is quantified as the percentage of valid (non-missing) land pixels contributing to each dekad.
These statistics are computed separately for different baseline completeness thresholds (no threshold, ≥50%, ≥70%) to assess the sensitivity of the SSMA signal to data availability. The resulting time series are displayed as multi-panel figures, allowing direct comparison of SSMA behaviour and completeness across thresholds and regions.
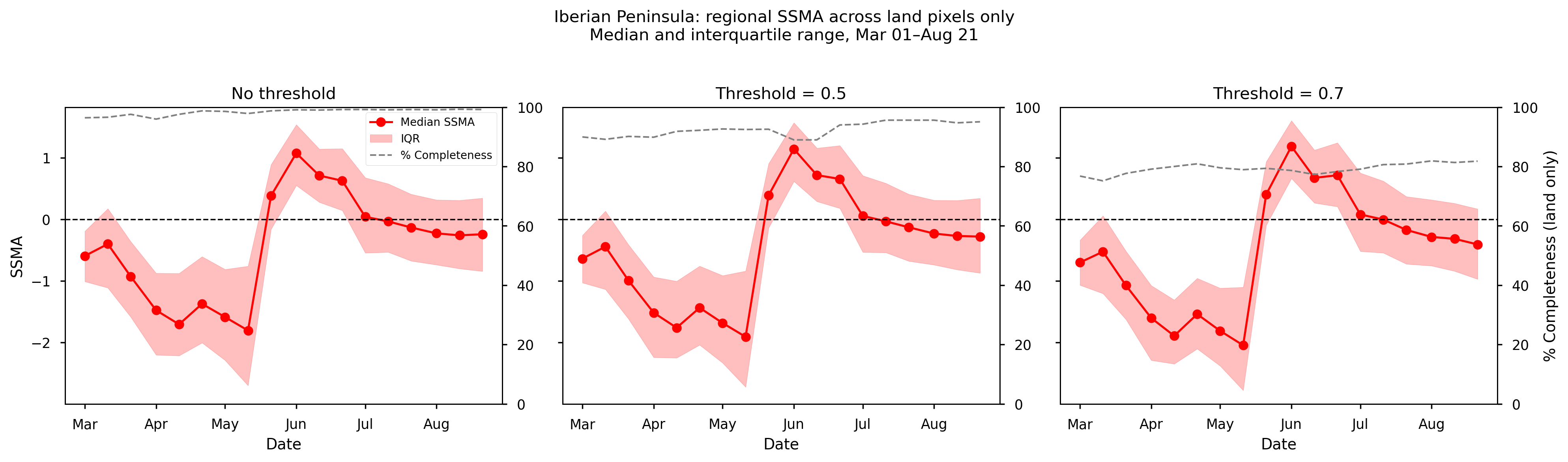
Figure 7. Mean SSMA over the Iberian Peninsula from spring to summer 2023, together with the corresponding data completeness (%). Panels (left to right) show results for different completeness thresholds: no threshold, ≥50%, and ≥70%.
Over the Iberian Peninsula, SSMA shows a clear seasonal evolution, with the most negative values occurring in mid-May, followed by a rapid transition towards positive anomalies in early June and a gradual stabilization towards near-neutral conditions during July and August. This pattern reflects the transition from peak drought conditions in late spring to partial recovery in early summer.
The temporal evolution of the median SSMA is highly consistent across all completeness thresholds, with only minor differences in magnitude. This indicates that the regional drought signal is robust to the choice of baseline filtering.
Data completeness remains high throughout the period. For the no-threshold and ≥50% cases, completeness exceeds 90% across most dekads, indicating strong spatial support. The ≥70% threshold results in slightly lower completeness (around 80%), but still maintains sufficient coverage to support the analysis.
Overall, the strong agreement across thresholds, combined with high data availability, suggests that the SSMA estimates for the Iberian Peninsula are both stable and well-supported by the underlying data.
This evolution is consistent with the progression of drought conditions reported for the western Mediterranean in spring 2023, followed by partial recovery in early summer [3], [5], [6], [7], [8], and with studies highlighting the role of persistent soil moisture deficits in amplifying the record-breaking spring heatwave in the region [9].
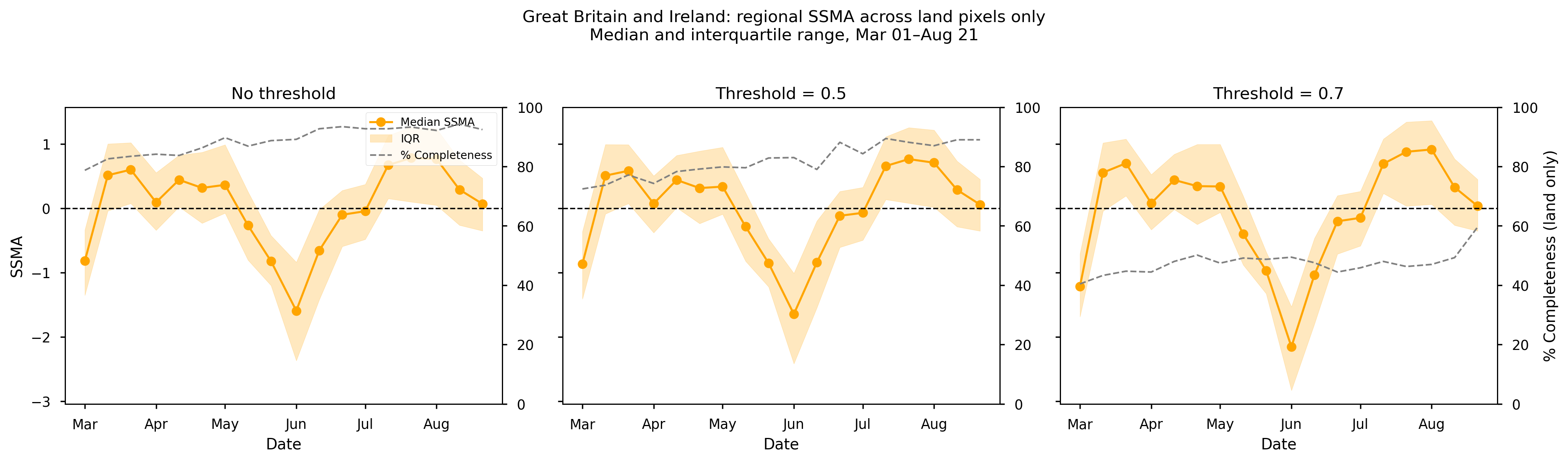
Figure 8. Mean SSMA over Great Britain and Ireland from spring to summer 2023, together with the corresponding data completeness (%). Panels (left to right) show results for different completeness thresholds: no threshold, ≥50%, and ≥70%.
Over Great Britain and Ireland, SSMA exhibits a clear minimum in June, indicating the peak of dry conditions, followed by a gradual recovery towards neutral and slight possitive anomalies conditions in July and August. The magnitude of the negative anomaly is slightly stronger when applying the ≥70% threshold, suggesting that stricter filtering removes pixels with limited baseline support, which can reduce noise and result in slightly stronger anomaly signals.
Data completeness remains high (>80%) for both the no-threshold and ≥50% cases, indicating robust spatial support. In contrast, the ≥70% threshold leads to a substantial reduction in completeness (approximately 40–60%), reflecting limited baseline availability in parts of the region. Despite this reduction, the temporal evolution of SSMA remains consistent across thresholds, indicating that the main drought signal is stable.
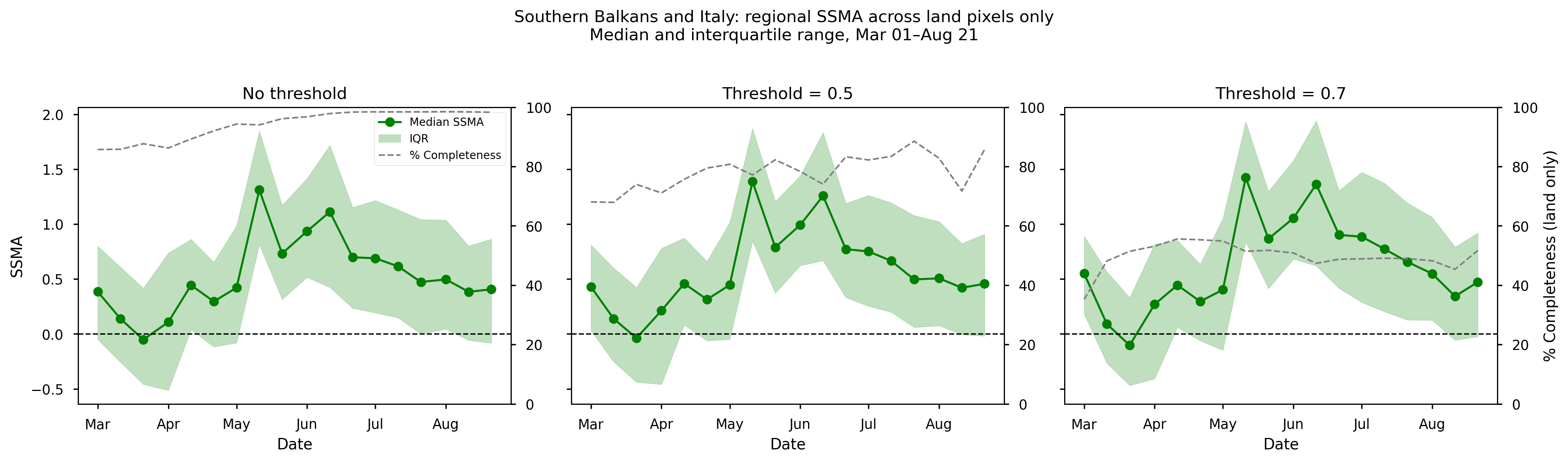
Figure 9. Mean SSMA over the Southern Balkans and Italy from spring to summer 2023, together with the corresponding data completeness (%). Panels (left to right) show results for different completeness thresholds: no threshold, ≥50%, and ≥70%.
In the Southern Balkans and Italy, SSMA is predominantly positive throughout the analysis period, with peaks in mid-May and mid-June. This behaviour contrasts with drought-affected regions and is consistent with spatial patterns observed in the maps. This positive anomaly is consistent with reported rainfall surpluses in May and June over Italy, as well as parts of Slovakia, Hungary, Croatia, and Slovenia, which led to waterlogging of soils and increased pest pressure on crops [10].
Completeness shows a stronger dependence on the applied threshold. While the no-threshold case increases from ~80% to near-complete coverage over time, the ≥50% threshold introduces moderate variability around ~80%. The ≥70% threshold results in lower and more stable completeness (approximately 40–60%), with slightly higher values in early spring.
Despite these differences in data availability, the SSMA signal remains largely unchanged across thresholds, indicating that the positive anomaly pattern is robust.
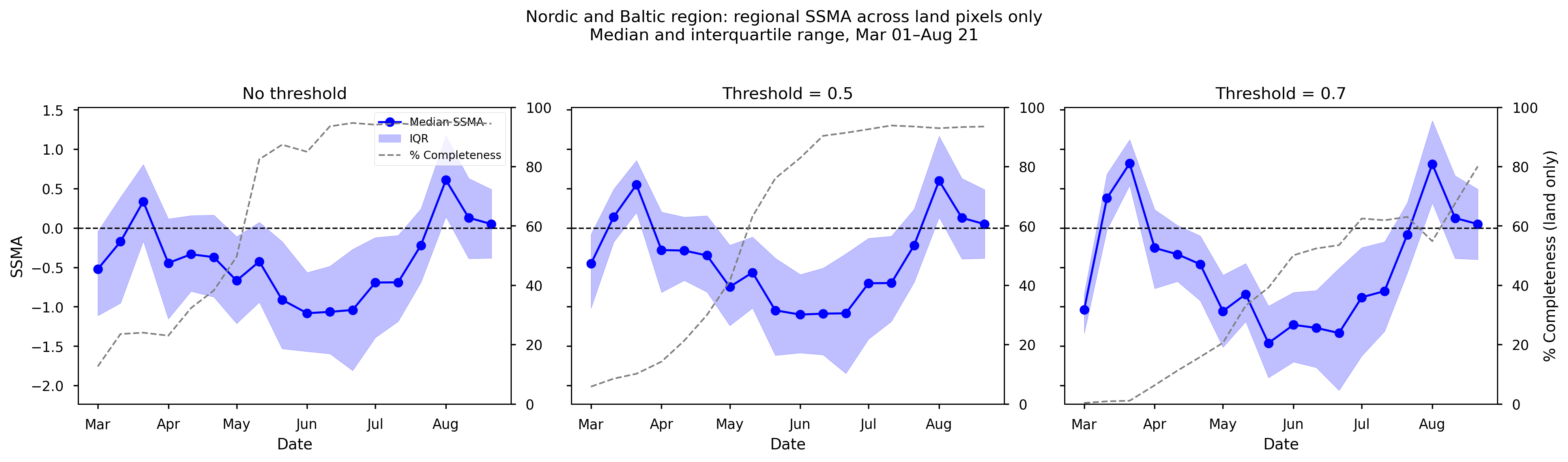
Figure 10. Mean SSMA over the Nordic and Baltic region from spring to summer 2023, together with the corresponding data completeness (%). Panels (left to right) show results for different completeness thresholds: no threshold, ≥50%, and ≥70%.
The Nordic and Baltic region shows a pronounced seasonal evolution, with the lowest SSMA values occurring in June and a transition to slight positive anomalies by early August. The magnitude of negative anomalies is slightly enhanced under the ≥70% threshold.
Completeness exhibits a strong seasonal increase, rising from very low values (<20%) in early spring to high values (>80%) in summer. This pattern is consistent across thresholds, although the ≥70% threshold delays the point at which sufficient coverage is reached (crossing ~60% only in early July). This behaviour reflects known limitations in satellite soil moisture retrievals under snow and frozen soil conditions.
Despite the strong variation in completeness, the temporal SSMA pattern remains consistent across thresholds once sufficient data coverage is achieved.
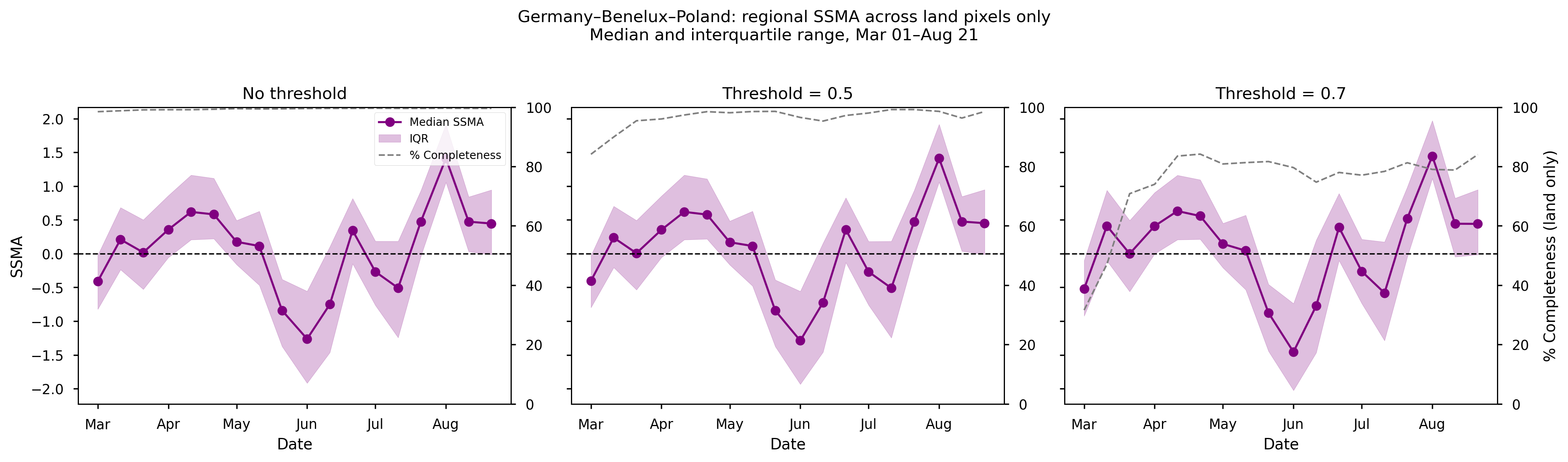
Figure 11. Mean SSMA over the Germany–Benelux–Poland area from spring to summer 2023, together with the corresponding data completeness (%). Panels (left to right) show results for different completeness thresholds: no threshold, ≥50%, and ≥70%.
In the Germany–Benelux–Poland region, SSMA reaches its minimum in early June and transitions to positive anomalies by early August. Compared to other regions, this area shows greater sensitivity to threshold selection, particularly in early spring.
Completeness is near-total (≈100%) in the no-threshold case and remains high (>90%) for the ≥50% threshold. Under the ≥70% threshold, completeness is initially low (~40% in early March) but increases rapidly, stabilizing around ~80% for the remainder of the period.
Across all regions, the median SSMA and its temporal evolution are broadly consistent across the different completeness thresholds, despite substantial differences in data availability. This indicates that the main drought signal is relatively robust to the choice of threshold. However, stricter thresholds (e.g. ≥70%) significantly reduce spatial coverage in several regions, particularly where baseline data availability is limited.
The close agreement between the no-threshold and ≥50% cases indicates that applying a 50% completeness requirement does not materially change the baseline composition. This is likely due to the uneven temporal distribution of valid observations, with a higher density of data in more recent years following the introduction of additional sensors (e.g. AMSR-E and ASCAT). Consequently, the ≥50% threshold effectively selects pixels for which a sufficient number of valid years is already concentrated in the later part of the record, leading to an overrepresentation of recent conditions in the baseline and a reduced contribution from earlier, less complete years.
ℹ️ If you want to know more#
Markonis, Y., Kumar, R., Hanel, M., Rakovec, O., Máca, P., & AghaKouchak, A. (2021). The rise of compound warm-season droughts in Europe. Science Advances, 7(6), eabb9668.
Ministerio para la Transición Ecológica y el Reto Demográfico (2023). El 14,6% del territorio está en emergencia por escasez de agua y el 27,4%, en alerta. Nota de prensa.
Laguardia, G. & Niemeyer, S. (2008). On the comparison between the LISFLOOD modelled and the ERS/SCAT derived soil moisture estimates. Hydrol. Earth Syst. Sci., 12, 1339–1351.
Key resources#
Code libraries used:
C3S EQC custom functions,
c3s_eqc_automatic_quality_control, prepared by B-Open
Dataset documentation:
References#
[1] Eurostat (Accessed on 2016). GISCO. Administrative units.
[2]) World Meteorological Organization. (Accessed on 2016). WMO Climatological Normals.
[3] Toreti, A., Bavera, D., Acosta Navarro, J., Arias Muñoz, C., Avanzi, F., Barbosa, P., de Jager, A., Di Ciollo, C., Ferraris, L., Fioravanti, G., Gabellani, S., Grimaldi, S., Hrast Essenfelder, A., Isabellon, M., Jonas, T., Maetens, W., Magni, D., Masante, D., Mazzeschi, M., McCormick, N., Meroni, M., Rossi, L., Salamon, P., Spinoni, J. (2023). Drought in Europe March 2023. Publications Office of the European Union, Luxembourg, doi:10.2760/998985, JRC133025.
[4] European Commission (2019). EDO INDICATOR FACTSHEET Soil Moisture Anomaly (SMA). European Drought Observatory.
[5] Toreti, A., Bavera, D., Acosta Navarro, J., Arias Muñoz, C., Avanzi, F., Barbosa, P., de Jager, A., Di Ciollo, C., Ferraris, L., Fioravanti, G., Gabellani, S., Grimaldi, S., Hrast Essenfelder, A., Isabellon, M., Jonas, T., Maetens, W., Magni, D., Masante, D., Mazzeschi, M., McCormick, N., Rossi, L., Salamon, P. (2023). Drought in Europe June 2023, Publications Office of the European Union, Luxembourg, doi:10.2760/575433, JRC134492.
[6] Toreti, A., Bavera, D., Acosta Navarro, J., Arias Muñoz, C., Barbosa, P., de Jager, A., Di Ciollo, C., Fioravanti, G., , Grimaldi, S., Hrast Essenfelder, A., Maetens, W., Magni, D., Masante, D., Mazzeschi, M., McCormick, N., Salamon, P. (2023). Drought in Europe - August 2023, Publications Office of the European Union, Luxembourg, doi:10.2760/928418, JRC135032.
[7] European Commission (2023). Severe drought: western Mediterranean faces low river flows and crop yields earlier than ever. European Drought Observatory. The Joint Research Centre: EU Science Hub.
[8] European Commission (2023). Precipitation, relative humidity and soil moisture for May 2023.
[9] Lemus-Canovas, M., Insua-Costa, D., Trigo, R. & Miralles, D. (2024). Record-shattering 2023 Spring heatwave in western Mediterranean amplified by long-term drought. npj Clim Atmos Sci 7, 25.
[10] Baruth, B., Ben Aoun, W., Biavetti, I., Bratu, M., Bussay, A., Cerrani, I., Chemin, Y., Claverie, M., De Palma, P., Fumagalli, D., Manfron, G., Morel, J., Nisini, L., Panarello, L., Rossi, M., Tarnavsky, E., Van Den Berg, M., Zajac, Z. and Zucchini, A., JRC MARS Bulletin - Crop monitoring in Europe - June 2023 - Vol. 31 No 6, Van Den Berg, M., Niemeyer, S. and Baruth, B. editor(s), Publications Office of the European Union, Luxembourg, 2023, doi:10.2760/82821, JRC133186.
[11] NOAA National Centers for Environmental Information (2023). Monthly Climate Reports, Global Drought Narrative, June 2023.